






嗨咯!a ni o~!空妮七挖!大家好久不见呀~今天小Mi继续给大家讲解正则化!
目前深度模型在各种复杂的任务中固然表现十分优秀,但是其架构的学习要求大量数据,对计算能力的要求很高。神经元和参数之间的大量连接需要通过梯度下降及其变体以迭代的方式不断调整。向全局最小值的收敛过程较慢,容易掉入局部极小值的陷阱导致预测结果不好而产生测试数据过拟合等现象。
因此深度学习中的正则化与优化策略一直是非常重要的部分,它们很大程度上决定了模型的泛化与收敛等性能。
原理
训练学习模型的目的不仅仅是可以描述已有的数据,而且是对未知的新数据也可以做出较好的推测,这种推广到新数据的能力称作泛化(generalization)。在训练集上的误差为训练误差(training error),而在新的数据上的误差的期望称为泛化误差(generalization error)或测试误差(test error)。通常我们用测试集上的数据对模型进行测试,将其结果近似为泛化误差。
训练集和测试集是由某种数据生成分布产生的,通常我们假设其满足独立同分布(independent and identically distributed, 简称i.i.d),即每个数据是相互独立的,而训练集和测试集是又从同一个概率分布中取样出来的。
假设参数固定,那么训练误差和测试误差就是一样的。但实际上,我们通过采样训练集选取了一个仅优化训练集的参数,然后再对测试集采样,所以测试误差常常会大于训练误差。
因此学习模型主要需要解决两个问题:
1.减小训练误差。
2.减小训练误差和测试误差间的间距。
那么也就是说这两点分别对应着学习模型的欠拟合(underfitting)和过拟合(overfitting)这两个问题。
PS:欠拟合指模型的训练误差过大,过拟合指训练误差和测试误差间距过大。
模型是欠拟合还是过拟合是由模型的容量(capacity)决定的。低容量由于对训练集描述不足造成欠拟合,高容量由于记忆过多训练集信息而不一定对于测试集适用导致过拟合。比如对于线性回归,它仅适合数据都在一条直线附近的情形,容量较小,为提高容量,我们可以引入多次项,比如二次项,可以描述二次曲线,容量较一次多项式要高。对如下图的数据点,一次式容量偏小造成欠拟合,二次式容量适中拟合较好,而九次式容量偏大造成过拟合。

训练误差,测试误差和模型容量的关系可以由下图表示,在容量较小时我们处在欠拟合区,训练误差和测试误差均较大,随着容量增大,训练误差会逐渐减小,但测试误差与训练误差的间距也会逐渐加大,当模型容量超过最适容量后,测试误差不降反增,进入过拟合区:

因此,控制模型的复杂度不是找到合适规模的模型(带有正确的参数个数),恰恰相反,我们可能会发现,最好的拟合模型(从最小化泛化误差的意义上)是一个适当正则化的大型模型。
参数范数惩罚
许多正则化方法通过对目标函数
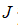
添加一个参数范数惩罚,限制模型(如神经网络)的学习能力。将正则化后的目标函数记为:

其中

是权衡范数惩罚项和标准目标函数相对贡献的超参数。将设为0表示没有正则化;越大,对应正则化惩罚越大。
当我们的训练算法最小化正则化后的目标函数
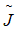
时,它会降低原始目标关于训练数据的误差并同时减小参数的规模(或在某些衡量下参数子集的规模)。
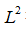
参数正则化
最简单和最常见的参数范数惩罚,即通常被称为权重衰减(weight decay)的

参数范数惩罚。这个正则化策略通过向目标函数添加一个正则项,使权重更加接近**。
为了简单起见,假定其中没有偏置参数,因此
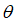
就是。
因此,目标函数为:

对应的梯度为:

使用单步梯度下降更新权重,即执行以下更新:
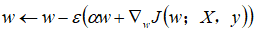
令
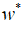
为不含正则化的目标函数取得最小训练误差时的权重向量,即,并在的邻域对目标函数做二次近似。如果目标函数确实是二次的(如以均方误差拟合线性回归模型的情况),则该近似是完美的。近似的如下:

其中H是J在

处计算的Hessian矩阵。因为被定义为最优,即梯度消失为0,所以该二次近似中没有一阶项。同样地,因为是J的一个最优点,可以得出H是半正定的结论。
当
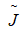
取得最小时,其梯度为0。
现在探讨最小化含有正则化的
。使用变量表示此时的最优点:
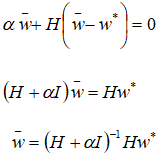
当
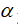
趋向于0时,正则化的解会趋向。那么当增加时会发生什么呢?
因为H是实对称的,所以可以将其分解为一个对角矩阵

和一组特征向量的标准正交基Q,并且有。

可以看到权重衰减的效果是沿着由H的特征向量所定义的轴缩放
。
沿着H特征值较大的方向 (如

)正则化的影响较小。而的分量将会收缩到几乎为零。

只有在显著减小目标函数方向上的参数会保留得相对完好。在无助于目标函数减小的方向(对应 Hessian 矩阵较小的特征值)上改变参数不会显著增加梯度。这种不重要方向对应的分量会在训练过程中因正则化而衰减掉。
目前为止,我们讨论了权重衰减对优化一个抽象通用的二次代价函数的影响。研究线性回归,它的真实代价函数是二次的,因此我们可以使用相同的方法分析。线性回归的代价函数是平方误差之和:

添加
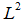
正则项后,目标函数变为
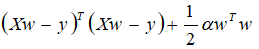
这将普通方程的解从

变为

我们可以看到,

正则化能让学习算法“感知”到具有较高方差的输入x,因此与输出目标的协方差较小(相对增加方差)的特征的权重将会收缩。
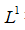
参数正则化
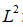
权重衰减是权重衰减最常见的形式,我们还可以使用其他的方法限制模型数的规模。比如使用参数正则化。
对模型参数
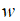
的正则化被定义为:
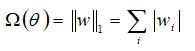
因此,正则化的目标函数
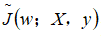
如下(不考虑偏置参数):

对应的梯度:
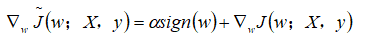
的正则化效果与大不一样。具体来说,正则化对梯度的影响不再是线性地缩放每个;而是添加了一项与同号的常数。使用这种形式的梯度之后,我们不一定能得到二次近似的直接算术解(正则化时可以)。
简单线性模型具有二次代价函数,我们可以通过泰勒级数表示,梯度为:
将
正则化目标函数的二次近似分解成关于参数的求和:
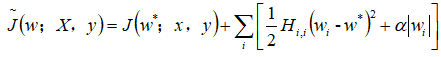
可以最小化近似代价函数:
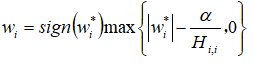
考虑所有

且的情形,会有两种可能:
-
:正则化后目标中的最优值是。在方向上对的贡献受到抑制,正则化项将推向0。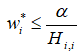
-
:正则化不会将的最优值推向0,而仅仅在那个方向上移动的距离。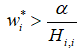

的情况类似,但是惩罚项使更接近0或者为0。
相比
正则化,正则化会产生更稀疏的解(稀疏性:最优值中的一些参数为0)。正则化和正则化的稀疏性具有本质的不同。如果使用Hessian矩阵H为对角正定矩阵的假设,我们发现 。如果不是零,那么也会保持非零。因此正则化不会使参数变得稀疏,而正则化有可能通过足够大的实现稀疏。
所以,目前
正则化导出的稀疏性质已经被广泛地用于特征选择(feature selection)机制——从可用的特征子集选择出有意义的特征,化简问题。
总结
总体来说,参数范数惩罚
正则化能让深度学习算法“感知”到具有较高方差的输入,因此与输出目标的协方差较小(相对增加方差)的特征权重将会收缩。而正则化会因为在方向上对的贡献被抵消而使的值变为0。此外,参数的范数正则化也可以作为约束条件。对于范数来说,权重会被约束在一个范数的球体中,而对于范数,权重将被限制在所确定的范围内。
EMMM,深度学习确实有点难度啦,不然怎么叫深度学习呢,小Mi也自己学习了好久,我们一起加油呀!可不能半途而废哦~下周给大家介绍别的优化策略,敬请期待哦~
















 2222
2222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









