







一.概念
t-SNE(t分布随机邻域嵌入)是一种用于探索高维数据的非线性降维算法。它将多维数据映射到适合于人类观察的两个或多个维度。
t-SNE主要包括两个步骤:第一、t-SNE构建一个高维对象之间的概率分布,使得相似的对象有更高的概率被选择,而不相似的对象有较低的概率被选择。第二,t-SNE在低维空间里在构建这些点的概率分布,使得这两个概率分布之间尽可能的相似(这里使用KL散度(Kullback–Leibler divergence)来度量两个分布之间的相似性)。
二.算法
step1:随机邻接嵌入(SNE)通过将数据点之间的高维欧几里得距离转换为表示相似性的条件概率而开始,数据点xi、xj之间的条件概率pj|i由下式给出:
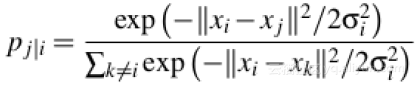
其中σi是以数据点xi为中心的高斯方差。
step2:对于高维数据点xi和xj的低维对应点yi和yj而言,可以计算类似的条件概率qj|i
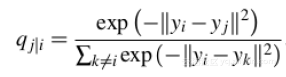
SNE试图最小化条件概率的差异。
step3:为了测量条件概率差的和最小值,SNE使用梯度下降法最小化KL距离。而SNE的代价函数关注于映射中数据的局部结构,优化该函数是非常困难的,而t-SNE采用重尾分布,以减轻拥挤问题和SNE的优化问题。
step4:定义困惑度
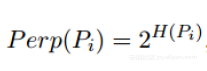
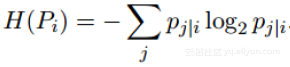
算法计算对应的是条件概率,并试图最小化较高和较低维度的概率差之和,这涉及大量的计算,对系统资源要求高。t-SNE的复杂度随着数据点数量有着时间和空间二次方。
三.sklearn提供的API
与前几个流型降维算法一样,sklearn的manifold提供了t_sne方法TSNE
def __init__(self, n_components=2, perplexity=30.0,
early_exaggeration=12.0, learning_rate=200.0, n_iter=1000,
n_iter_without_progress=300, min_grad_norm=1e-7,
metric="euclidean", init="random", verbose=0,
random_state=None, method='barnes_hut', angle=0.5):
self.n_components = n_components
self.perplexity = perplexity
self.early_exaggeration = early_exaggeration
self.learning_rate = learning_rate
self.n_iter = n_iter
self.n_iter_without_progress = n_iter_without_progress
self.min_grad_norm = min_grad_norm
self.metric = metric
self.init = init
self.verbose = verbose
self.random_state = random_state
self.method = method
self.angle = anglen_components 维度
perplexity 困惑度,最近邻的数目有关。更大的数据集通常需要更大的困惑。考虑选择一个值5到50岁之间。没什么卵用
early_exaggeration 控制原始空间中的自然簇紧凑程度,同样没什么卵用
learning_rate 学习速度,如果学习速度太高,数据看起来像是一个“球”。与最近邻近似等距。如果学习速度太低,大多数点看起来都是压缩的。范围[ 10,1000 ]
n_iter 迭代次数
n_iter_without_progress 无进展时最大迭代次数
min_grad_norm 梯度范数
metric 距离度量,默认欧式
init 初始化方式,据说选pca会比默认random更稳定,我也是颓了
random_state 随机种子
method 梯度计算算法
angle 角度
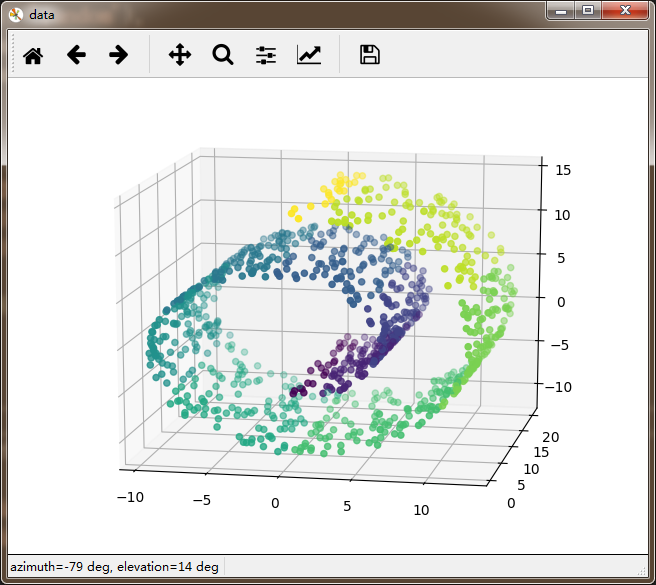
实例:还是以瑞士卷为例
import numpy as np
import operator
import matplotlib.pyplot as plt
from sklearn import datasets,decomposition,manifold
from itertools import cycle
from mpl_toolkits.mplot3d import Axes3D
def load_data():
swiss_roll =datasets.make_swiss_roll(n_samples=1000)
return swiss_roll[0],np.floor(swiss_roll[1])
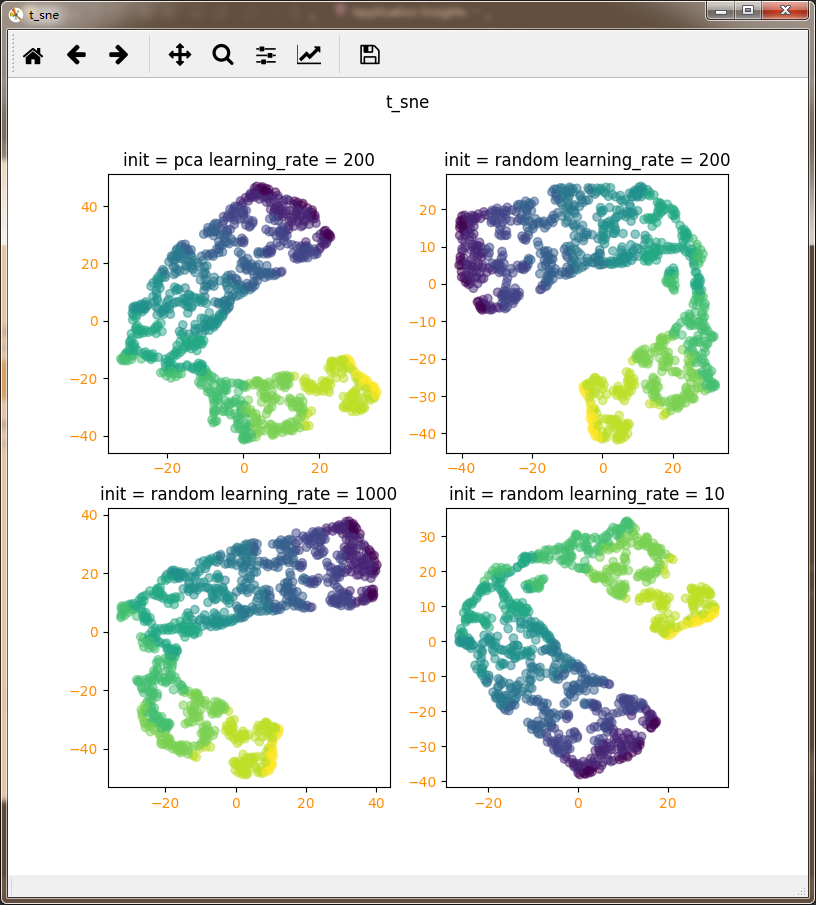
def T_SNE_neighbors(*data):
X,Y=data
TSNE_SET=[
manifold.TSNE(n_components=2,init='pca'),
manifold.TSNE(n_components=2,init='random'),
manifold.TSNE(n_components=2,learning_rate=1000),
manifold.TSNE(n_components=2,learning_rate=10),
]
Name_SET=[
'init = pca learning_rate = 200',
'init = random learning_rate = 200',
'init = random learning_rate = 1000',
'init = random learning_rate = 10',
]
fig=plt.figure("t_sne",figsize=(8, 8))
for i in range(4):
tsne=TSNE_SET[i]
X_r=tsne.fit_transform(X)
ax=fig.add_subplot(2,2,i+1)
ax.scatter(X_r[:,0],X_r[:,1],marker='o',c=Y,alpha=0.5)
ax.set_title(Name_SET[i])
plt.xticks(fontsize=10, color="darkorange")
plt.yticks(fontsize=10, color="darkorange")
plt.suptitle("t_sne")
plt.show()
X,Y=load_data()
fig = plt.figure('data')
ax = Axes3D(fig)
ax.scatter(X[:, 0], X[:, 1], X[:, 2],marker='o',c=Y)
T_SNE_neighbors(X,Y)
四.总结
t-SNE非线性降维算法通过基于具有多个特征的数据点的相似性识别观察到的簇来在数据中找到模式。其本质上是一种降维和可视化技术。另外t-SNE的输出可以作为其他分类算法的输入特征。
大多数情况下,t-SNE比PCA及其他降维算法效果更好,因为算法定义了数据的局部和全局结构之间的软边界。不过美中不足,其运算时间会远大于其他的降维算法。
五.相关学习资源
http://lvdmaaten.github.io/tsne/
http://jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
https://yq.aliyun.com/articles/70733














 847
847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









