







【独家原创】(BO)Bayes-KELM回归(加交叉验证) 1-10折数可调,默认5折 Matlab代码
基于贝叶斯算法(BO/Bayes)优化核极限学习机(KELM)的数据回归预测,可直接运行,适合小白新手
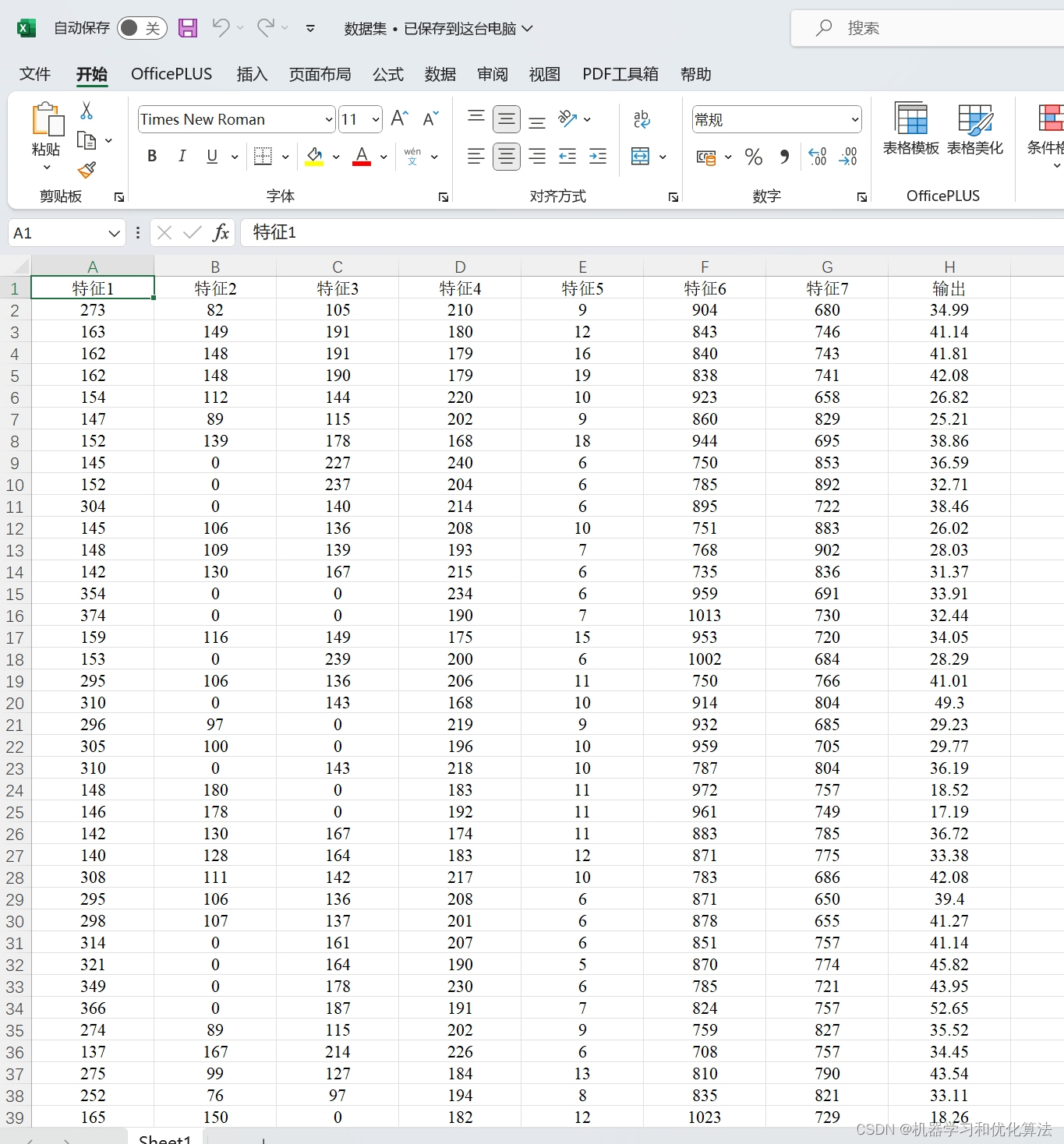
程序已经调试好,无需更改代码替换数据集即可运行!!!数据格式为excel!
KELM也可定制更换为其他模型例如:SVM,RF,RBF,LSSVM,DBN,XGBoost等!
1️⃣、运行环境要求MATLAB版本为2018b及其以上
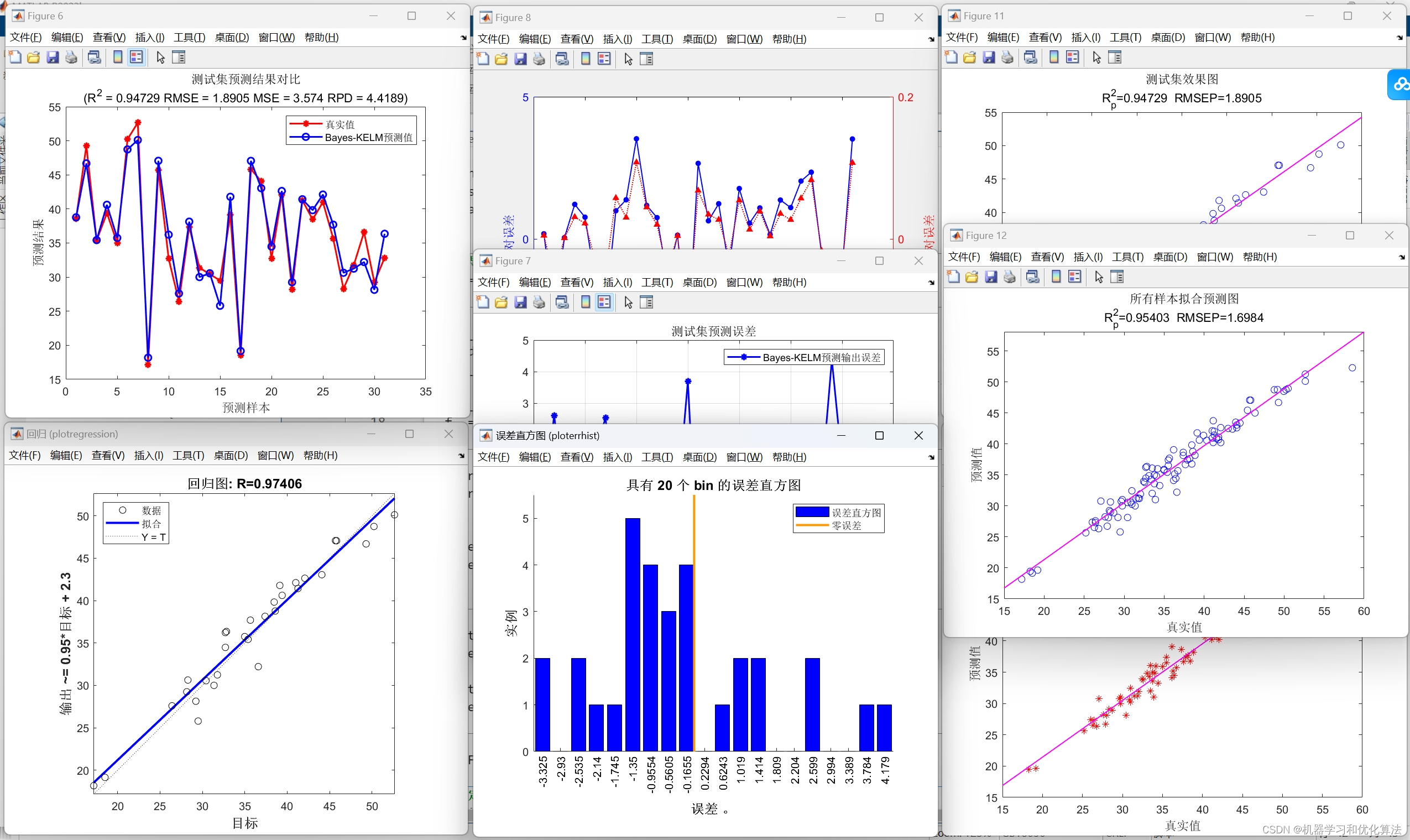
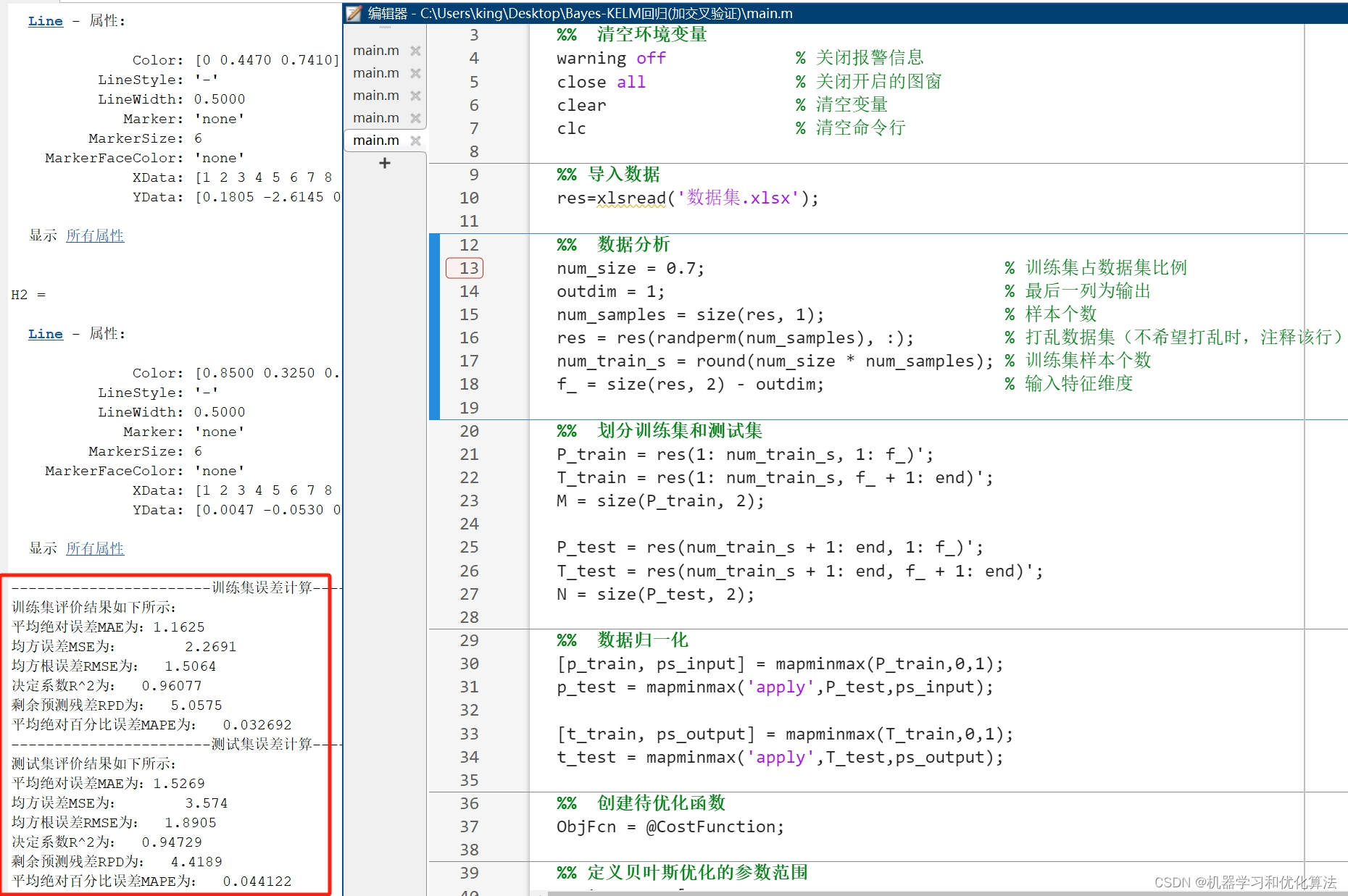
2️⃣、评价指标包括:R2、MAE、MSE、RPD、RMSE等,图很多,符合您的需要
3️⃣、代码中文注释清晰,质量极高
4️⃣、赠送测试数据集,可以直接运行源程序。替换你的数据即可用 适合新手小白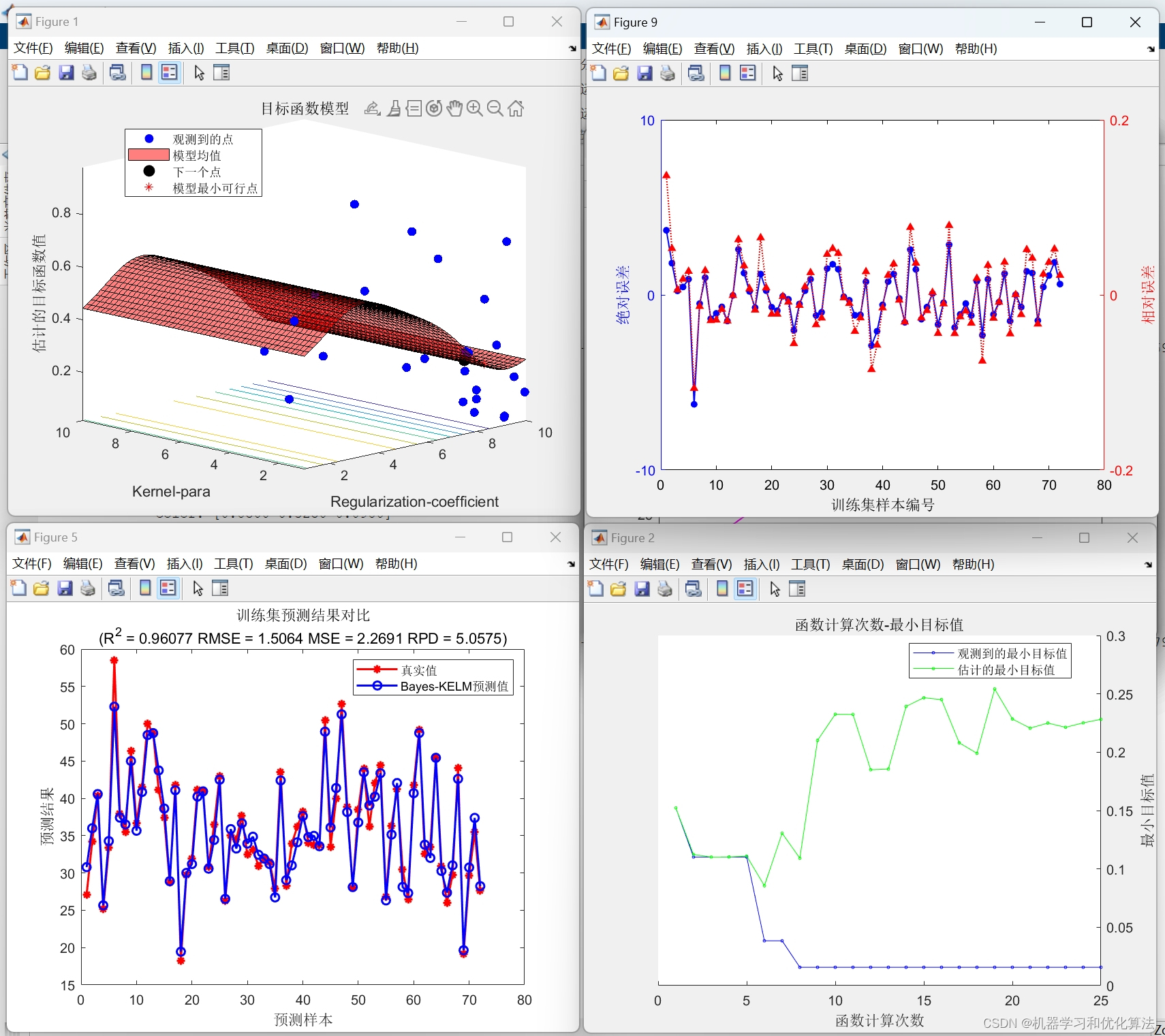















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









