







上次通过爬虫获取了音乐的数据,并把数据导入到hdfs中,根据他的点击量获取前10个音乐,测试了半天现在终于弄好了,分享一下,如有更好的思路请指教。
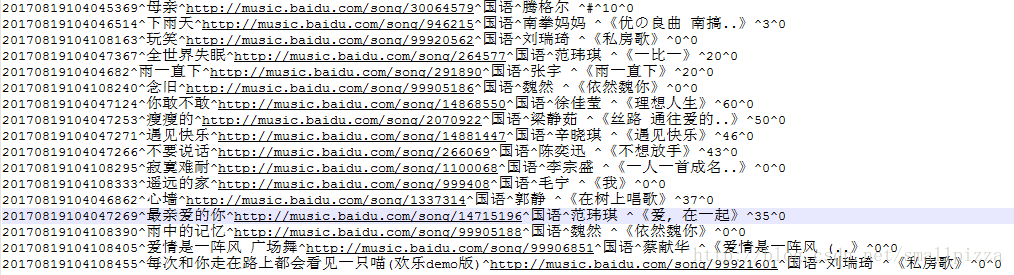
部分原始数据(主要用于测试)如下:
字段名说明:
音乐id^歌曲名^链接^音乐类型^歌手^专辑^点击量^收藏量
代码如下:
import java.io.IOException;
import java.net.URI;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.TreeMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Map 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1741
1741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









