







现有 50 亿个电话号码,如何快速准确判断某 10 万个电话号码是否在这 50 亿中。
如果通过数据库查询实现会非常慢。
如果数据预放在集合中,50 亿 x 8 字节,大概需要 40 GB内存,内存浪费或不够。
如果使用 hyperloglog 存储,可以使用很小的内存判断数据是否在 hyperloglog 里,但是结果会不准确。
类似问题还有很多,例如垃圾邮件过滤、文字处理软件(例如 Word)错误单词检测、网络爬虫重复 url 检测、Hbase 行过滤等。
基于这类问题,就引出了布隆过滤器。
布隆过滤器是 1970 年伯顿.布隆提出,用很小的空间,解决上述类似问题。
1.布隆过滤器原理
实现原理:一个很长的二进制向量和若干个哈希函数。
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:

如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “geeks” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
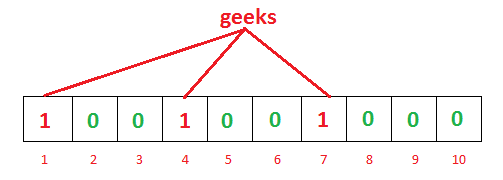
我们现在再存一个值 “nerd”,如果哈希函数返回 3、4、5 的话,图继续变为:
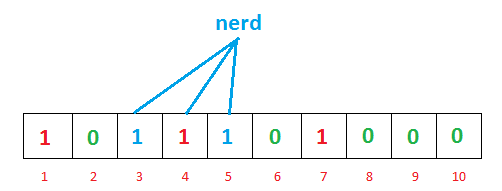
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。
m 个二进制向量,n 个预备数据,k 个 hash 函数。构建布隆过滤器:n 个预备数据走一遍上面过程。判断元素是否存在:走一遍上面过程,如果都是 1,则表明存在,反之不存在。
2.布隆过滤器误差率
误差是肯定存在的,跟 m/n 的比率和 hash 函数的个数有关系,m/n 的比率越大,误差越低,hash 函数的个数越多,误差越低。
1 个元素,1 个 hash 函数,任意一个比特为 1 的概率为
1
/
m
1/m
1/m,依然为 0 的概率为
1
−
(
1
/
m
)
1- (1/m)
1−(1/m);
1 个元素,k 个 hash 函数,依然为 0 的概率为
(
1
−
(
1
/
m
)
)
k
(1- (1/m))^{k}
(1−(1/m))k;
n 个元素,k 个 hash 函数,依然为 0 的概率为
(
1
−
(
1
/
m
)
)
n
k
(1- (1/m))^{nk}
(1−(1/m))nk,被设置为 1 的概率为
1
−
(
1
−
(
1
/
m
)
)
n
k
1 - (1- (1/m))^{nk}
1−(1−(1/m))nk;
新元素全中的概率为
(
1
−
(
1
−
(
1
/
m
)
)
n
k
)
k
(1 - (1- (1/m))^{nk})^{k}
(1−(1−(1/m))nk)k。
3.本地布隆过滤器
现有库:guava。使用方法非常简单:
BloomFilter<Person> friends = BloomFilter.create(personFunnel, 500, 0.01); // 500:希望插入的个数, 0.01:期望的误差率
for(Person friend : friendsList) {
friends.put(friend);
}
// 很久以后
if (friends.mightContain(dude)) {
//dude不是朋友还运行到这里的概率为1%
//在这儿,我们可以在做进一步精确检查的同时触发一些异步加载
}
本地布隆过滤器的问题:
- 容量受限制;
- 多个应用存在多个布隆过滤器,构建同步复杂;
4.Redis单机布隆过滤器
基于位图实现。首先定义布隆过滤器接口:
import java.util.List;
import java.util.Map;
/**
* 布隆过滤器接口
*/
public interface BloomFilter<T> {
/**
* 添加
* @param object
* @return 是否添加成功
*/
boolean add(T object);
/**
* 批量添加
* @param objectList
* @return 是否添加成功
*/
Map<T, Boolean> batchAdd(List<T> objectList);
/**
* 是否包含
* @param object
*/
boolean contains(T object);
/**
* 是否包含
* @param object
*/
Map<T, Boolean> batchContains(List<T> objectList);
/**
* 删除
*/
void clear();
/**
* 预期插入数量
*/
long getExpectedInsertions();
/**
* 预期错误概率
*/
double getFalseProbability();
/**
* 布隆过滤器总长度
*/
long getSize();
/**
* hash函数迭代次数
*/
int getHashIterations();
}
CacheCloud 布隆过滤器实现 BloomFilter 接口,看一下 add 方法的实现:
/**
* CacheCloud 布隆过滤器
*/
public class CacheCloudBloomFilter<T> implements BloomFilter<T> {
private BloomFilterBuilder config;
public CacheCloudBloomFilter(BloomFilterBuilder bloomFilterBuilder) {
this.config = bloomFilterBuilder;
}
@Override
public boolean add(T object) {
if (object == null) {
return false;
}
// 偏移量列表
List<Integer> offsetList = hash(object);
if (offsetList == null || offsetList.isEmpty()) {
return false;
}
String key = genBloomFilterDistributeKey(object);
return setBit(key, new HashSet<Integer>(offsetList));
}
/**
* 生成子布隆过滤器对应的key,使用crc16作为分组
*/
private String genBloomFilterDistributeKey(T object) {
int hashcode = JedisClusterCRC16.getCRC16(object.toString());
int segement = hashcode % (getConfig().getBloomNumber() + 1);
return getBloomFilterKey(segement);
}
/**
* 获取布隆过滤器key
*/
private String getBloomFilterKey(int index) {
return getName() + ":" + index;
}
public String getName() {
return getConfig().getName();
}
public BloomFilterBuilder getConfig() {
return config;
}
public HashFunction getHashFunction() {
return getConfig().getHashFunction();
}
public List<Integer> hash(Object object) {
byte[] bytes = object.toString().getBytes();
return getHashFunction().hash(bytes, getConfig().getBloomMaxSize(), getConfig().getHashIterations());
}
}
BloomFilterBuilder 是布隆过滤器的构造器,里面包含了很多参数,包括 JedisPool、布隆过滤器名 name、大位图总长度 totalSize、每个小位图(布隆过滤器)长度 bloomMaxSize、布隆过滤器个数 bloomNumber、hash函数个数 hashIterations、预期插入条数 expectedInsertions、预期错误概率 falseProbability、hash函数 hashFunction、是否重写已经存在的布隆过滤器 overwriteIfExists、是否完成 done。
基于 Redis 单机实现存在的问题:
- 速度慢,比本地慢,可以考虑与应用同机房部署;
- 容量受限,Redis 最大字符串为 512 MB,Redis 单机容量受限,可以考虑基于 Redis Cluster 实现;
5.Redis分布式布隆过滤器
基于 Redis Cluster 实现。会使用多个布隆过滤器,二次路由。
基于 pipeline 提高效率:
/**
* pipeline setbit
*/
private boolean pipelineSetBit(String key, Set<Integer> offsetSet) {
int slot = JedisClusterCRC16.getSlot(key);
JedisPool jedisPool = getJedisCluster().getConnectionHandler().getJedisPoolFromSlot(slot);
Jedis jedis = null;
Pipeline pipeline = null;
try {
jedis = jedisPool.getResource();
pipeline = jedis.pipelined();
for (int offset : offsetSet) {
pipeline.setbit(key, offset, true);
}
pipeline.sync();
return true;
} catch (Exception e) {
logger.error(e.getMessage(), e);
return false;
} finally {
if (pipeline != null)
pipeline.clear();
if (jedis != null)
jedis.close();
}
}
/**
* pipeline get
*/
private Map<Integer, Boolean> pipelineGetBit(String key, List<Integer> offsetList) {
Map<Integer, Boolean> offsetResultMap = new HashMap<Integer, Boolean>();
int slot = JedisClusterCRC16.getSlot(key);
JedisPool jedisPool = getJedisCluster().getConnectionHandler().getJedisPoolFromSlot(slot);
Jedis jedis = null;
Pipeline pipeline = null;
try {
jedis = jedisPool.getResource();
pipeline = jedis.pipelined();
for (int offset : offsetList) {
pipeline.getbit(key, offset);
}
List<Object> objectList = pipeline.syncAndReturnAll();
int i = 0;
for (Object object : objectList) {
offsetResultMap.put(offsetList.get(i), (Boolean) object);
i++;
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
} finally {
if (pipeline != null)
pipeline.clear();
if (jedis != null)
jedis.close();
}
return offsetResultMap;
}
参考:
https://hackernoon.com/probabilistic-data-structures-bloom-filter-5374112a7832
https://www.jasondavies.com/bloomfilter/
http://ifeve.com/google-guava-hashing/














 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









