









续上一篇《性能测试知识问题整理(一)》
十一、响应时间的258原则和业务模型的二八原则为什么不合理?
问题一:为什么响应时间的258原则不合理?
这个命题争论的问题在于「快、好」的定义上,响应时间是否合理是要进行对比的。做为不同业务下的性能水平,快的定义是不一样的,比如在数据处理业务中,常分OLAP(联机分析处理)、OLTP(联机事务处理),比如一个简单的 OLTP 查询有大厂是要求微妙级别的,OLAP 统计报表类的业务查询几分钟也是可以接受啊,例如现在的大数据技术测试,在不同的条件配置下处理TB级的数据,响应时间半天、一天都可以说是合理的响应时间。因为影响响应时间的因素有很多(存储方式,调度方式,参数调优等),单独拿“258”说明是没有意义的,比如人们常说的前端响应要<3s,只是一个常识标准没有任何决定性意义,258也同样可以是269,147。
问题二:像“业务模型用 28 原则”这些看似常识性的知识点,错在哪里?
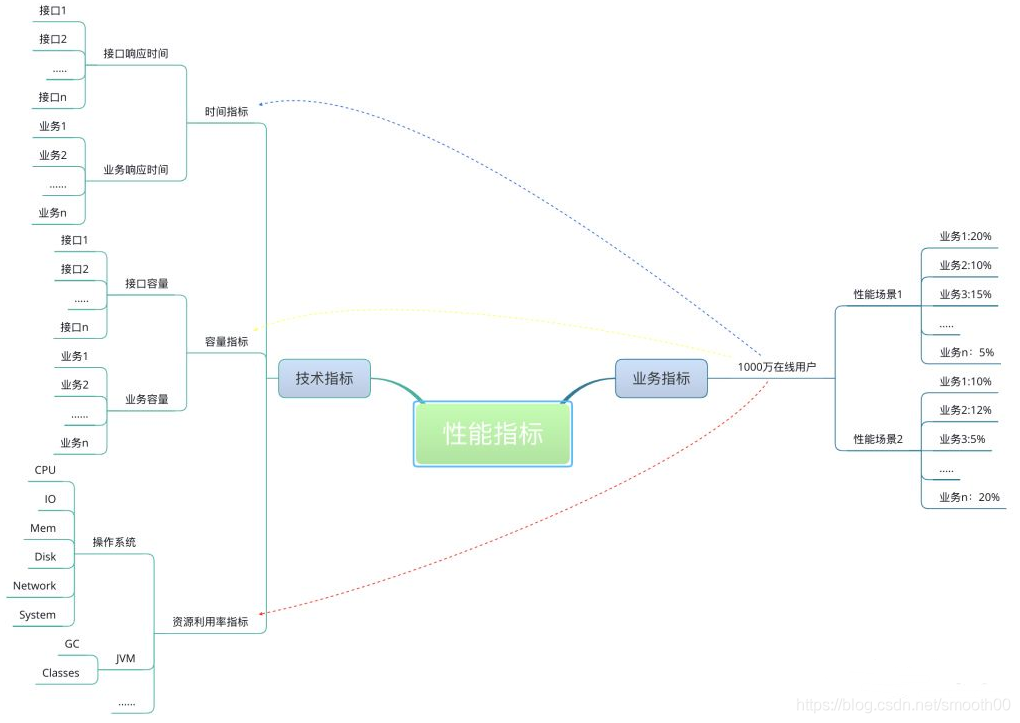
在一个具体的业务场景中,性能场景中的业务模型和二八原则并没有什么关系,即使从宏观上来说有关系,也是很牵强的,至少至今为止,还没看到任何有数据和数学公式的支撑证明。常识的适用情况在于通用,但实际场景中经常会有各种“意外”。以12306购票系统为例,以前春运抢票时经常会有朋友、家人吐槽12306好卡、好慢,估计之前业务模型用了28原则(人们习惯拿这个经济学定律移花接木到各个领域,二八定律是19世纪末20世纪初意大利经济学家帕累托发现的,帕累托从大量具体的事实中发现:社会上20%的人占有80%的社会财富),虽然已经进行过了压力测试、疲劳测试,但还是抵挡不住全国人民着急回家的心情,拼命的发送请求......所以实际情况要实际考虑,以通用估意外肯定会很多坑,只有不断地优化,更新才能一步步满足用户地需要。(PS:现在12306系统已经好很多了)。业务指标和性能指标之间的关系是这样的:
十二、为什么压力机不模拟前端?

1. 客户端接收到所有的内容之后会在前端浏览器渲染,如果在本地渲染会增加压力机性能消耗(Parse前端的HTML,需要一些计算量,把内容再render出来,又需要更多的内存),当消耗过大会影响压力机发压能力,如果下载资源保存到本地,会增加IO操作,降低压力机性能。也正是因为不模拟这些内容,才让一台机器模拟成百上千的客户端成为了可能。
2. 前端js/css/img等静态资源都走CDN,基本上也多余让压力机来跑了。
模拟前端消耗的计算资源太大,而且压测意义也并不大。一般压力机只关注前端发出的API(一个HTML页面,Load之后会load更多的一些API,这些API可以通过估算,进行混合测试),连静态资源请求都不太关注(因为那些静态资源,通常会被浏览器Cache / 网络中的一些路由器给cache,且是从一个静态资源的server如nginx单独提供服务,所以可忽略)。
说白了需要测的是前端对后端所产生的压力,至于前端本身的性能可以忽略掉(交由前端性能监测工具来关注,比如浏览器监测、手机APP监测),毕竟前端面向的是单机操作,后端才是要应对各种并发压力。
目前的压力工具大部分是针对服务端,即模拟「网络 API 请求」,而前端程序基本上是由一系列的「用户交互事件」所驱动,其业务状态是一颗 DOM 树。
通常来讲,前端性能关注的是浏览器端的页面渲染时间、资源加载顺序、请求数量、前端缓存使用情况、资源压缩等内容,希望借此找到页面加载过程中比较耗时的操作和资源,然后进行有针对性的优化,最终达到优化终端用户在浏览器端使用体验的目的。
目前获取和衡量一个页面的性能,主要可以通过以下几个方面:Performance Timing API、Prpfile 工具、页面埋点计时、资源加载时序图分析;- Performance Timing API 是一个支持 Internet Explorer 9 以上版本及 WebKit;另外我还推荐一款开源的前端监控平台(zanePerfor)。
内核浏览器中用于记录页面加载和解析过程中关键时间点的机制,它可以详细记录每个页面资源从开始加载到解析完成这一过程中具体操作发生的时间点,这样根据开始和结束时间戳就可以计算出这个过程所花的时间了;
- Profile 是 Chrome 和 Firefox 等标准浏览器提供的一种用于测试页面脚本运行时系统内存和 CPU 资源占用情况的 API;
- 通过脚本埋点计时的方式来统计没部分代码的运行时间;
- 借助浏览器或其他工具的资源加载时序图来帮助分析页面资源加载过程中的性能问题。这种方法可以粗粒度地宏观分析浏览器的所有资源文件请求耗时和文件加载顺序情况。
十三、参数化数据分析的重点是什么?
1、参数化数据的来源和获取要符合哪些规则?
(1)从数据库中获取(死水数据,即out-of-box),通常要检查一下数据库中的数据直方图,对于直接从生产上拿的数据来说,数据的分布更为精准。
(2)通过API接口把数据生成(活水数据,即On-the-fly),数据库不存在这些数据,构造参数化数据需要符合业务特点。
参数化时需要确保数据来源以保证数据的有效性,千万不能随便造数据。这类数据应该满足两个条件:要满足生产环境中数据的分布;要满足性能场景中数据量的要求。
2、当参数化数据不符合规则时,会产生什么问题?
(1)不合理的数据分布,会干扰测试结果,增加后续分析和测试的工作量;
(2)数据取得过多,对系统的压力就会大;数据取得过少,不符合真实场景中的数据量,也无法掩盖缓存等其他因素的影响,无法测试出系统真实的压力。
3、参数化数据应该用多少数据量?不同的场景中为什么参数化数据有如此大的差异?
一是通过业务模型分析计算,获得初步的数据量要求;二是根据限制条件和业务场景,确定数据类型;三是结合上述两点,最终确定参数化数据的数据量。
不同场景对数据量要求不一样,我们需要保证测试时间足够长、满足测试的负载请求需求,根据「目标tps × 持续时间(秒级)」可以计算出参数化数大概的量级。
(1)循环场景使用【用户数据=线程个数】;针对场景:数据可以反复出现,不影响业务,如登录后操作其他业务,就可以用几个用户登录后,进行其重复业务操作压测。
(2)不可循环使用的数据Tps * 持续时间如【100(tps)×30*60(时间)=180000(条用户数据】 ;明白(配置参数之前,我们需要先判断这个参数是什么类型的数据);针对场景如:电商下单压测,如果用重复数据,完全不符合实际业务情况,而且会导致大量缓存,结果不真实;
4、参数多与少的选择对系统压力有什么影响?
(1)如果压力工具使用的参数化数据量少,那么应用服务器、缓存服务器、数据库服务器,都将使用少量的缓存来处理,导致命中率高,相应消耗资源比较少,测不出实际效果(响应时间比较快);
(2)参数化数据取得过多,导致缓存命中率极低,对系统的压力就会很大(大到超过实际的业务情况,也就不符合要求);
十四、性能场景应该按什么样的逻辑设计?为什么不用最大 TPS 的 80% 来做稳定性测试?如何控制TPS比率?
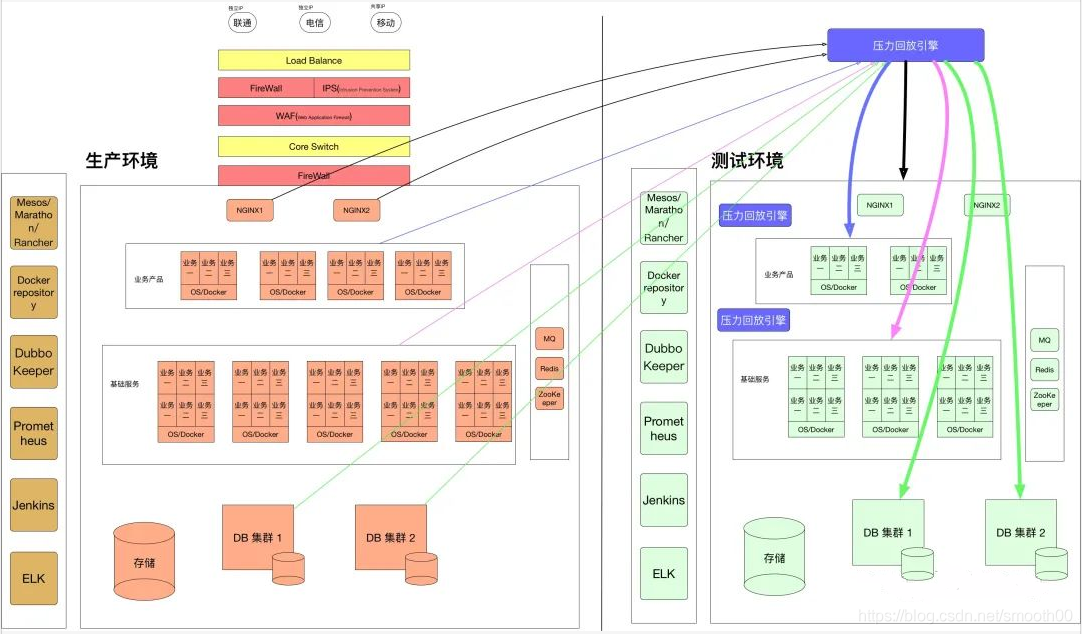
问题一:性能场景应该按什么样的逻辑设计?
通过对生产数据统计能够完整体现系统业务的峰值数据,然后转换成具体场景中的业务模型,模拟真实的生产环境中的业务比例。不同的业务对系统资源的消耗完全不一样,如果业务模型跟线上的业务模型不一样,就会导致运行过程中业务比例出现很大的偏差,那么得到的结果不够真实正确,也大大降低了性能测试的价值。
性能场景设计前应了解实际场景中对应业务的目标值(性能测试场景应该有预期的测试指标并且符合实际的生产场景)。然后查看对应业务的组成,按照生产的业务比例模拟真正的业务,以达到我们所真正需要的结果。可以采用先局部后整体的思想进行性能场景设计,一般先将单业务的基准性能测试结果得出,再进行混合业务的性能测试。值得一提的是通常情况下时间是稀缺资源,所以进行性能场景设计时,应时刻谨记以终为始的理念,得出结果后判断是否能满足业务目标。
问题二:为什么不用最大 TPS 的 80% 来做稳定性测试?
稳定性测试的关注重点应该是符合业务场景,控制好业务比例,持续运行最好满足业务需要的时长;而很多人会选用最大TPS的80%来做稳定性测试,我想应该是受二八法则的影响,其实这个80%的概念可有可无,进行稳定性场景的测试就是为了知道会不会由于长时间处理业务而引发潜在瓶颈,至于用多大的 TPS 来运行,又有什么关系?这个系统用最大 TPS 能跑下来,业务一直很正常,稳定性目标能达到,为什么不能用最大 TPS 来跑呢?只要系统在正常处理,资源没有出现问题,也没有报错,那这个场景就是有效的,目标也是能达到的。
稳定性场景示例(需要看业务类型,不代表都适合这么估算稳定性场景):业务 + 运维部门联合给出了一个指标,那就是系统要稳定运行一周,支持 2000 万业务量。针对给出的容量结果,假设容量 TPS 能达到 3800(根据业务 1 到业务 n 的容量测试结果 TPS 总和)。那么稳定性场景时间应该是:20000000/3800 = 1.46 小时。这就是通过业务积累量的角度来估算稳定性时间,实现了用最短时间达到稳定性测试的目标,(可以说没必要跑测一周时间来验证稳定性,只要短时间内达到业务积累量就行。可以忽略硬件和人为层面的问题,毕竟谁没事也不用去重启系统,只要检查系统是否还在健康运行即可,因为运维团队每周会做全面系统的健康检查,大部分时候运维是等着系统警告的。)
问题三:为什么业务比例对性能场景如此重要?
不同的业务对系统资源的消耗完全不一样,如果业务比例跟实际的业务比例不一样,就会导致运行过程中资源消耗出现很大的偏差,那么得到的结果不够真实准确,也大大降低了性能测试的价值。根据木桶原理,性能瓶颈决定了系统整体性能,同样某个业务的性能短板也会决定整体业务的处理能力,所以合理的业务比例也可以真实而高效的暴露相应的短板事务。另外,如果生产流量来源是可以覆盖想要测试的业务场景的,就可以通过生产流量扩大回放的方式实现压力模拟,这样就不用费劲心思规划业务场景了(生产流量的回放,核心目的也是为了真实的覆盖所需要测试的性能场景,现在已然成为全链路压测的一种测试方式)。
问题四:如何在执行场景过程中控制 TPS 比例呢?
通常,在 LoadRunner 里,会用pacing来控制 TPS,用场景百分比模式或随机函数判断来实现业务的比例控制;而用 JMeter 则会用Constant Throughput Timer来控制 TPS,用Throughput Controller或其他逻辑控制器等方式来控制业务的TPS比例。
控制TPS比例需要根据线上的统计得到每个服务TPS的峰值及范围,不同的天数和时段TPS是不同的,需要根据线上的TPS的比例去测试系统的资源占用和性能指标,这样才能够真实的反应系统的性能情况,不论做系统当前性能测试还是未来系统的容量规划都是有意义的。
十五、为什么说用什么监控平台并不重要?为什么要先有全局监控,再有定向监控?为什么不建议一开始就上代码级的监控工具呢?
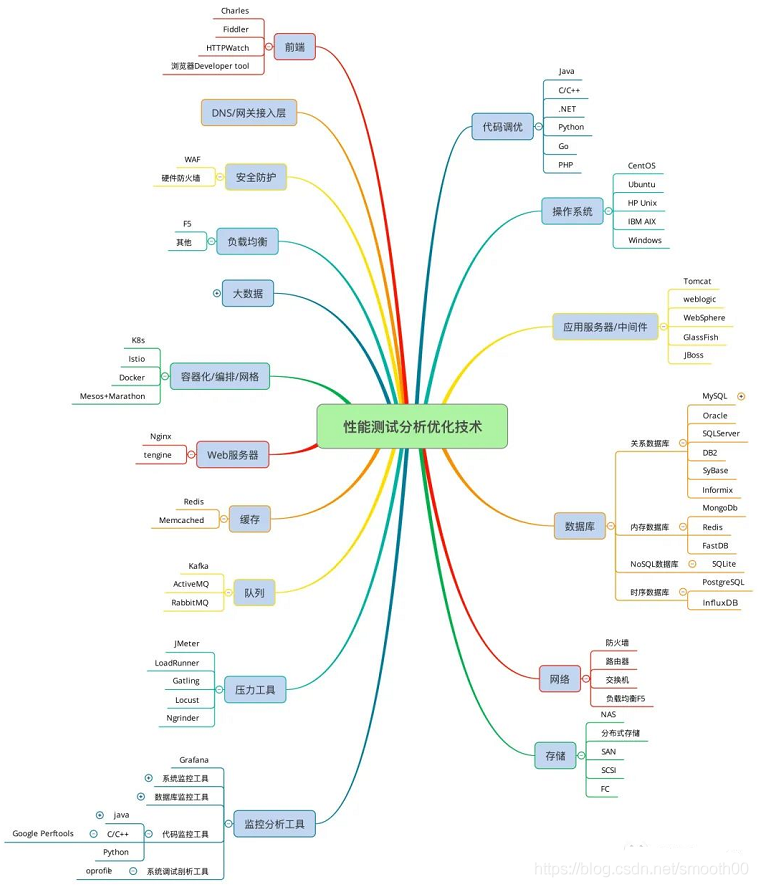
问题一:为什么说用什么监控平台其实并不重要?
1. 监控原理首先要掌握,再花哨的平台,不懂它的原理,光看着一堆不知所以然的性能指标,也会让人眼花缭乱(况且监控平台也多呀,你怎么保证就一定适合你和你的项目)。面对繁杂的一堆指标,其实建议首先学会掌握一些基础的监控命令和指标,比如通过常用监控命令iostat分析IO指标和CPU使用情况,通过内存常用命令 free分析内存指标(total肯定是要优先看的,其次是available,这个值才是系统真正可用的内存,而不是free),网络方面通过netstat或其他命令可以看到Recv_Q和Send_Q以判断瓶颈在什么地方。
2. 监控分析的时候,心中也要有一些基本的性能知识(或叫常识吧),比如当一个系统调优到非常精致的程度时,基本上会卡在两个环节上,对计算密集型的应用来说,会卡在 CPU 上;对 I/O 密集型的应用来说,瓶颈会卡在 I/O 上;否则漫无目的的去看花哨的监控平台,效果也好不到哪去。
3. 另外从分段分层的监控步骤来说,操作系统的监控也是首先考虑的,而各类操作系统提供的监控数据本身就很丰富(一般监控平台采样的也是这些数据进行图表汇总,关注的也还是【I/O、Memory、System、NetWork、Swap】)。
虽然说监控平台是什么不重要,但还是推荐一下开源的监控产品组合:
jmeter+influxdb+grafana(见 https://blog.csdn.net/smooth00/article/details/79926294)
jmeter+influxdb+telegraf(或 prometheus+exports+grafana),参见 全方位的开源监控工具链介绍
问题二:为什么要先有全局监控,再有定向监控?
性能测试的目的无非就是找到性能瓶颈然后进行分段分层分析,所以先全局监控,才能有全面系统的数据分析,避免遗失信息,能更快速有效的发现问题。
通过分析全局、定向、分层的监控数据做分析,再根据分析的结果决定下一步要收集什么信息,然后找到完整的证据链,才能体现监控的价值。
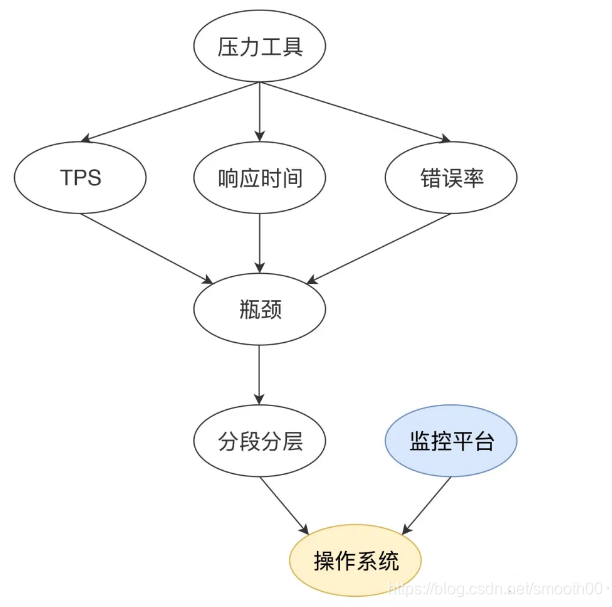
问题三:为什么不建议一开始就上代码级的监控工具呢?
因为代码级的监控消耗资源,更重要的是,代码级监控数据很多,查看这些数据耗费精力,就像大海捞针,没必要像无头苍蝇乱撞。如果定位到它们有问题时再去监控、去看,更一针见血。
关于监控工具以Java项目为例,常用的代码级监控工具包括JDK自带工具(jcmd、jmap、jstack、jconsole、jvisualvm等)、arthas(阿里开源监控工具)、还有一些市面上的APM监控产品,这些工具都适合在调试阶段使用,而在压测阶段直接上这些工具,所产生的大量监控数据也足以让人头疼(但对于一些优秀的APM监控产品,由于具有一部分性能分析和全链路监控的功能,在一些全链路压测场景下去使用也未尝不可,建议前期还是不上了,特别是一些开源的APM监控产品,无法保证本身的agent稳定性,压着压着导致业务系统崩了可就悲催了)。
十六、为什么 CPU 是很多性能问题分析的方向性指标?
应用无非就是两种:计算密集型和IO密集型,计算密集集就体现在CPU忙,IO密集型就体现在CPU空闲,我想接下来无非就是围绕这两种类型展开分析,所以说CPU是性能分析的方向性指标。
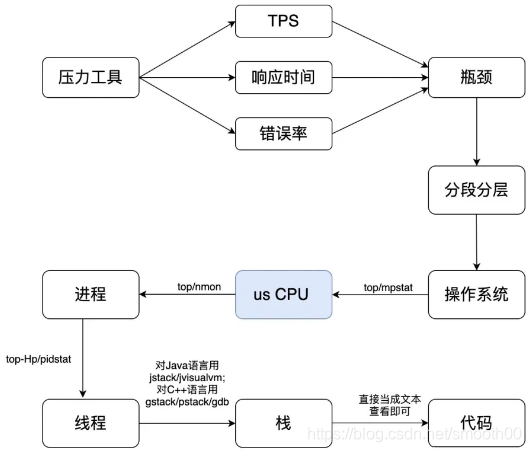
十七、Tomcat应用服务器如何拆解监控计数器?如何判断应用服务器的线程是否够用?
问题一:Tomcat应用服务器如何拆解监控计数器?
在当今 Spring Cloud 微服务架构盛行的时代,Tomcat 仍然作为应用最广的应用服务器而存在着,所以我们不得不说一说对它的性能分析。很多时候,我们做性能测试分析时,都会把 Tomcat 这类的应用弄混淆。对它的监控和分析,总是会和 JDK、框架代码、业务代码混合来看,这就导致了分析上的混乱。我们应该把这些分析内容分隔开来,哪些是 tomcat,哪些是 JDK 等。在我看来,Tomcat、WebLogic、WebSphere、JBoss 等,它们都具有同样的分析思路。因为 Tomcat 的市场范围更大,所以,今天,我们以它为例来说明这类应用应该如何分析。首先我们得知道它的架构:
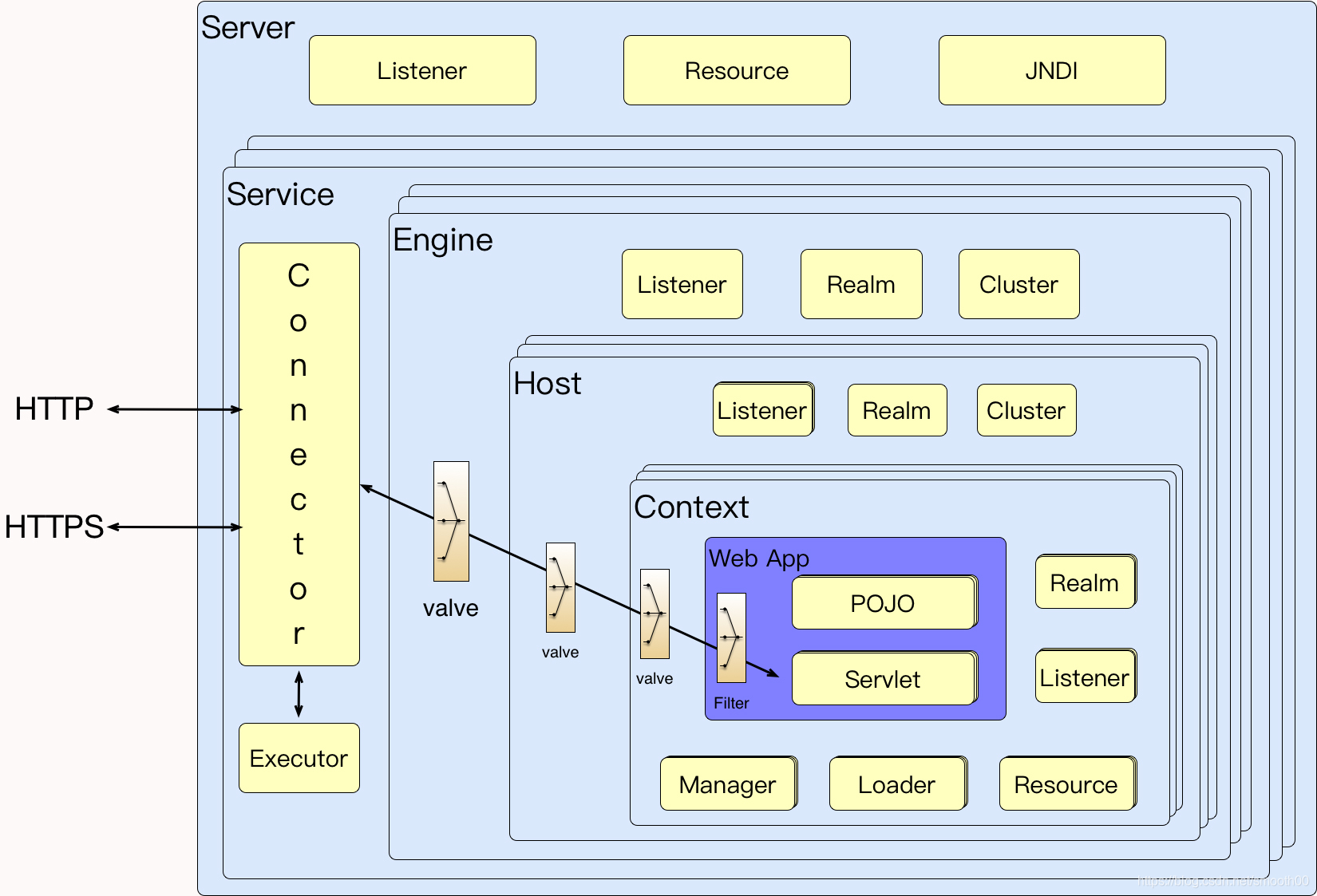
然而,我们做性能分析的人真的要完全掌握这些细节吗?当然不是。从经验上来说,基本上有几大方面,是 Tomcat 优化时需要关注的。如下图所示(其中操作系统和JDK属于和tomcat紧密相关):
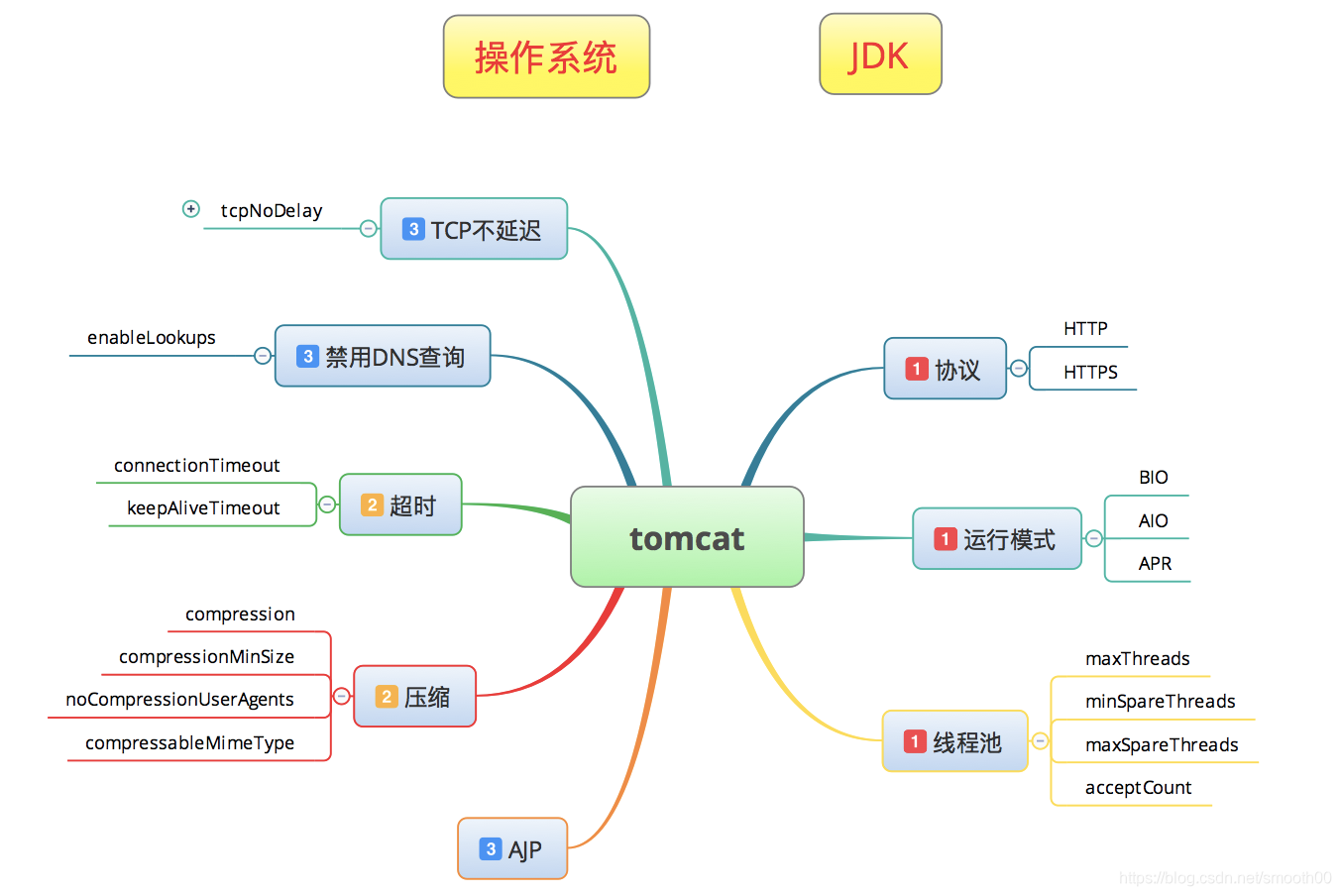
基本从以下几个方面的计数器来分析优化Tomcat(以及类似tomcat的应用服务器):协议(http,https),运行模式(BIO,AIO,APR),线程池(maxThreads、acceptCount);超时时间,压缩,TCP不延迟,禁用DNS查询,禁用AJP连接器。
问题二:如何判断应用服务器的线程是否够用
测试过程中应用监控工具如jvisualvm监控线程同一时刻是否有空闲状态,如果一直是runnable状态,同时响应时间不断增加,说明线程数不够用。
十八、MySQL 中全局监控工具可以给我们提供哪些信息?如何判断 MySQL 状态值和配置值之间的关系?
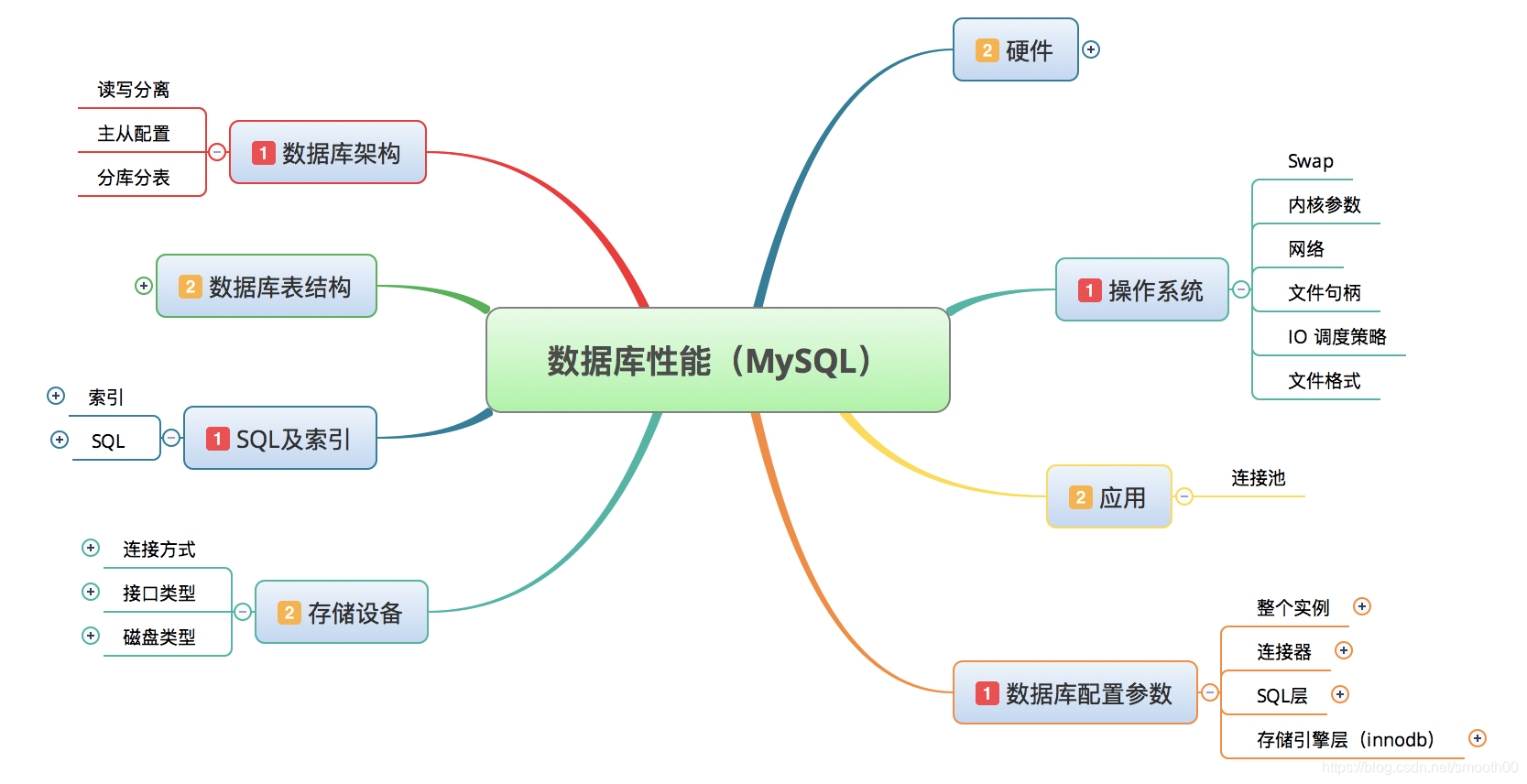
问题一:MySQL 中全局监控工具可以给我们提供哪些信息?
索引报表、操作报表、查询和排序报表、查询缓存报表、表锁报表、表信息报表、连接报表和临时报表、线程报表、innodb缓存池报表、innodb锁报表等。
mysql监控推荐的工具包括mysqlreport、pt-query-digest 和 mysql_exportor+Prometheus+Grafana,其中pt-query-digest可以定身抓取SQL,它可以分析slow log、general log、binary log,还能分析 tcpdump 抓取的 MySQL 协议数据,可见这个工具有多强大。pt-query-digest属于 Percona-tool 工具集,这个 Percona 公司还出了好几个特别好使的监控 MySQL 的工具。pt-query-digest分析 slow log 时产生的报告逻辑非常清晰,并且数据也比较完整。执行命令后就会生成一个报告。
问题二:如何判断 MySQL 状态值和配置值之间的关系呢?
SHOW GLOBAL VARIABLES:用来查看配置的参数值,和SHOW GLOBAL status:用来查询状态值。测试结束后通过mysql监控工具查看和分析状态值,从而判断数据库配置值是否合理。
十九、数据库分析的大体思路是什么?如何定位出慢SQL?如何在数据库中迅速找到一个慢 SQL 的根本原因?
问题一:数据库分析的大体思路是什么?
1.全局分析:分析数据库硬件配置,数据库配置,SQL语句,采用全局监控工具如mysqlreport工具收集到的测试数据,分析可能存在的问题;
2.定向分析:如针对慢查询导致的性能问题,采用pt-query-digest工具分析慢查询日志抓取存在问题的sql,利用profiling分析sql语句的每一个层级,查看sql执行计划,对sql进行优化。
问题二:慢SQL如何定位出来?
以mysql为例,根据慢日志定位慢查询sql,执行如下语句看是否启用慢查询日志,ON为启用,OFF为没有启用
show variables like "%slow_query_log%"
可以看到我的没有启用,在命令行中执行如下两句打开慢查询日志,设置超时时间为1s
set global slow_query_log = on;
set global long_query_time = 1;
想要永久生效得到配置文件中配置,否则数据库重启后,这些配置失效
执行如下语句获得慢查询数量
show status like "%slow_queries%"
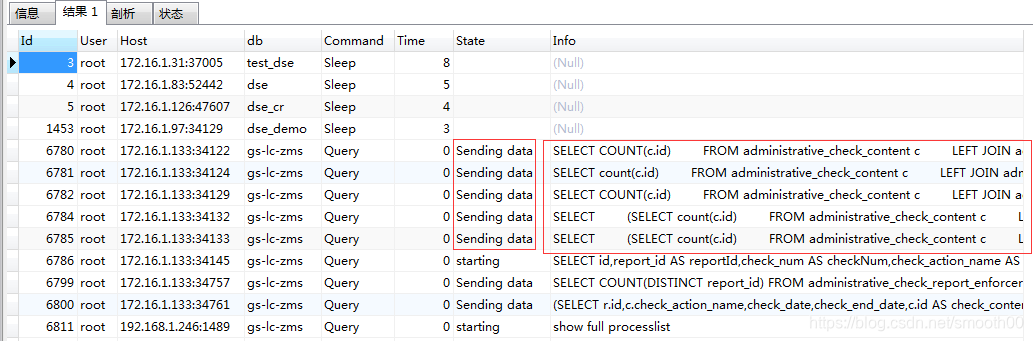
补充:以上是常规的慢SQL定位方法,其实现在的APM监控平台具有链路监控功能,也能监控到慢SQL,原理和以上不一样,但效果也差不多,也能起到监控的作用(而且不用开启慢日志)。另外如果是正在压测中,实时追踪慢查询,也可通过在mysql中执行命令:show full processlist; 这也是有可能定位出慢SQL的(因为显示线程占用CPU高的SQL),如下所示:
问题三:如何在数据库中迅速找到一个慢 SQL 的根本原因?
profiling分析sql语句的每一个层级,结合sql语句执行计划分析慢sql根本原因。举例:
- 开启
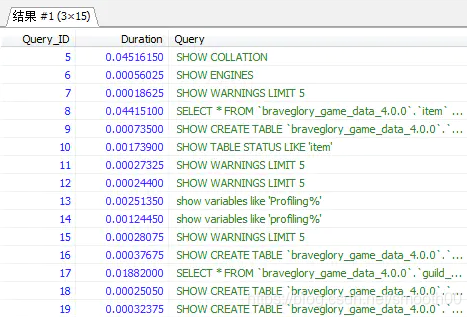
Profiling:set profiling=1;开启此功能后,就能执行我们的SQL语句 - 展示最近的SQL执行情况:
show profiles;此命令展示最近执行的sql语句,默认是15次,如下:
- 具体查看id=8的SQL执行细节:
show profile cpu,block io for query 8;如下:
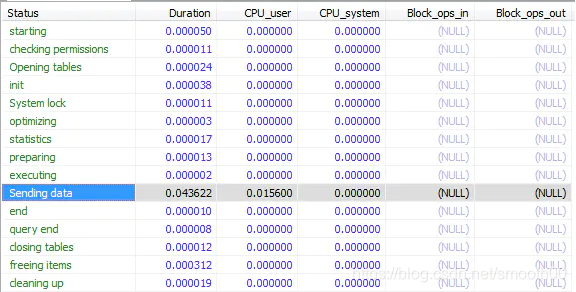
上图的SQL执行具体细节,左边Status列展示了一条SQL执行的从开始到清理的整个生命周期中执行的操作。如果在其生命周期阶段出现如下的情况的就要重视了:
- converting HEAP to MyISAM:查询结果太大,内存都不够用了往磁盘上面搬了
- Creating tmp table:创建了临时表,先拷贝到临时表,用完后再删除
- Copying to tmp table on disk:把内存中的临时表复制到磁盘中,这个很耗性能
- locked:这个就是指在等待锁的意思
二十、 APM 工具可以为我们提供哪些分析便利?SkyWalking 有哪些具体功能点可以帮助我们进行性能分析?
问题一:APM 工具可以为我们提供哪些分析便利?
最主要的便利就是链路跟踪、全链路监控,在日常运维中是个不错的工具,而对于性能测试来说,也可以铺助定向分析(通过测试已经发现哪些功能和接口慢的基础上,通过APM监控可以进一步分析慢的可能原因,为后面开发人员在代码层面的优化和分析提供一些帮助)。
问题二:SkyWalking 有哪些具体功能点可以帮助我们进行性能分析?
太多了,作为一款开源的监控工具确实不错,可以关注 Skywalking vs Pinpoint 的比较,同样是开源,Skywalking会更受欢迎一点。比起商用的工具[卓豪ManageEngine]还是会差一些(特别是稳定度和本身的性能方面要差不少),跟国内的OneAPM、博睿、听云、云智慧等APM云监控平台相比,功能也会少一些,但是作为开源的力量是巨大的,期待更好的变化。
具体哪些功能可以帮到我们,到官网看吧 http://skywalking.apache.org/zh
未完待续......见:性能测试知识问题整理(三)















 1653
1653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









