









了解zookeeper
ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。Zookeeper是hadoop的一个子项目。
在分布式应用中,由于工程师不能很好地使用锁机制,以及基于消息的协调机制不适合在某些应用中使用,因此需要有一种可靠的、可扩展的、分布式的、可配置的协调机制来统一系统的状态。Zookeeper就是为此而生的。下面我们就一起来了解一下zookeeper的结构、工作角色以及应用场景等,对于如何使用zookeeper我们下去自己找环境进行一些实践,网上也有资料,就不在这里进行说明了。
zookeeper的结构
zookeeper分为服务器端(server)和客户端(client),客户端可以连接到整个zookeeper服务的任意服务器上(除非leaderServes参数被显式设置,leader不允许客户端连接)。客户端使用并维护一个TCP连接,通过这个连接发送请求、接收响应、获取观察的事件以及发送心跳包。如果这个TCP连接中断,客户端将自动尝试连接到另外的zookeeper服务器。客户端第一次连接到zookeeper服务时,接收这个连接的zookeeper服务器会为这个客户端建立一个会话。当这个客户端连接到另外的服务器时,这个会话被新的服务器重新建立。
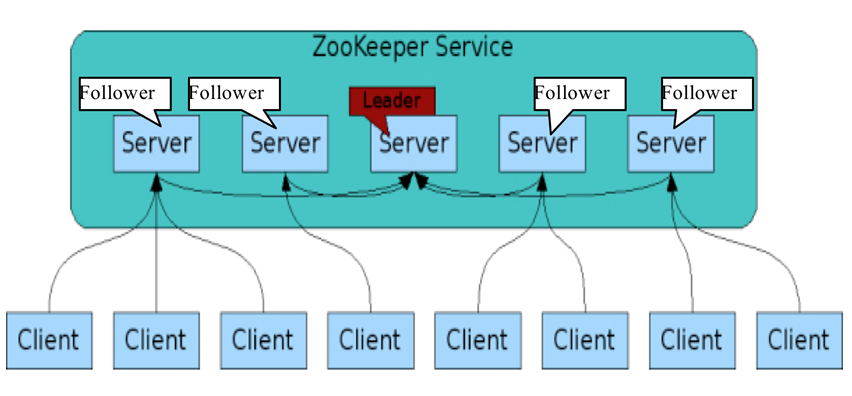
Zookeeper的角色
- 领导者(leader),负责进行投票的发起和决议,更新系统状态
- 学习者(learner),包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票
- Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度
- 客户端(client),请求发起方
zookeeper应用场景
zookeeper 从设计模式角度来看,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生了变化,zookeeper 就将负责通知已经在 zookeeper 上注册的那些观察者做出相应的变更,从而实现集群中类似 Master/Slave 管理模式。
1、统一命名服务(Name Service)
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。说到这里你可能想到了 J2EE规范里的JNDI,没错 Zookeeper 的 Name Service 与 JNDI 能够完成的功能是差不多的,它们都是将有层次的目录结构关联到一定资源上,但是 Zookeeper 的 Name Service 更加是广泛意义上的关联,也许你并不需要将名称关联到特定资源上,你可能只需要一个不会重复名称,就像数据库中产生一个唯一的主键一样。
Name Service 已经是 Zookeeper 内置的功能,我们只要调用 Zookeeper 的 API 就能实现。如调用 create 接口就可以很容易创建一个目录节点。
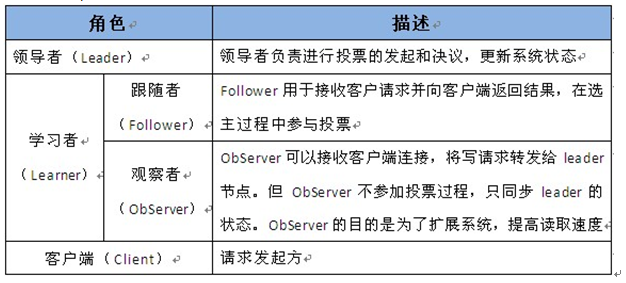
2、配置管理(Configuration Management)
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。
像这样的配置信息完全可以交给 Zookeeper 来管理,将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中即可。
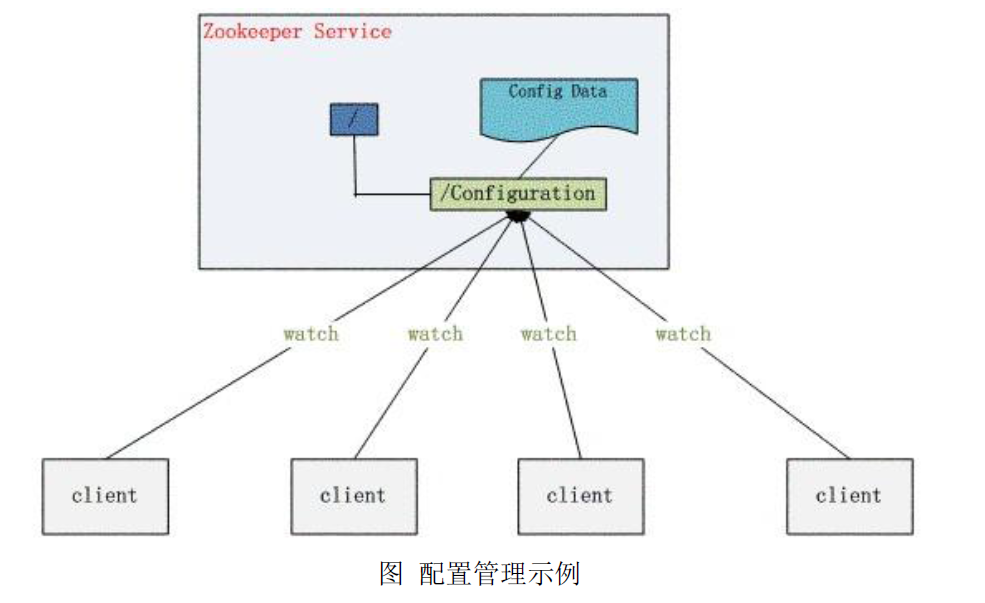
3、集群管理(Group Membership)
Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要有一个“总管”知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它服务器必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让“总管”知道。
Zookeeper 不仅能够帮你维护当前的集群中机器的服务状态,而且能够帮你选出一个“总管”,让这个总管来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。它们的实现方式都是在 Zookeeper 上创建一个 EPHEMERAL 类型的目录节点,然后每个 Server 在它们创建目录节点的父目录节点上调用 getChildren(String path, boolean watch) 方法并设置 watch 为 true,由于是 EPHEMERAL 目录节点,当创建它的 Server 死去,这个目录节点也随之被删除,所以 Children 将会变化,这时 getChildren上的 Watch 将会被调用,所以其它 Server 就知道已经有某台 Server 死去了。新增 Server 也是同样的原理。
Zookeeper 如何实现 Leader Election,也就是选出一个 Master Server。和前面的一样每台 Server 创建一个 EPHEMERAL 目录节点,不同的是它还是一个 SEQUENTIAL 目录节点,所以它是个 EPHEMERAL_SEQUENTIAL 目录节点。之所以它是 EPHEMERAL_SEQUENTIAL 目录节点,是因为我们可以给每台 Server编号,我们可以选择当前是最小编号的 Server 为 Master,假如这个最小编号的 Server 死去,由于是 EPHEMERAL节点,死去的Server 对应的节点也被删除,所以当前的节点列表中又出现一个最小编号的节点,我们就选择这个节点为当前Master。这样就实现了动态选择 Master,避免了传统意义上单 Master 容易出现单点故障的问题。
下一篇继续…

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









