







转自:
http://blog.sina.com.cn/s/blog_4aca42510102vuxo.html
Hadoop 的存在价值是什么?Hadoop 解决的是哪些问题?简单来讲,大型企业和政府都可能会包含有大量数据, (我们可以看做是一块巨大的豆腐)例如马路卡口监控视频拍摄的机动车号牌,我们如果要对如此海量的数据进行复杂的分析,还要非常快速的得到结果,如果使用一台计算机,根本无法胜任这个工作。如果能将这个庞然大物分割成许多小的数据块,并将其分发给许许多多的服务器来协同计算,那么这个效率自然是很快的,所以,Hadoop 的存在价值就体现在这里。
Hadoop 的存在价值是什么?Hadoop 解决的是哪些问题?简单来讲,大型企业和政府都可能会包含有大量数据, (我们可以看做是一块巨大的豆腐)例如马路卡口监控视频拍摄的机动车号牌,我们如果要对如此海量的数据进行复杂的分析,还要非常快速的得到结果,如果使用一台计算机,根本无法胜任这个工作。如果能将这个庞然大物分割成许多小的数据块,并将其分发给许许多多的服务器来协同计算,那么这个效率自然是很快的,所以,Hadoop 的存在价值就体现在这里。
例如上面那个邮件的例子,经过日积月累,我们的服务器存有大量的邮件,我们可以将这些邮件打包成文本发送给Hadoop 集群,只需要编写一个简单的计算单词量的函数,并提交给集群,集群通过相互协调,在短时间内计算完毕之后返回一个结果。我就可以得到我想要的结果了。
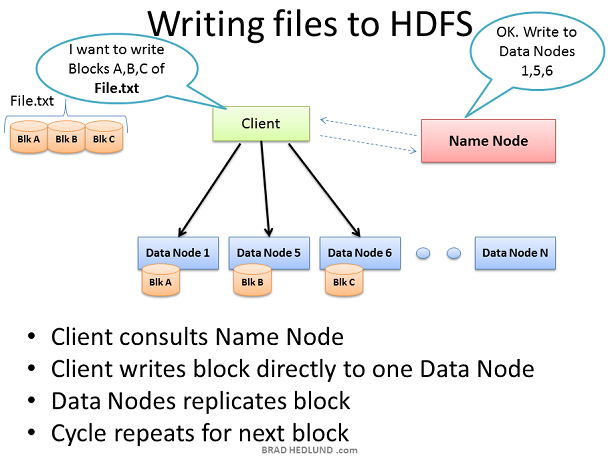
Hadoop 集群有了数据之后,便开始工作。我们在此的目的是大量数据的快速并行处理,为了实现这个目标,我们应当利用尽可能多的机器,为此,客户端需要将数据分拣分成较小的块,然后将这些快在集群中不同的机器上并行计算。但是,这些服务器中的某些服务器可能会出现故障,因此,应当将每个数据块做几次拷贝,以确保数据不会被丢失。默认的拷贝次数是3次,但是我们可以通过 hdfs-site.xml 配置文件中 dfs.replication 这个参数来控制拷贝次数。
客户端将 File.txt 切割成三块,并与Name Node协调,Name Node告知客户端将这些数据分发到哪些 Data Node 上,收到数据块的 Data Node 将会对收到的数据块做几次复制分发给其他的 Data Node 让其他的 Data Node 也来计算同样的数据(确保数据完整性)。此时,Name Node 的作用仅仅是负责管理数据,例如:哪些数据块正在哪个Data Node上计算,以及这些数据将会运行到哪里。(文件系统的元数据信息)
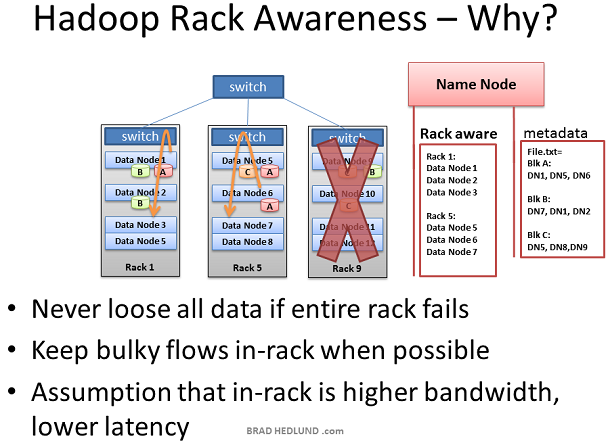
Hadoop 有“机架意识”的概念,作为 Hadoop 的管理者,你可以手动的在你的集群中为每一个Slave Data Node定义机架号。你可能会问,我为什么要做这个工作?这里有两个关键点:数据丢失防护以及网络性能。
记住,每一个数据块将会被复制到多态服务器上以确保数据不会因某个服务器的宕机而造成数据丢失,但是如果不幸的是,所有的拷贝都存放于一台机架上,而这个机架由于种种原因造成了整个机架与外部断开连接或整体宕机。例如一个严重的错误:交换机损坏。因此,为了避免这种情况的发生,需要有人知道每一个 Data Node 在整个网络拓扑图中的位置,并智能的将数据分配到不同的机架中。这个就是 Name Node 的作用所在。
还有一种假设,即两台机器在同一个机架和分属于不同的机架比起来有更好的带宽和更低的延迟。机架交换机上行链路带宽通常比下行带宽更少,此外,在机架内延迟通常比机架外的延迟要底。如果 Hadoop 有了相同机架优化的意识(提高网络性能),同时能够保护数据,这不是很酷吗?
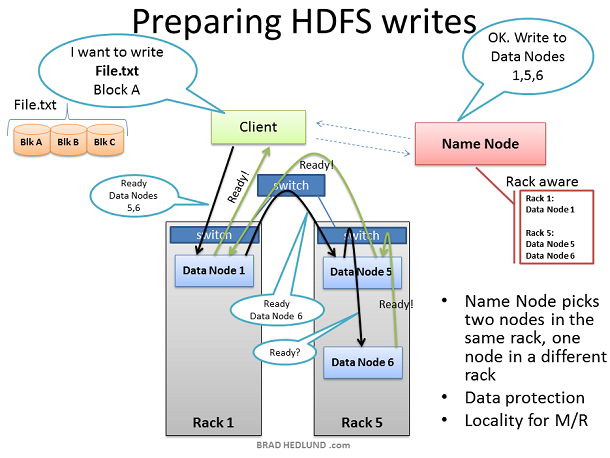
这里的客户端已经准备好将 FILE.txt 分成三块添加到集群中。客户端会先告诉 Name Node 它将要把数据写入到集群中,从 Name Node处得到允许后,并受到 Name Node 为其分配的 Data Node 清单,Name Node分配 Data Node 的时候会有一个智能决策的步骤,以默认的拷贝次数来讲(3次), Name Node 会将其中两个副本放在同一个机架中,而剩下的一个副本会放在另外一个机架中,并将分配结果告诉给客户端,客户端将会遵循这个分配结果将数据分配给三个 Data Node。
当客户端接收到 Name Node 给出的任务分配清单后,开始将数据传输给 Data Node,例如:Client 选择 Block A 打开 TCP 50010 端口,告诉 Data Node 1 说:“嘿,给你一个数据块 Block A,然后你去确保 Data Node 5 也准备好了,并让它问问 Data Node 6 是不是也准备好了”。如此,Data Node们会通过TCP 50010 端口原路返回并逐层告知自己准备好了,最终让客户端得知清单上所列出的 Data Node 都准备好了。当客户端得知都准备好之后,开始准备写数据块到集群中。
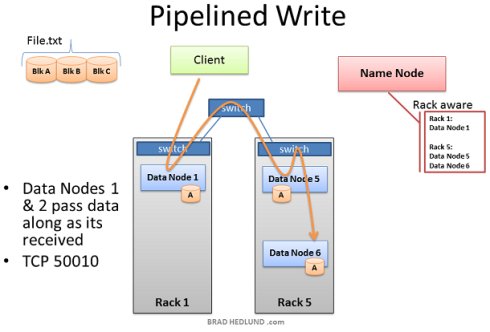
数据块被第一个 Data Node 接收后,会将其复制给下一个 Data Node 以此类推(复制次数由 dfs.replication 参数控制)。
此处我们可以看到,Data Node 1 之所以在不同的机架上,是为了避免数据丢失,而 Data Node 5 和 Data Node 6 存在于同一个机架是为了保证网络性能和低延迟。直到 Block A 被成功的写入到第三个节点,Block B 才会开始继续写入。
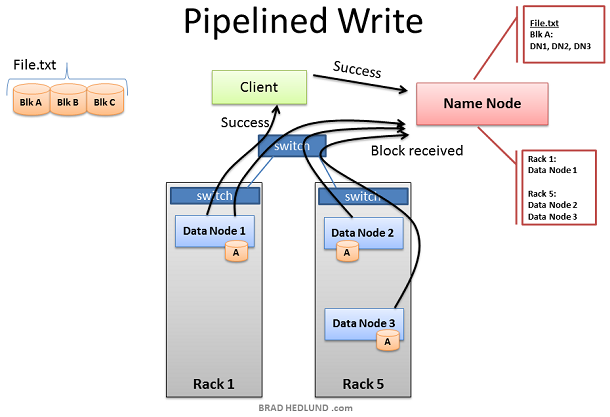
当所有的 Data Node 已经成功的接收到了数据块,它们将会报告给 Name Node,同时也会告知客户端一切准备就绪并关闭回话,此时客户端也会返回一个成功的信息给 Name Node。Name Node 开始更新元数据信息将 Block A 在 File.txt 中的位置记录下来。
然后重复以上操作,直到剩下的两个数据块 Block B和 Block C 也分别写入到其他的 Data Node 中。
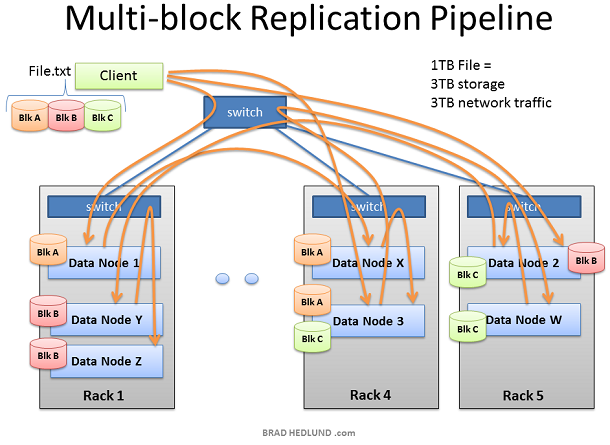
通过以上步骤我们可以得知,如果我们有一个1TB的数据要做分析,那么我们所占用的网络流量和磁盘空间将如下:
使用流量= 磁盘空间 = dfs.replication*数据大小
例如我们默认的设置是拷贝三次,那么我们就需要消耗3TB的网络流量和3TB的磁盘空间。
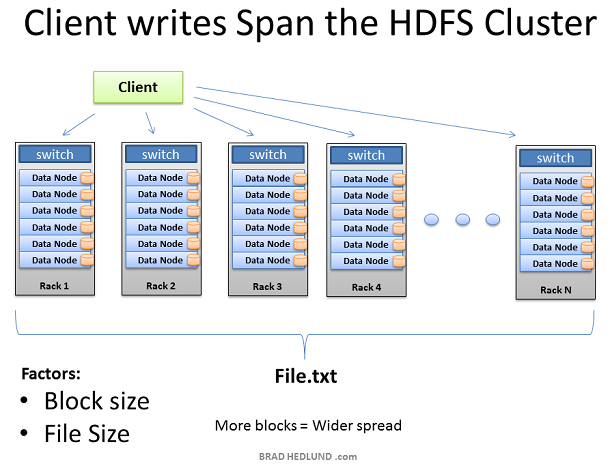
这样,就如我们预期的那样,将一个大的数据分割成无数小的数据提交给多个Data Node 进行并行计算。在这里,我们可以通过横向扩展增加服务器的数量来提高计算性能,但同时,网络I/O 的吞吐也成为了计算性能瓶颈之一,因为如果横向扩展,会给网络吞吐带来巨大的压力,如何将 Hadoop 过渡到万兆以太网是即将到来的难题。、
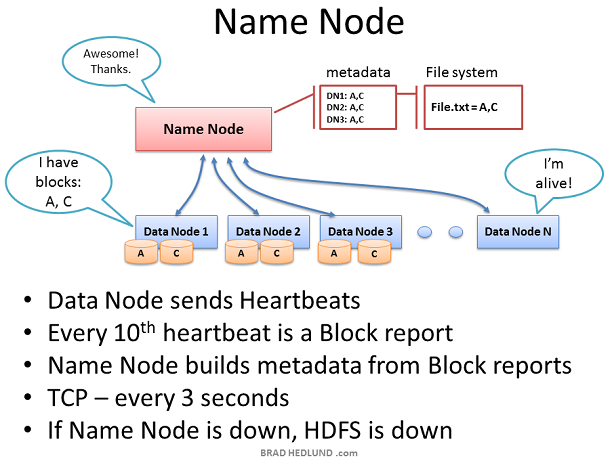
Name Node 在整个 HDFS 中处于关键位置,它保存了所有的文件系统的元数据信息用来监控每个 Data Node 的健康状况。只有 Name Node 知道数据从哪里来、将要被分配到哪里去,最后返回给谁。
Data Node 会每3秒钟一次通过 TCP 9000端口发送心跳给 Name Node。每10次心跳生成一个健康报告,心跳数据都会包含关于该Data Node所拥有的数据块信息。该报告让 Name Node 知道不同的机架上不同的Data Node上存在的数据快的副本,并为此建立元数据信息。
Name Node的重要性不言而喻,没有它,客户端将不知道如何向HDFS写入数据和读取结果,就不可能执行 Map Reduce 工作,因此,Name Node 所在的服务器应当是一个比较牛逼的服务器(热插拔风扇、冗余网卡连接、双电源等)。
如果 Name Node 没有接收到 Data Node 发送过来的心跳,那么它将会假定该 Data Node 已经死亡。因为有前面的心跳报告,因此 Name Node 知道该死亡的 Data Node 目前的工作内容以及进度,它将会将该 Data Node 所负责的内容分发给其他的 Data Node去完成。(同样根据机架意识来分发该任务)。
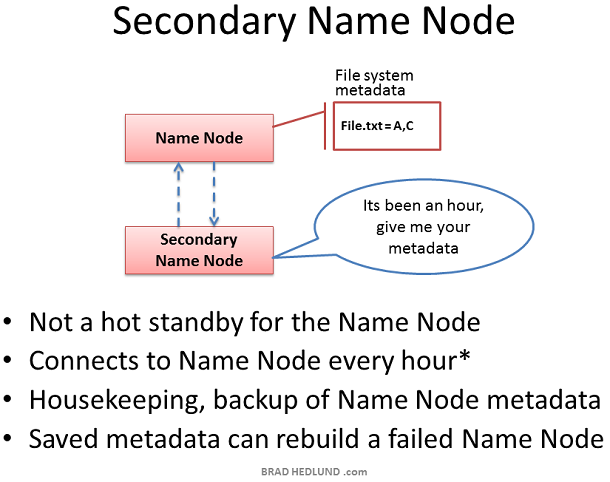
Secondary Name Node 在国内通常被称为辅助 Name Node 因为它并不是一个完整备份, Secondary Name Node 的存在虽然是为了确保 Name Node 在宕机后能够接手其职责,但是它与 Name Node 之间的元数据交互不是实时的。默认为每隔一小时,Secondary Name Node 会主动请求 Name Node,并从 Name Node 中拿到文件系统的元数据信息(同步)。这个间隔可以通过配置项来设置。
因此,如果万一 Name Node 宕机,虽然 Secondary Name Node 能够接手参加工作,但是依然会造成部分的数据丢失。因此,如果数据非常重要,默认的一小时同步一次可能远远不足以保护数据的计算进度,我们可以缩短其同步时间来增加数据的安全性例如:每分钟同步一次。















 1996
1996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









