







如前所述,回归是使用函数来模拟样本的。logistic回归,是对取值为0或1的布尔值的模拟。logistic回归中使用的函数的值域为[0, 1],可以视为布尔输出为1的一个概率值。
已知包含
m
个元素的的训练集合被表示为
问题是,如何选择合适的
θ
使得
hθ
能够较好地拟合训练集?
选择之一:使用方差来定义代价函数。代价函数用于描述拟合函数的输出与训练集中给定输出之间的不同。方差代价函数定义如下。
J(θ)=1mΣmi=1(hθ(x(i))−y(i))2
。
但是,这种定义会面临一个问题,也就是
J(θ)
可能是一个非凸函数。而一般情况下,凸函数会是一个更好的选择。换句话说,在logistic回归中,其代价函数与线性回归的不同。
假设训练集中只有一个元素,那么当
y=1
时,上述代价函数将被简化为:
J(θ)=(hθ(x)−1)2
。
也就是说,当
hθ(x)
趋近于期待值1时,其代价函数的值趋近于0。
当
hθ(x)
趋近于错误的值0时,其代价函数的之趋近与1。代价函数的曲线如下图所示。
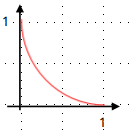
我们可以选择新的代价函数,使之具有下述属性。
若样本中期待值为1,则:
hθ(x)→1,J(θ)→0
;
hθ(x)→0,J(θ)→∞
。
此时代价函数的曲线如下图所示。
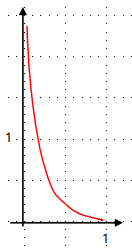
若样本中期待值为0,则:
hθ(x)→0,J(θ)→0
;
hθ(x)→1,J(θ)→∞
。
新的代价函数的数学定义如下。
若
y=1,cost(hθ(x),y)=−loghθ(x)
若
y=0,cost(hθ(x),y)=−log(1−hθ(x))
使用一个统一的函数来定义,代价如下(对于训练样本集中的单个元素)。
cost(hθ(x),y)=−yloghθ(x)−(1−y)log(1−hθ(x))
对于整个样本集而言,代价函数的定义如下。
J(θ)=1mcost(hθ(x(i),y(i))
=−1m[Σmi=1y(i)loghθ(x)+(1−y(i))log(1−hθ(x(i)))]
其中,
hθ
是取值为[0, 1],用来拟合样本所对应函数的函数,被定义为如下形式。















 9226
9226
评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








