







RNN(Recurrent Neural Network), LSTM(Long Short-Term Memory)与GRU(Gated Recurrent Unit)都是自然语言处理领域常见的深度学习模型。本文是一个关于这些模型的笔记,依次简单介绍了RNN, LSTM和GRU。在学习了大量的语言样本,从而建立一个自然语言的模型之后,可以实现下列两种功能。
- 可以为一个句子打分,通过分值来评估句子的语法和语义的正确性。这个功能在机器翻译系统中非常有用。
- 可以造句,能够模仿样本中语言的文风造出类似的句子。
RNN
RNN的定义
在传统的神经网络中,输入是相互独立的,但是在RNN中则不是这样。一条语句可以被视为RNN的一个输入样本,句子中的字或者词之间是有关系的,后面字词的出现要依赖于前面的字词。RNN被称为并发的(recurrent),是因为它以同样的方式处理句子中的每个字词,并且对后面字词的计算依赖于前面的字词。一个典型的RNN如下图所示。
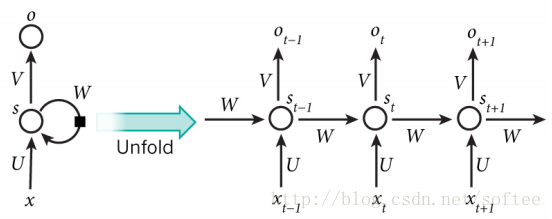
图中左边是RNN的一个基本模型,右边是模型展开之后的样子。展开是为了与输入样本匹配。假若输入时汉语句子,每个句子最长不超过20(包含标点符号),则把模型展开20次。
- xt 代表输入序列中的第 t 步元素,例如语句中的一个汉字。一般使用一个one-hot向量来表示,向量的长度是训练所用的汉字的总数(或称之为字典大小),而唯一为1的向量元素代表当前的汉字。
-
st 代表第 t 步的隐藏状态,其计算公式为st=tanh(Uxt+Wst−1) 。也就是说,当前的隐藏状态由前一个状态和当前输入计算得到。考虑每一步隐藏状态的定义,可以把 st 视为一块内存,它保存了之前所有步骤的输入和隐藏状态信息。 s−1 是初始状态,被设置为全0。 - ot 是第 t 步的输出。可以把它看作是对第
t+1 步的输入的预测,计算公式为: ot=softmax(Vst) 。可以通过比较 ot 和 xt+1 之间的误差来训练模型。 - U,V,W 是RNN的参数,并且在展开之后的每一步中依然保持不变。这就大大减少了RNN中参数的数量。
假设我们要训练的中文样本中一共使用了3000个汉字,每个句子中最多包含50个字符,则RNN中每个参数的类型可以定义如下。
- xt∈R3000 ,第 t 步的输入,是一个one-hot向量,代表3000个汉字中的某一个。
-
ot∈R3000 ,第 t 步的输出,类型同xt 。 - st∈R50 ,第 t 步的隐藏状态,是一个包含50个元素的向量。RNN展开后每一步的隐藏状态是不同的。
-
U∈R50∗3000 ,在展开后的每一步都是相同的。 - V∈R3000∗50 ,在展开后的每一步都是相同的。
- W∈R50∗50 ,在展开后的每一步都是相同的。
其中 xt 是输入, U,V,W 是参数, st 是由输入和参数计算所得到的隐藏状态,而 ot 则是输出。 st 和 ot 的计算公式已经给出,为清晰起见,重新写出。
- st=tanh(Uxt+Wst−1)
- ot=softmax(Vst)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1839
1839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









