









概要:里面有gpu安装方法,如果机器没有gpu,可以忽略该步骤。其中安装到calico和dashboard的时候,需要到阿里云下载相关镜像,再docker tag回来。里面有个小问题,nodePort设置不成功。
在开始下面的步骤前,Gemfield假设你所有的Ubuntu Server机器已经ready,并且设置好了hostname,并且如果有NVIDIA GPU卡的,相关的驱动已经安装就绪。可以使用下面的命令来安装Nvidia驱动:
gemfield@ai05:~$ sudo apt install ubuntu-drivers-common -y
gemfield@ai05:~$ sudo ubuntu-drivers devices
gemfield@ai05:~$ sudo ubuntu-drivers autoinstall在Gemfield的机器上,安装好的Nvidia驱动版本如下所示:
gemfield@ai05:~$ nvidia-smi
Thu May 7 16:24:27 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64 Driver Version: 440.64 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 208... Off | 00000000:01:00.0 Off | N/A |
| 27% 38C P8 1W / 250W | 21MiB / 11018MiB | 0% Default |
+-------------------------------+----------------------+----------------------+前置步骤
1,确保禁止掉swap分区
K8s的要求,在每个宿主机上执行:
gemfield@ai05:~$ sudo swapoff -a
#修改/etc/fstab,注释掉swap那行,持久化生效
gemfield@ai05:~$ sudo vi /etc/fstab2,确保时区和时间正确
每个宿主机上都要确保时区和时间是正确的。
如果时区不正确,请使用下面的命令来修改:
gemfield@ai05:~$ sudo timedatectl set-timezone Asia/Shanghai
#修改后,如果想使得系统日志的时间戳也立即生效,则:
gemfield@ai05:~$ sudo systemctl restart rsyslog 3,确保每个机器不会自动suspend(待机/休眠)
因为是做服务器用途的嘛,之前在Ubuntu 18.04上是没遇到过这个问题的,但是不知怎么回事,在Ubuntu 20.04上遇到了这个自动suspend的问题:
May 7 11:44:32 ai05 NetworkManager[838]: <info> [1588823072.3956] manager: sleep: sleep requested (sleeping: no enabled: yes)
May 7 11:44:32 ai05 gnome-shell[1603]: Screen lock is locked down, not locking
May 7 11:44:32 ai05 NetworkManager[838]: <info> [1588823072.3974] manager: NetworkManager state is now ASLEEP
May 7 11:44:32 ai05 systemd[1]: Reached target Sleep.
May 7 11:44:32 ai05 systemd[1]: Starting Suspend...
May 7 11:44:32 ai05 systemd-sleep[27086]: Suspending system...
May 7 11:44:32 ai05 kernel: [ 2426.233326] PM: suspend entry (deep)
May 7 11:44:32 ai05 kernel: [ 2426.252253] Filesystems sync: 0.018 seconds解决这个问题没有标准答案,可以在BIOS里设置?在kernel启动参数设置?在Gnome图形界面上设置?在网卡相关的命令上设置?Gemfield使用的下面的命令,姑且是起作用了:
sudo systemctl mask sleep.target suspend.target hibernate.target hybrid-sleep.target4,设置iptables可以看到bridged traffic
先确认Linux内核加载了br_netfilter模块:
lsmod | grep br_netfilter确保sysctl配置中net.bridge.bridge-nf-call-iptables的值设置为了1。
在Ubuntu 20.04 Server上,这个值就是1。如果你的系统上不一致,使用下面的命令来修改:
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sudo sysctl --system5,设置rp_filter的值
每个宿主机上执行。
因为Gemfield的K8s集群即将部署的是calico网络插件,而calico需要这个内核参数是0或者1,但是Ubuntu20.04上默认是2,这样就会导致calico插件报下面的错误(这是个fatal级别的error):
int_dataplane.go 1035: Kernel's RPF check is set to 'loose'. \
This would allow endpoints to spoof their IP address. \
Calico requires net.ipv4.conf.all.rp_filter to be set to 0 or 1. \
If you require loose RPF and you are not concerned about spoofing, \
this check can be disabled by setting the IgnoreLooseRPF configuration parameter to 'true'.使用下面的命令来修改这个参数的值:
#修改/etc/sysctl.d/10-network-security.conf
gemfield@ai05:~$ sudo vi /etc/sysctl.d/10-network-security.conf
#将下面两个参数的值从2修改为1
#net.ipv4.conf.default.rp_filter=1
#net.ipv4.conf.all.rp_filter=1
#然后使之生效
gemfield@ai05:~$ sudo sysctl --system开始安装基础软件
1,安装Docker
目前Ubuntu 20.04上没有docker官方提供的安装包,但是Ubuntu有,使用下面的命令来安装Docker吧:
gemfield@ai05:~$ sudo apt update
gemfield@ai05:~$ sudo apt install docker.io
gemfield@ai05:~$ sudo systemctl start docker
gemfield@ai05:~$ sudo systemctl enable docker要在以前,我是不推荐这么做的,因为Ubuntu提供的docker包特别旧;现在不一样了,Ubuntu提供的这个包也很新(目前是docker 19.03)。
2,安装Nvidia-docker2(可选,只有想使用NVIDIA CUDA设备的时候)
目前是支持Ubuntu20.04的。使用下面的命令来进行安装:
gemfield@ai05:~$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
gemfield@ai05:~$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
gemfield@ai05:~$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
gemfield@ai05:~$ sudo apt-get update
gemfield@ai05:~$ sudo apt-get install nvidia-docker2保证网络正常,否则可能会出现如下错误:
gemfield@ai05:~$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
[sudo] password for gemfield:
gpg: no valid OpenPGP data found.然后设置nvidia-docker runtime:
#修改/etc/docker/daemon.json文件如下所示:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}然后执行:
gemfield@ai05:~$ sudo pkill -SIGHUP dockerd
#或者
gemfield@ai05:~$ sudo systemctl restart docker开始安装K8s master
以下的操作只在master宿主机上执行,适合中国大陆地区使用(因为弃用谷歌的源和repo,转而使用阿里云的镜像):
1,安装kubeadm kubeadm kubectl
gemfield@master:~$ sudo apt-get update && sudo apt-get install -y ca-certificates curl software-properties-common apt-transport-https curl
gemfield@master:~$ curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
gemfield@master:~$ sudo tee /etc/apt/sources.list.d/kubernetes.list <<EOF
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
gemfield@master:~$ sudo apt-get update
gemfield@master:~$ sudo apt-get install -y kubelet kubeadm kubectl
gemfield@master:~$ sudo apt-mark hold kubelet kubeadm kubectl2,初始化master
注意,这里使用了阿里云的镜像,然后使用了非默认的CIDR(一定要和宿主机的局域网的CIDR不一样!勿谓言之不预也!)
gemfield@master:~$ sudo kubeadm init --pod-network-cidr 172.16.0.0/16 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers上面的命令执行成功后,会输出一条和kubeadm join相关的命令,后面加入worker node的时候要使用。另外,给自己的非sudo的常规身份拷贝一个token,这样就可以执行kubectl命令了:
gemfield@master:~$ mkdir -p $HOME/.kube
gemfield@master:~$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
gemfield@master:~$ sudo chown $(id -u):$(id -g) $HOME/.kube/config3,安装calico插件
下载calico的k8s yaml文件,修改里面的CALICO_IPV4POOL_CIDR的值来避免和宿主机所在的局域网段冲突(gemfield就是把原始的192.168.0.0/16 修改成了172.16.0.0/16):
#下载 https://docs.projectcalico.org/v3.11/manifests/calico.yaml
#修改CALICO_IPV4POOL_CIDR,然后
gemfield@master:~$ kubectl apply -f calico.yaml等待着所有的pod都ready吧,有问题评论留言;
安装K8s worker节点
在每个worker宿主机上,执行上面初始化master最后输出的命令,在Gemfield的集群上,看起来是这样:
gemfield@ai05:~$ kubeadm join 192.168.0.95:6443 --token jejfa8.ucmaee76674pz6iv \
--discovery-token-ca-cert-hash sha256:05a3870ed36fece1df131f7597b2c04f331c2f97034fe15f7ca2a2999253a776安装nvidia device plugin(可选,只有当你想使用nvidia cuda时)
在所有的worker节点都加入到K8s cluster后,再安装nvidia k8s device plugin:
https://github.com/NVIDIA/k8s-device-plugingithub.com
kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/1.0.0-beta6/nvidia-device-plugin.yml写本文的时候,该plugin的版本是1.0.0-beta6。
成功后,可以看到GPU的资源:http://nvidia.com/gpu: 1
gemfield@master:~$ kubectl describe node ai05 | grep -i -B 7 GPU
Hostname: ai05
Capacity:
cpu: 8
ephemeral-storage: 479667880Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32817992Ki
nvidia.com/gpu: 1
pods: 110
Allocatable:
cpu: 8
ephemeral-storage: 442061917477
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32715592Ki
nvidia.com/gpu: 1
--
Resource Requests Limits
-------- -------- ------
cpu 250m (3%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 0 0安装K8s dashboard
使用下面的命令:
https://github.com/kubernetes/dashboardgithub.com
gemfield@master:~$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml但是这样的方式启动的dashboard访问会不太方便,Gemfield(以前CivilNet项目就这么干的)更改了yaml中的service暴露端口的方式:
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 17030
targetPort: 8443
type: NodePort
externalIPs:
- 192.168.0.95
selector:
k8s-app: kubernetes-dashboard这样就可以直接在浏览器里访问了。
然后使用的yaml创建admin-user:
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard再使用下面的yaml绑定一个role,这里是cluster-admin的role,集群管理者:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard然后获取登录所需的token,使用下面的命令获取:
gemfield@master:~$ kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')然后访问网址,输入token登录。
安装Ingress
K8s的ingress controller有很多种实现:https://kubernetes.io/docs/concepts/services-networking/ingress-controllers/ 。但是K8s官方支持和维护的是GCE和NGINX两种controller。这里Gemfield安装的是NGINX ingress controller,可以参考
Bare-metal considerationskubernetes.github.io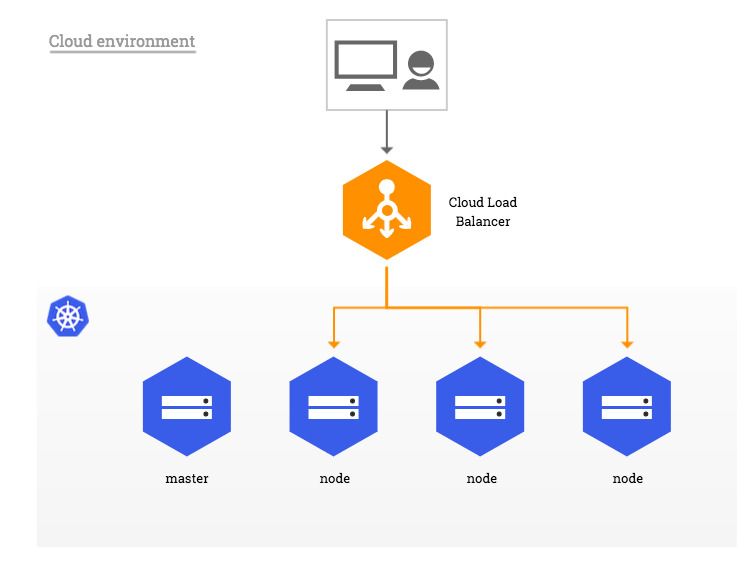
到Gemfield本文的时候,Nginx ingress 的版本已经到了0.32,使用下面的命令来进行安装:
gemfield@master:~$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-0.32.0/deploy/static/provider/baremetal/deploy.yaml注意:这个yaml文件默认使用了NodePort的方式来暴露服务,而Nginx ingress contoller一共支持以下的方式:
- MetalLB
- NodePort
- host network
- self-provisioned edge
- External IPs
Gemfield使用了NodePort + External IP的方式,需要修改该yaml文件中name为ingress-nginx-controller的service(可见由CivilNet添加了externalIPs字段):
apiVersion: v1
kind: Service
metadata:
labels:
helm.sh/chart: ingress-nginx-2.0.3
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/version: 0.32.0
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: controller
name: ingress-nginx-controller
namespace: ingress-nginx
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: http
- name: https
port: 443
protocol: TCP
targetPort: https
externalIPs:
- 192.168.0.95
- 192.168.0.34
selector:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/component: controller如何移除一个节点
使用下面的命令:
gemfield@ai05:~$ kubectl drain ai05 --delete-local-data --force --ignore-daemonsets
gemfield@ai05:~$ kubectl delete node ai05然后在被移除的节点上(比如,ai05)执行:
gemfield@ai05:~$ kubeadm reset但是这样只是清理了K8s相关的目录和配置,已有的iptables rules 或者 IPVS tables或者路由表信息并没有被清理,你需要使用相关的命令来清理。
如果要移除master,也就是整个k8s,则在master上:
gemfield@master:~$ kubeadm reset

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









