






目录
1. Q-Learning简介
行动准则:好的行为能够获得奖励,不好的行为会获得惩罚。
假设你有两个选择:写作业和看电视。你选择连续看电视,被爸妈发现打屁股。你吸取了惨痛的教训,第二次持续认真的写作业。

举例,之前没有写过作业,所以没有任何经验。第一个状态可选择写作业也可以选择看电视。假设第一个状态是写作业,写一会儿就去看电视了,这时候状态由写作业变为了看电视,直到父母回来发现我在看电视,然后把我痛打了一顿,我记住了这次教训。

假设我们的行为准则已经学习好了。
2. Q表
Q-learning有一个Q表,如图所示:

表中是每一个状态(s1,s2,……)以及所对应的所有动作(a1,a2,……)的“Q值”,Q值可以表示当前状态下选择对应动作的回报。
Q表的作用是什么呢?
假设Q表已经存在,我们选择初始状态为s1(放学回家),动作的选择则是Q表中s1状态对应Q值最大的动作a2(写作业),然后自动转移到状态s2(写作业中),再次根据Q表选择动作a2(写作业)……以此往复。
下面,我们来看下下面这张表是通过什么方式更新的。
3. Q表的更新
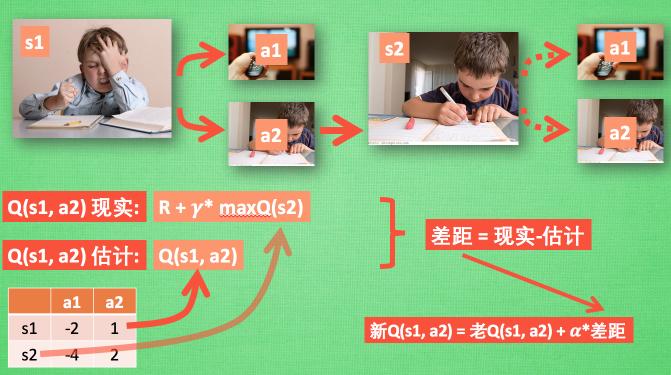
还是上面的过程,当我们通过Q表(左下角)选择动作a2后,到达s2状态。达到s2后,我们并没有采取实际的行动。想象一下处于s2的状态时,会采取的每种行动。
上图中maxQ(s2)其实是Q(s2,a2),即当前状态可能达到的最大Q值,它是在还未采取第二次行动之前做的估计,γ是衰减因子,表达的是未来值对现在影响的大小。R表示状态s1下选择动作a2的立即奖励(假设现在R为0,因为还没写完作业不能给奖励),得到真实的Q(s1,a2)值。Q表中原来的值即为估计值,差距(也就是需要调整的部分)=真实Q值-原来Q值。
最后更新的Q值 = 原来的Q值 + α∗差距,其中α为学习率(影响学习速度)。
注意:maxQ(s2)是在s2做出下一步动作之前的值。
4.Q-Learning算法

说明,s是当前所处的状态,a是s状态下执行的动作,执行完动作a的状态可能会变成(还没有真正变成
状态),在可能的
状态下又可能执行动作
。
有趣的是,Q(s1,a2)的现实值实际上包含Q(s2)的最大估计(Q(s2,a2)估计),将对下一步衰减的最大估计和当前所获得的奖励当成这一步的现实(指上图中的),更新过程就是上面所描述的过程。
算法第5行,状态s选择动作a时,使用的是ϵ−greedy方法,比如ϵ=0.9,就有0.9的概率选择最大Q值动作,但是也有0.1的概率选择任意的其他动作,目的是加入一定随机性,遵循广泛采样的原则。
是学习效率,决定这次有多少误差要被学习。
是一个小于1的数字。
γ是对未来奖励的衰减值。
5.衰减因子γ

如上图所示,Q(s1)的估计不仅仅只有s2这个状态,按照同样的规则持续展开,可以发现,其与后续状态s3、s4……都有关系,这些都能够用来估计实际Q值。
当γ=1时,相当于完全考虑未来的奖励,没有忽略。能够看清楚未来行为的所有价值。
当γ⊆(0,1)时,数值越大,对未来情况的重视程度越大,可以说智能体越有“远见”。
当γ=0时,完全不考虑将来的情况,只有当前的回报值。看不到未来行为的奖励。














 3083
3083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









