







一、搜索引擎
1、概述
搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,
在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。
搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
搜索引擎其实实现就两步:搜索引擎就是数据的搬运工
1, 从整个互联网获取数据,
2, 根据用户的查询需求,从自己的数据列表中取得对应的数据,返回给用户
2、原理
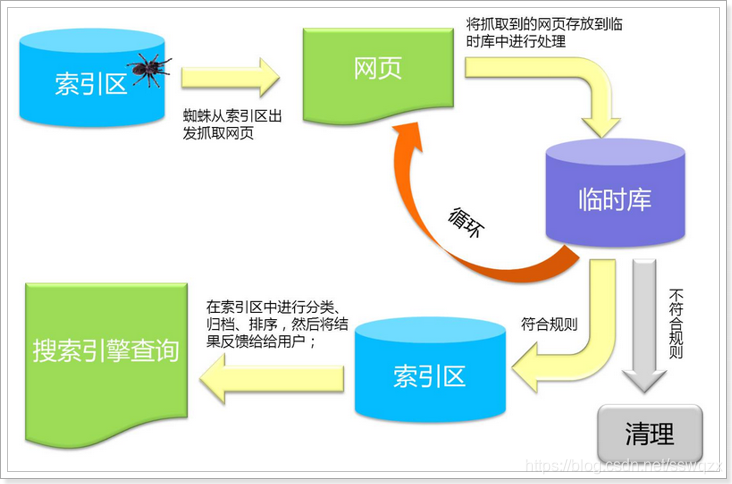
3、应用场景
大型综合搜索网站、百度、g.cn、360...
站内搜索、商城、淘宝、招聘网站...
垂直领域搜索
软件内部搜索4、实现搜索技术的方式
方式1: 数据库搜索
利用SQL语句进行模糊搜索:
select * from items where title like “% 小 米 %”;
问题:
1) 在数据量很大的情况下,模糊搜索不一定走索引,因此效率就会很低。
2) 同时,模糊搜索的关键词不能任意输入,否则无法模糊的搜索到任何结果。
方式2: Lucene/Elasticsearch技术
全文检索,解决在海量数据的情况下,利用倒排索引技术(分词),实现快速的搜索、打分、排序等功能
5、倒排索引技术
文档(Document):
一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,
相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。
再比如一封邮件,一条短信,一条微博也可以称之为文档。在本书后续内容,很多情况下会使用文档来表征文本信息。文档集合(Document Collection):
由若干文档构成的集合称之为文档集合。比如海量的互联网网页或者说大量的电子邮件都是文档集合的具体例子。文档编号(Document ID):
在搜索引擎内部,会将文档集合内每个文档赋予一个唯一的内部编号,以此编号来作为这个文档的唯一标识,
这样方便内部处理,每个文档的内部编号即称之为“文档编号”,后文有时会用DocID来便捷地代表文档编号。单词编号(Word ID):
与文档编号类似,搜索引擎内部以唯一的编号来表征某个单词,单词编号可以作为某个单词的唯一表征。倒排索引(Inverted Index):
倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,
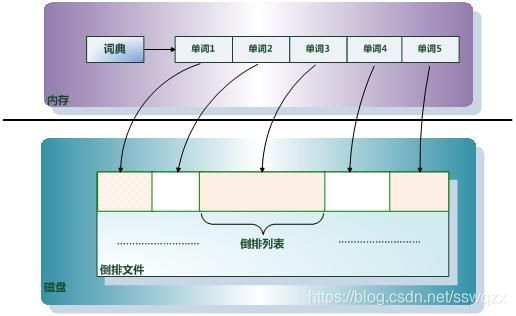
可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。单词词典(Lexicon):
搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,
单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。倒排列表(PostingList):
倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,
每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。倒排文件(Inverted File):
所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。图解:
6、创建倒排索引列表
6.1、创建文档列表
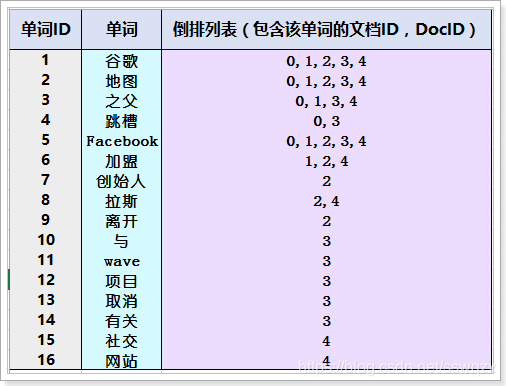
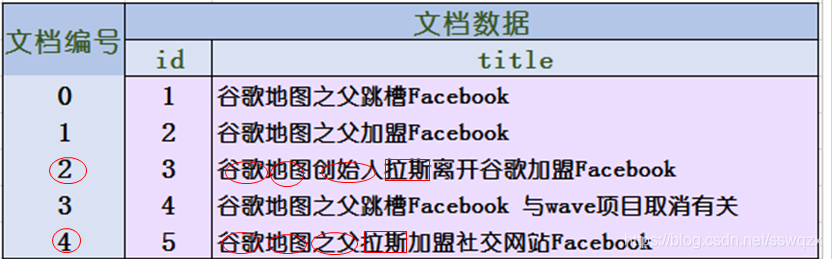
如图:文档集合(列表)包含五个文档,每个文档内容如图3-3所示,在图中最左端一栏是每个文档对应的文档编号。我们的任务就是对这个文档集合建立倒排索引。 lucene首先对原始文档数据进行编号(DocID),形成列表,就是一个文档列表

6.2、创建简单的倒排索引
对文档中数据进行分词、得到词条。对词条进行编号,以词条创建索引。然后记录下包含该词条的所有文档编号(及其它信息)
如图,“单词ID”一栏记录了每个单词的单词编号,第二栏是对应的单词,第三栏即每个单词对应的倒排列表。
比如单词“谷歌”,其单词编号为1,倒排列表为{1,2,3,4,5},说明文档集合中每个文档都包含了这个单词。如图:
6.3、创建带有单词频率信息的倒排索引
《稍复杂的带有单词频率信息的倒排索引》
倒排索引还可以记载更多的信息,如下图所示索引系统除了记录文档编号和单词频率信息外,
额外记载了两类信息,即每个单词对应的“文档频率信息”(对应图的第三栏)以及在倒排列表中记录单词在某个文档出现的位置信息。
如下图:编号8—拉斯—{(3:1);(5,1)}来说,(3,1)表示“拉斯”在文档3中出现一次,(5,1)表示“拉斯”在文档5中出现1次

《更实用完善的倒排索引》
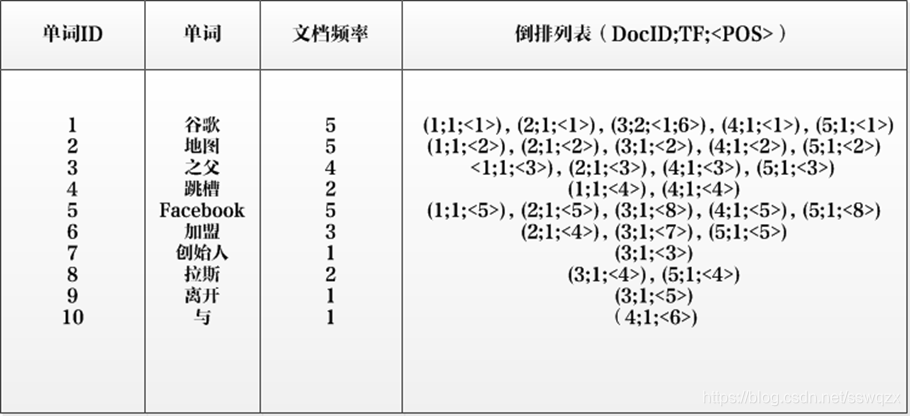
如上图:以单词“拉斯”为例,其单词编号为8,文档频率为2,代表整个文档集合中有两个文档包含这个单词,对应的倒排列表为:{(3;1;<4>),(5;1;<4>)},其含义为在文档3和文档5出现过这个单词,单词频率都为1,单词“拉斯”在两个文档中的出现位置都是4,即文档中第四个单词是“拉斯
二、Lucene概述
1、概述
官网:http://lucene.apache.org/ (下载地址)
Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供。
Lucene提供了一个 简单 却 强大 的应用程序接口(API),能够做全文索引和搜寻
,在Java开发环境里Lucene是一个成熟的免费开放源代码工具
Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品
2、全文检索
全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理 [1] 是计算机索引程序通过扫描文章中的每一个词,
对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,
检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
总结:Lucene全文检索就是对文档中全部内容进行分词、然后对所有单词建立倒排索引的过程3、Lucene与Solr的关系
Lucene:一套实现了全文检索的底层API、
Solr:基于Lucene开发的企业级搜索应用服务器














 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









