







前言
本文介绍几种java常用的线程池如:FixedThreadPool,ScheduledThreadPool,CachedThreadPool等线程池,并分析介绍Executor框架,做到“知其然”:会用线程池,正确使用线程池。并且“知其所以然”:了解背后的基本原理。
转载请指明原处:
http://blogs.xzchain.cn
1.Executor
Executor是java SE5的java.util.concurrent包下的执行器,用于管理Thread对象,它帮程序员简化了并发编程。与客户端直接执行任务不同,Executor作为客户端和任务执行之间的中介,将任务的提交和任务的执行策略解耦开来,Executor允许我们管理异步任务的执行。
Executor的实现思想基于生产者-消费者模型,提交任务的线程相当于生产者,执行任务的工作线程相当于消费者,这里所说的任务即我们实现Runnable接口的类。
Executor关键类图如下:
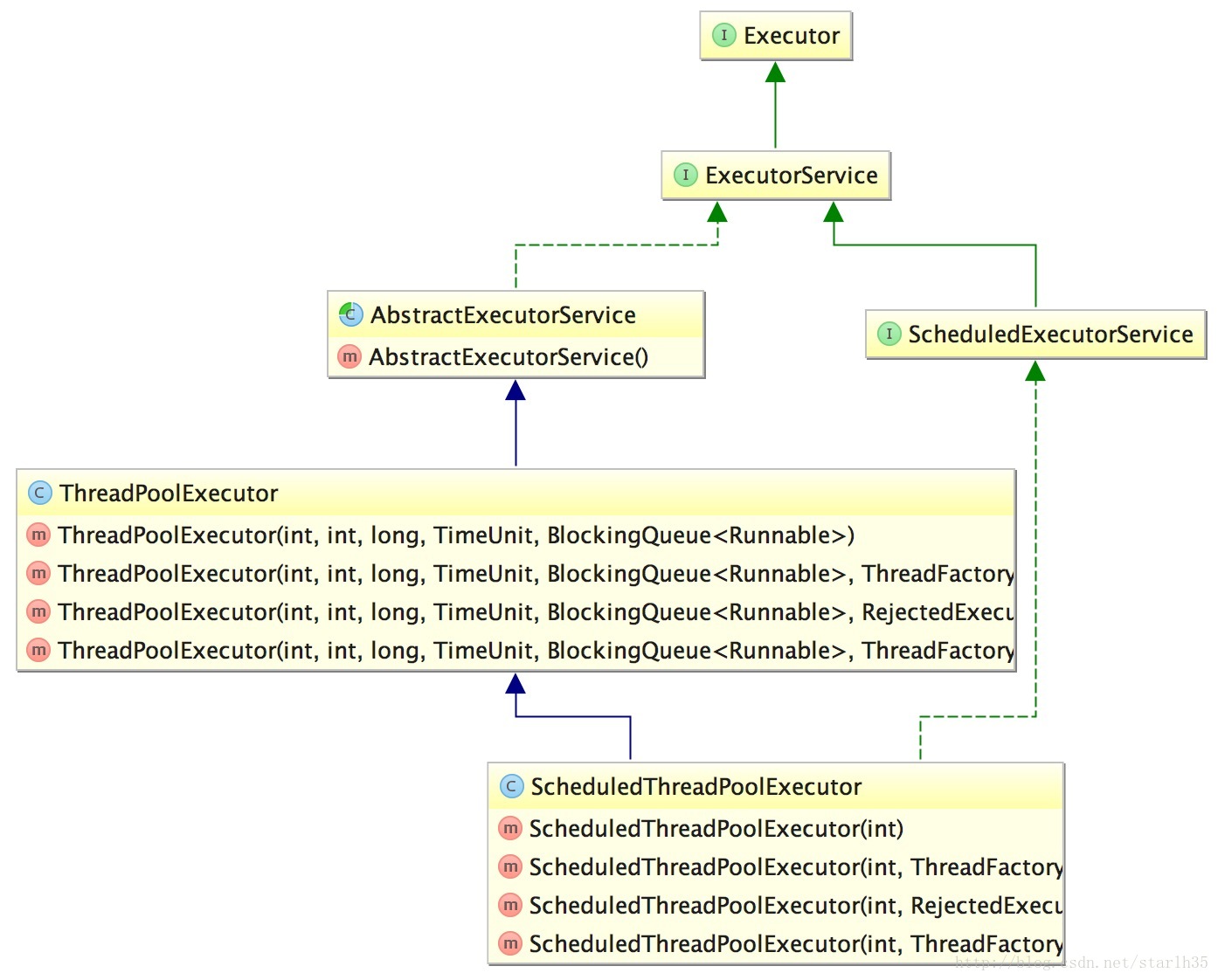
根据这个类图,详细分析一下其中的门路:
- Executor:该接口定义了一个 void execute(Runnable command)方法,用来接受任务。
- ExecutorService:继承了Executor并对其进行了丰富的拓展,提供了任务生命周期管理相关的方法,如shutdown(),shutdownNow()等方法,并提供了追踪一个或者多个异步任务执行状况并返回Future的方法,如submit(),invokeAll()方法
- AbstractExecutorService:ExecutorService的默认实现类,该类是一个抽象类。
- ThreadPoolExecutor:继承了AbstractExecutorService并实现了其方法,可以通过Executors提供的静态工厂方法创建线程池并返回ExecutorService实例
- ScheduledExecutorService:提供定时调度任务的接口
- ScheduledThreadPoolExecutor:ScheduledExecutorService的实现类,提供可定时调度任务的线程池。
2.ThreadPoolExecutor
根据上面的类图,我们详细看下ThreadPoolExecutor提供的构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
//略 ……
}参数介绍:
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached参数说明:
- corePoolSize:核心线程数/基本线程数,没有任务执行时线程池的大小(在创建ThreadPoolExecutor时,线程不会立即启动,有任务提交时才会启动)
- maximumPoolSize:最大线程数,允许的创建的线程数
- keepAliveTime:线程存活时间,当某个线程的空闲时间超过了存活时间,将被标记为可回收的,如果此时线程池的大小超过了corePoolSize,线程将被终止。
- TimeUnit:keepAliveTime的单位,可选毫秒,秒等
- workQueue:保存任务的阻塞队列,主要有三种:有界队列,无界队列和同步移交队列(Synchronous Handoff)。下面将详细说明
- threadFactory(可选):在Executor创建新线程的时候使用,默认使用defaultThreadFactory创建线程
- handler:定义“饱和策略”,这里的饱和根据参数说明是指线程池容量(workQueue也满了)满了的时候,会使用饱和策略进行任务的拒绝。默认的策略是“Abort”即中止策略,该策略抛出RejectExecutorException异常,其他的策略有“抛弃(Discard)、抛弃最旧(Discard-Oldest)”等。
很多人有疑问这些参数的含义到底是什么,网上的解释也五花八门,这里我通俗的解释一下,当提交一个任务的时候,会先检查当前执行的线程数,如果当前执行的线程数小于基本线程数(corePoolSize),则直接创建线程执行任务,且这个线程属于core线程。如果当前执行的线程数大于等于基本线程数,该任务会被放到阻塞队列(workQueue)中,在阻塞队列里的任务会复用core线程,即阻塞队列里的任务会等待core线程提取执行。而当阻塞队列是有界队列时,在阻塞队列满了的时候,会创建新的线程来执行任务,这些新的线程是非core线程,满足keepAliveTime的时候会被销毁,而已经进入队列里的任务会继续由已有的全部线程来执行。超过最大线程时(maximumPoolSize),会使用我们定义的“饱和策略”来处理。
这里面其实牵扯了另一个问题,即如何实现线程复用,简单来说就是线程在执行任务时,执行完后会去队列里面take新的任务,而take方法是阻塞的,因此线程并不会被销毁,只会不停的执行任务,没有任务时要么根据我们的逻辑销毁要么阻塞等待任务。
3.Executors
有时候使用ThreadPoolExecutor自己创建线程池时由于不清楚如何设置线程池大小,存活时间等问题会导致资源浪费,而ThreadPoolExecutor是一个灵活的、稳定的线程池,允许各种定制。Executors提供了一系列的静态工程方法帮我们创建各种线程池。
newFixedThreadPool
newFixedThreadPool创建可重用且线程数量固定的线程池,当线程池所有线程都在执行任务时,新的任务会在阻塞队列中等待,当某个线程因为异常而结束,线程池会创建新的线程进行补充。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}newFixedThreadPool使用基于FIFO(先进先出)策略的LinkedBlockingQueue作为阻塞队列。
newSingleThreadPool
newSingleThreadPool使用单线程的Executor,其中corePoolSize和maximumPoolSize都为1,固定线程池大小为1。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}newScheduledThreadPool
newScheduledThreadPool创建可以延迟执行或者定时执行任务的线程池,使用延时工作队列DelayedWorkQueue。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}newCachedThreadPool
newCachedThreadPool是一个可缓存的线程池,线程池中的线程如果60s内未被使用将被移除。使用同步队列SynchronousQueue。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}关于同步队列SynchronousQueue
回想一下,newSingleThreadPool,newFixedThreadPool默认使用无界队列LinkedBlockingQueue,当任务执行速度远远低于新任务到来的速度时,该队列将无限增加,如果我们使用有界队列例如ArrayBlockingQueue,当队列填满后则需要完善的饱和策略,这里需要根据需求选取折中之道。
这里就引出了SynchronousQueue,对于非当大的或者无界的线程池,使用SynchronousQueue可以避免排队,它可以讲任务直接从生产中交给工作者线程,SynchronousQueue本质上不是一个队列,而是一种同步移交机制,要将一个任务放入SynchronousQueue时必须要有一个线程在等待接受,如果没有线程在等待且当前线程数大于最大值,将启用饱和策略拒绝任务。
总结:newSingleThreadPool使用单线程的Executor,newFixedThreadPool设置线程池的基本大小和最大大小为指定的值,而且创建的线程池不会超时。newCachedThreadPool将线程池的最大大小设置为Integer.MAX_VALUE(即2的31次方减1),基本大小为0,超时时间为1分钟,该线程池可以无限拓展,且需求降低时会自动收缩。newScheduledThreadPool用于执行定时任务的线程池。其他形式的线程池大家可参考其他资料。
关于线程池大小的问题
线程池的大小取决于提交的任务的类型和系统的性能。
- 如果线程池过大,大量线程将在相对有限的cpu和内存资源上竞争,将导致内存使用量过高,耗尽资源
- 如果线程池太小,空想的处理器资源无法有效利用,降低了吞吐率。
为了正确设置线程池大小需要考虑系统的CPU数,内存容量,任务类型(是计算密集型还是io密集型或是二者皆可),任务是否需要稀缺资源(如jdbc连接)
对于计算密集型任务,在拥有N个处理器的系统上,最佳线程池的大小为N+1。这个额外的线程保证了突发情况下CPU时钟周期不会浪费。对于包含IO操作或者其他阻塞操作的任务,由于线程不会一直执行,线程池需要更大。
线程池的大小设置最优公式如下:
参数定义:
N = number of CPUs (cpu数量)
U = target CPU utilization,0<= U <= 1 (cpu利用率)
W/C = ratio of wait time to compute time (任务等待时间和计算时间的比值)
那么最优线程池大小计算公式为:
S = N*U*(1+W/C)
其中cpu数可以通过Runtime.getRuntime().availableProcessors()获得
CPU周期只是影响线程池大小的一个主要参数,其他的因素也很重要,需要综合实践。
参考《thinking in java》、《java并发编程实战》















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









