









原本链接:https://www.infoq.cn/article/2uabiqaxicqifhqikeqw
本文,InfoQ梳理了60个2019年至今GitHub上热门的开源工具,献给那些对新征程满怀期待的开发者们。
Flair (顶级 NLP 库)
2018 年是 NLP 井喷的一年。像 ELMo 和谷歌 BERT 这样的库层出不穷,正如 Sebastian Ruder 所言,“NLP 高光时刻已经来临”,并且这种趋势一直延续到了 2019 年。Flair 是另一款出色的 NLP 库,技术先进、简单易懂、操作方便。
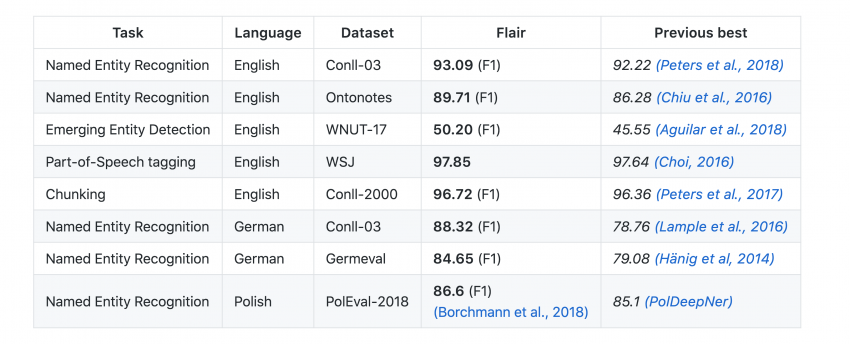
Flair 由 Zalando Research 开发及开源,是基于 Pytorch 的 NLP 框架。Flair 允许用户将最先进的自然语言处理模型应用于文本,例如命名实体识别(NER),词性标注(PoS),意义消歧和分类。
项目地址:https://github.com/flairNLP/flair
face.evoLVe(高性能人脸识别库)
如今,计算机视觉中人脸识别算法在数据科学领域应用极为广泛。face.evoLVe 是一款基于 Pytorch 的“高性能人脸识别库”。为相关人脸分析和应用提供了综合功能,包括:
人脸对齐(人脸检测、特征点定位、仿射变换等);
数据预处理(例如,数据增广、数据平衡、归一化等);
各种骨干网(例如,ResNet、IR、IR-SE、ResNeXt、SE-ResNeXt、DenseNet、LightCNN、MobileNet、ShuffleNet、DPN等);
各种损失函数(例如,Softmax、Focal、Center、SphereFace、CosFace、AmSoftmax、ArcFace、Triplet等等);
提高性能的技巧包(例如,训练改进、模型调整、知识蒸馏等)。

简而言之,该库可以帮助研究人员和工程师快速开发高性能深度人脸识别模型和算法,方便实际使用和开发部署。
项目地址:
https://github.com/ZhaoJ9014/face.evoLVe.PyTorch
YOLOv3
YOLO 是一款超快、超精准目标检测框架。 自发布以来迭代更新的几个版本一次比一次更好。

该库是 YOLOv3 在 TensorFlow 中实现的完整数据管道。它可用在数据集上来训练和评估自己的目标检测模型。其核心亮点包括:
有效的tf.数据管道
重量转换器
极速GPU 非极大值抑制
全训练管道
K-means算法选择Anchor先验框
项目地址:
https://github.com/wizyoung/YOLOv3_TensorFlow
FaceBoxes( 高精度 CPU 实时人脸检测器 )
计算机视觉领域最大的挑战之一就是掌握计算资源,不是每个人都有多个 GPU。
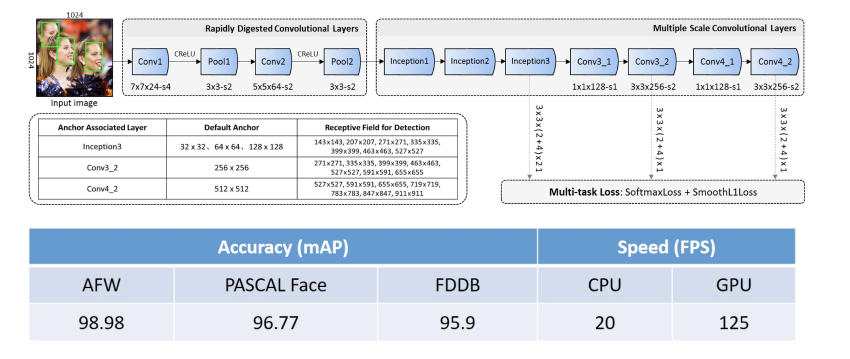
FaceBoxes 是一种新的人脸检测方法,使用 CPU 速度和精准度均表现良好。FaceBoxes 通过 PyTorch 实现。包含安装、训练和评估人脸检测模型的代码。
项目地址:
https://github.com/zisianw/FaceBoxes.PyTorch
Transformer-XL (谷歌 AI 团队开源的 NLP 框架)
Transformer-XL 是由谷歌 AI 团队开源的 NLP 模型 Transformer 的升级版。建模长期依赖关系是 NLP 领域的棘手问题。RNN 和 Vanilla Transformers 也常被用来建模长期依赖关系,但效果都并不理想。谷歌 AI 团队开发的 Transformer-XL 解决了这一问题。这款库的亮点包括:
Transformer-XL学习的长期依赖关系比RNN长约80%,比vanilla长约450%
Transformer-XL在语言建模任务的评估期间比vanilla Transformer快1800多倍。
基于建模长期依赖关系的能力,Transformer-XL在长序列上具有更好的困惑度(在预测样本方面更准确)。
项目地址:https://github.com/kimiyoung/transformer-xl
StyleGAN (生成超逼真人脸)
下图这些人看起来是不是很逼真?但他们其实并不是真人。这些“人脸”都是由 StlyeGAN 算法生成的。近几年 GAN 热度不减,但是 StyleGAN 在某些方面甚至优于 GAN。

虽然 GANs 自发明以来一直在稳步改进,但 StyleGAN 的进程仿佛更快些。开发人员提出了两种新的、自动化方法来量化这些图像的质量,同时也开放了大量高质量的人脸数据集。
关键资源如下:
项目地址:https://github.com/NVlabs/stylegan
GPT-2(OpenAI 语言模型)
OpenAI 今年 11 月终于发布了 15 亿参数完整版本 GPT-2。这款语言模型被不少人认为是 2019 年“最强通用 NLP 模型”。
GPT-2 可以生成连贯的文本段落,刷新了 7 大数据集基准,并且能在未经预训练的情况下,完成阅读理解、问答、机器翻译等多项不同的语言建模任务。
项目地址:https://github.com/openai/gpt-2
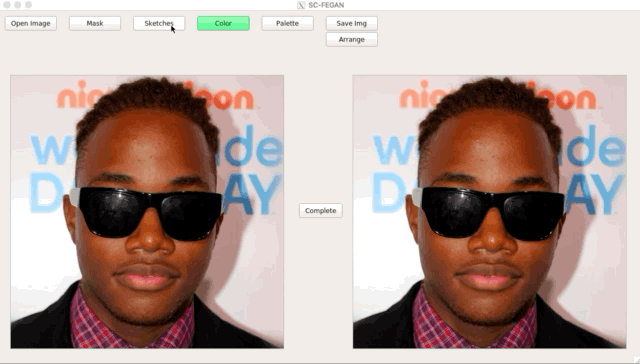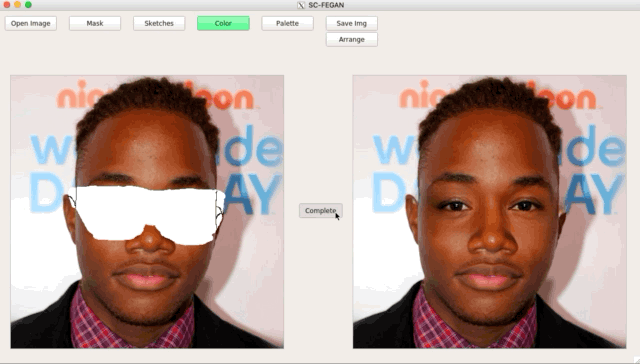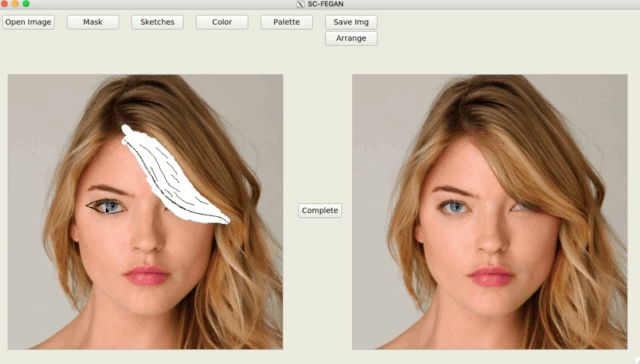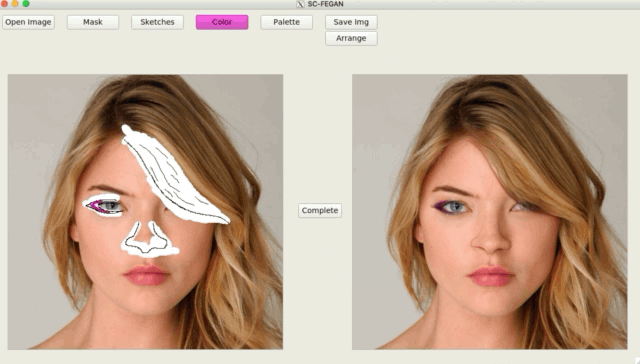
SC-FEGAN (涂鸦人脸编辑生成对抗网络)
SC-FEGAN 听起来像另一款 GAN 库,没错,这的确是基于 GAN 的人脸照片涂鸦编辑。SC-FEGAN 与 StyleGAN 的算法一样出色。
你可以用开发者训练好的深度神经网络来编辑所有类型的人脸照片。SC-FEGAN 非常适合使用直观的用户输入与草图和颜色生成高质量的合成图像。
项目地址:https://github.com/JoYoungjoo/SC-FEGAN
LazyNLP (用于创建海量文本数据集)
LazyNLP 的使用门槛很低——用户可以使用它爬网页、清洗数据或创建海量单语数据集。
据开发者称,LazyNLP 可以让你创建出大于 40G 的文本数据集,比 OpenAI 训练 GPT-2 时使用的数据集还要大。

项目地址:https://github.com/chiphuyen/lazynlp
Subsync 自动将视频与字幕同步
是不是经常会因为字幕与视频不同步而抓狂?这个库能解决这一问题。Subsync 能使字幕与视频自动同步(与哪种语言无关),字幕与视频中的正确起始点对齐。该算法是在 Python 快速傅里叶变换技术上建立的。
Subsync 在 VLC 媒体播放器中同样表现出色。该模型的训练时间只需 20 到 30 秒(取决于视频长度)。
从这样

变成这样

FFHQ:Style-GAN 论文中用于训练生成逼真人脸的数据集,分辨率 1024×1024 的 70,000 张高质量 PNG 图像,在年龄,种族和图像背景方面存在广泛差异。
项目地址:https://github.com/smacke/subsync
FFHQ(用于训练生成逼真人脸的数据集)
Style-GAN 论文中用于训练生成逼真人脸的数据集,包含 7 万张分辨率 1024×1024 的高质量 PNG 图像,各年龄段、各种族人群都有,图像背景也各不相同。

项目地址:https://github.com/NVlabs/ffhq-dataset
BigGAN(BigGAN 的 PyTorch 实现)
不少人对计算机视觉着迷都是因为 GAN。GAN 是几年前由 Ian Goodfellow 发明的,现在已经发展成一个完整的研究体系。

2018 年 DeepMind 提出了 BigGAN 概念,但是等了很久才等到 BigGAN 的 PyTorch 实现。这款库也包含了预训练模型(128×128、 256×256 以及 512×512)。仅需一行代码就可安装:
项目地址:https://github.com/huggingface/pytorch-pretrained-BigGAN
SPADE(英伟达开源的绘图工具)
SPADE 是英伟达(NVIDIA)新开源的绘图工具。利用生成对抗网络,根据几根简单的线条就能生成栩栩如生的图像。

项目地址:https://github.com/NVlabs/SPADE
SiamMask(实时在线目标跟踪与目标分割统一架构)
这款库是基于《Fast Online Object Tracking and Segmentation: A Unifying Approach》论文提出的。
SiamMask 是一款实时在线目标跟踪与目标分割统一框架。技术简单、通用、快速高效。它可以对目标实时跟踪。此款库还包含预训练模型。

项目地址:https://github.com/foolwood/SiamMask
DeepCamera 世界首个自动机器学习深度学习边缘 AI 平台
ARM GPU 上的深度学习视频处理监控,用于人脸识别以及更多方法。将数码相机变成人工智能相机。使用 ARM GPU / NPU 的边缘 AI 生产级平台,利用 AutoML。面向开发人员/儿童/家庭/中小企业/企业/云的第一个世界级边缘人工智能全栈平台,由社区烘焙。
整个 DeepCamera 概念基于自动机器学习(AutoML),所以训练新模型甚至不需要任何编程经验。
主要亮点:
人脸识别
人脸检测
通过移动程序控制
目标检测
运动检测
OpenAI Sparse Transformer (NLP 框架)
Sparse Transformer 是一款预测序列中一下项的深度神经网络。它包含文本、图片甚至音频。该算法使用深度学习中非常流行的注意力机制从序列中提取模式的时长是以前的 30 倍。

OpenAI 提出的这款模型可以使用数百个层对数万个元素的序列进行建模,在多个域中实现先进的性能。
项目地址:https://github.com/openai/sparse_attention
NeuronBlocks (微软 NLP 深度学习工具包)
NeuronBlocks 是一款由微软开发的 NLP 入门工具包。可以帮助数据科学团队创建端到端神经网络通道。这款工具包的设计初衷是为了减少为 NLP 任务创建深度学习网络模型的成本。
CenterNet(使用中心点探测的计算机视觉)
CenterNet 是一种目标探测方法。总体来讲,探测算法是在图像上将目标以轴对称的框形式框出。大多成功的目标检测器都先观察出目标位置,然后对该位置进行分类,这些方法听起来似乎很合理,但是实际上还需要进行后期处理。
CenterNet 这种方法构建模型时将目标作为一个点。基本上讲,检测器采用关键点评估的方式来识别所有框中的中心点。CenterNet 已经被证明比我们从前了解的其他边界框技术更快、更精准。
项目地址:https://github.com/xingyizhou/CenterNet
BentoML(部署模型工具包)
了解并学习如何部署机器学习模型成为数据科学家必须掌握的技能。BentoML 是一款为数据科学家设计的 Python 库,帮助他们包装和部署机器学习模型。这款工具包可以让你在 5 分钟内将笔记本上的模型走向生产 API 服务。BentoML 服务可以很容易地部署到众多主流平台上,例如 Kubernetes、Docker、Airflow、AWS、Azure 等。
项目地址:https://github.com/bentoml/BentoML
InterpretML(微软深度学习可解释性框架)
InterpretML 是由微软开源的用于训练可解释模型和解释黑箱系统的包。可解释性在以下几个方面至关重要:
调试模型:为什么我的模型会出错?
检测偏见:我的模型会区别对待目标吗?
人类与 AI 合作:我怎样才能理解和信任模型的决策?
合规性:我的模型符合法律规定吗?
高风险应用:医疗健康、金融、司法等…
微软研究人员开发可解释增强机(EBM)算法帮助提高可解释性。此 EBM 技术有较高的精准度和可理解性。Interpret ML 不仅局限于使用 EBM 算法,它同样支持 LIME、线性模型和决策树等方法。
可使用下列代码安装 InterpretML:
项目地址:https://github.com/interpretml/interpret
Tensor2Robot (谷歌研究团队开发的存储库)
Tensor2Robot (T2R) 是一款用于大规模深度神经网络训练、评估和推理的库。此存储库包含分布式机器学习和强化学习基础结构。
项目地址:
https://github.com/google-research/tensor2robot
Generative Models in TensorFlow 2 (在 Tensorflow 2 中实现大量生成模型)
这是一个在 Tensorflow 2 中实现大量生成模型的小项目。图层和优化器都是使用 Keras。这些模型是针对两个数据集实现的:fashion MNIST 和 NSYNTH。编写网络的目的是尽可能简单和一致,同时具有可读性。因为每个网络都是自包含在 notebook 中的,所以它们应该可以在 colab 会话中轻松运行。
该存储库包含多个生成模型的 TF 实现,包括:
生成对抗网络(GAN)
自动编码器
变分自动编码器(VAE)
VAE-GAN等
STUMPY(时间序列数据挖掘)
STUMPY 是一个功能强大且可扩展的 Python 库,可用于各种时间序列数据挖掘任务。
STUMPY 旨在计算矩阵轮廓,矩阵轮廓是一个向量,它存储时间序列中任何子序列与其最近邻居之间的 z-normalized 欧几里德距离。
以下是此矩阵配置文件帮助我们执行的一些时间序列数据挖掘任务:
异常发现
语义分割
密度估计
时间序列链(时序有序的子序列模式集)
使用以下代码可以通过 pip 直接安装 STUMPY:
项目地址:https://github.com/TDAmeritrade/stumpy
MeshCNN 通用深度神经网络
MeshCNN 是一款用于 3D 三角网格的通用深度神经网络。这些网格可用于 3D 形状分类或分割等任务。MeshCNN 框架包括直接应用于网格边缘的卷积,池化和解除层:
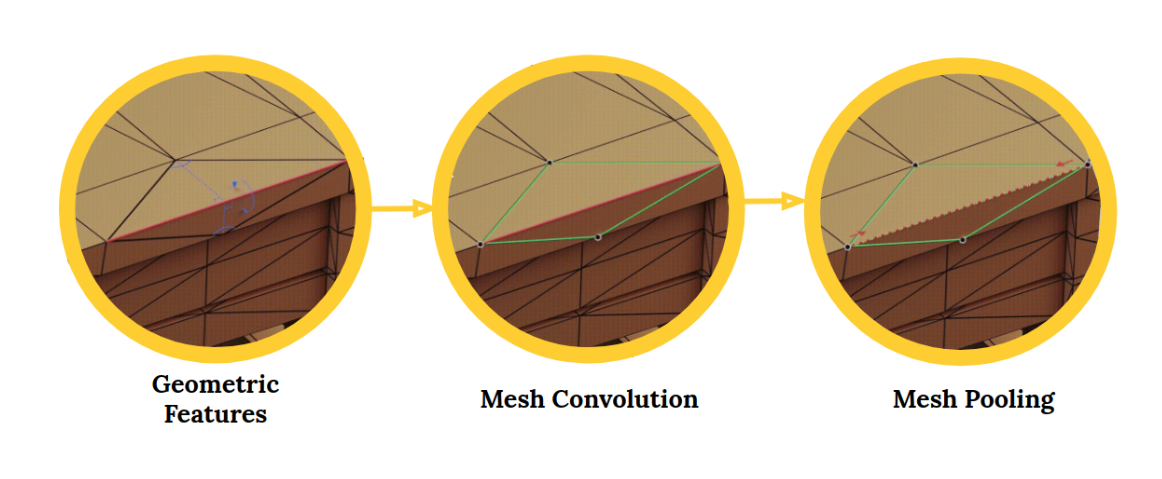
卷积神经网络(CNN)非常适合处理图像和视觉数据。 CNN 近年来风靡一时,随着图像相关应用的涌现而兴起:物体检测、图像分割、图像分类等,随着 CNN 的进步,这些都变成了可能。
项目地址:https://github.com/ranahanocka/MeshCNN
XLNet 大型 NLP 框架
继 BERT 之后,谷歌又推出了一个用于 NLP 框架——XLnet。这是一款以 Transformer-XL 为核心的框架,从论文的结果来看,XLnet 在问答、文本分类、自然语言理解等任务上大幅超越 BERT。开发者放出了预训练模型帮助用户更好地使用 XLNet。
项目地址:https://github.com/zihangdai/xlnet
MMAction 视频动作理解工具包
MMAction 是一个基于 Pytorch 的开源视频动作理解工具包,该工具包采用模块化设计,支持多种流行的物体检测和实例分割算法,并且可以灵活地进行拓展,在速度和显存消耗上也具有优势。
MMAction 可执行下列任务:
在剪辑视频中识别动作;
完整视频中的时序行为检测(通常理解为动作定位);
完整视频中的时空行为检测
项目地址:https://github.com/open-mmlab/mmaction
Keras 实现 CRAFT 文本检测
CRAFT 的主要思路是先检测单个字符(character region score)及字符间的连接关系(affinity score),然后根据字符间的连接关系确定最终的文本行。CRAFT 可以用于处理任意方向文本、 曲线文本、 畸变文本等。

CRAFT 的网络结构与 EAST 的网络结构相似:特征提取主干网络部分采用的是 VGG-16 with batch normalization;特征 decode 模块与 U-Net 相似,也是采用自顶向下的特征聚合方式;网络最终输出两个通道特征图,即 region score map 和 affinity score map。
项目地址:https://github.com/clovaai/CRAFT-pytorch
TRAINS 自动化 AI 实验管理器和版本控制器
TRAINS 能记录和管理多种深度学习研究工作负载,并且几乎不需要集成成本。TRAINS 最大的优点就是它是免费的开源项目。工程师只需要编写两行代码就可以将 TRAINS 完全集成到用户场景中。TRAINS 与现有主要框架无缝集成,包括:PyTorch、TensorFlow、Keras 等,并支持 Jupyter 笔记本。
可按照如下代码安装 TRAINS:
添加可选的云存储支持(S3/GoogleStorage/Azure):
将下列两行代码添加到你的代码中:
项目地址:https://github.com/allegroai/trains
谷歌研究足球环境
“谷歌研究足球环境”是一款由谷歌研究团队开发足球游戏。这款游戏可以用于训练人工智能技术系统,让它能够解决复杂的任务。
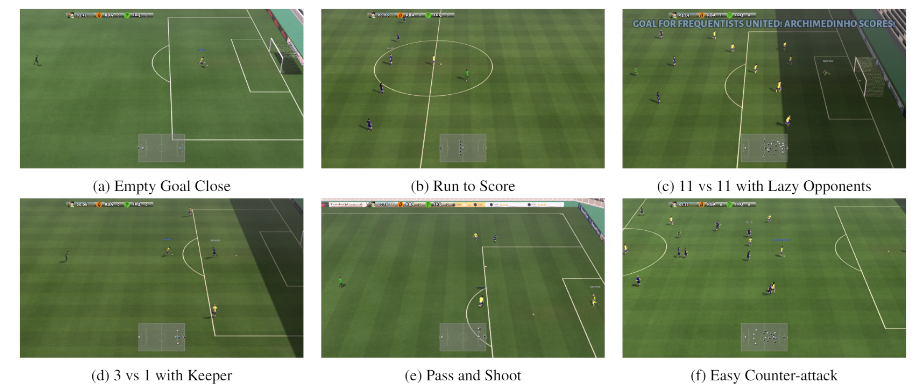
这款游戏在开发时高度模拟还原了一场真实的足球赛事,包括进球、犯规、角球、点球和越位等事件。开发团队认为足球能够在人工智能强化学习方面提供巨大的帮助,因为它需要在短期控制和已经学习到的概念之间做出自然的平衡,例如精准的传球和高水平的战略。
项目地址:https://github.com/google-research/football
Multi Model Server
Multi Model Server(MMS)是一个灵活且易于使用、用任何 ML/DL 框架都可进行深度学习模型训练的工具。使用 MMS Server CLI 或预配置 Docker 图像来设置 HTTP 端点来处理模型推理请求。
项目地址:
https://github.com/awslabs/multi-model-server
Kaolin(让 3D 深度学习研究更简单的 PyTorch 库)
Kaolin 的核心是一套可以操控 3D 内容的有效几何函数。它可以将以多边形网格、点云、有符号距离函数或体元栅格形式实现的张量 3D 数据集装入 PyTorch。
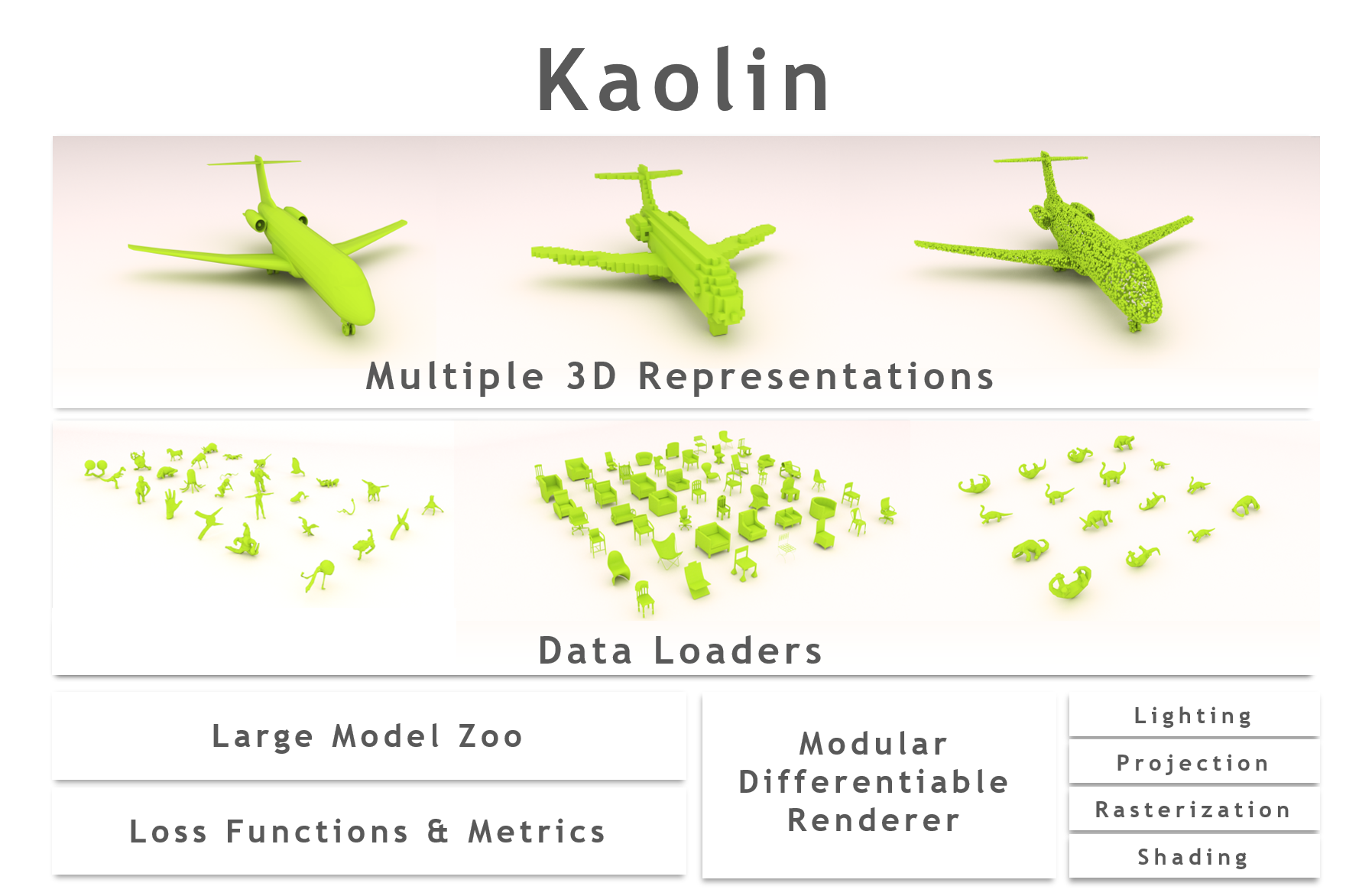
以 PyTorch 库形式实现的 Kaolin 能够简化 3D 深度学习模型的准备工作,将原来所需的 300 行代码减少到只需 5 行。像这样的工具可以让众多领域的研究人员受益,比如机器人、自动驾驶汽车、医学成像和虚拟现实等。
项目地址:https://github.com/NVIDIAGameWorks/kaolin
使用 PyTorch 实现 3D Ken Burns
手动创建 Ken Burns 效果非常耗时,而且十分复杂。现有的方法需要从多个角度获取大量的输入图像。用起来并不理想。使用 PyTorch 实现 3D Ken Burns,在给定单个输入图像的情况下,它会通过虚拟摄像机扫描和缩放动画来对静态图像进行动画处理,并使其受到运动视差的影响。
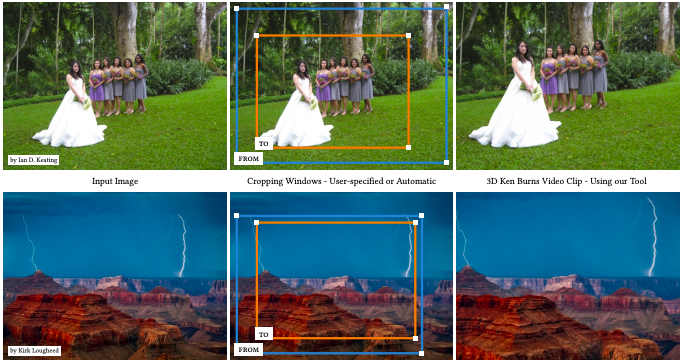
项目地址:https://github.com/sniklaus/3d-ken-burns
Plato 腾讯开源的图计算框架
这款由腾讯开源的图计算框架 Plato 可以高效地支撑腾讯超大规模社交网络图数据的各类计算,且性能达到了学术界和工业界的顶尖水平,比 Spark GraphX 高出 1-2 个数量级,使得许多按天计算的算法可在小时甚至分钟级别完成,也意味着腾讯图计算全面进入了分钟级时代。同时,Plato 的内存消耗比 Spark GraphX 减少了 1-2 个数量级,意味着只需中小规模的集群(10 台服务器左右)即可完成腾讯数据量级的超大规模图计算,打破了动辄需要上百台服务器的资源瓶颈,同时也极大地节约了计算成本。
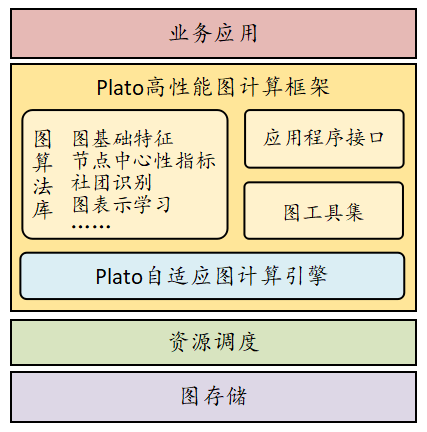
项目地址:https://github.com/tencent/plato
Tokenizer
这是一款由 hugging face 发布的可帮助 NLP 进行词语切分的文本工具。Tokenizer 可在 20 秒编码 1GB 文本,适用 Rust、Python 和 Node.js。在 NLP 模型训练中,词语标记和切分往往是一大难题。Tokenizer 能够训练新的词汇,并且进行标记。
推荐通过 Composer 来安装:
项目地址:https://github.com/nette/tokenizer
DeeperForensics-1.0
商汤研发部门与新加坡南洋理工大学合作,设计了一个新的大规模基准 DeeperForensics-1.0 来检测人脸伪造,该基准是同类产品中最大的,质量和多样性都很高,比其他数据集更加接近现实世界场景。100 位计算机专家对 DeeperForensics-1.0 中包含的视频子集质量进行排名时,报告指出与其他流行的 Deepfake 检测语料库相比,DeeperForensics-1.0 在规模上的真实性均领先。研究人员称 DeeperForensics-1.0 是同类产品中最大的,拥有 60000 多个视频,其中包含大约 1760 万帧。
项目地址:
https://github.com/EndlessSora/DeeperForensics-1.0
亚马逊基于 mxnet 的开源库 AutoGluon
亚马逊 AWS 推出新的基于 mxnet 的开源库 AutoGluon,这是一个新的开源库,开发人员可以使用该库构建包含图像、文本或表格数据集的机器学习应用程序。只需三行代码就可以自动生成高性能模型,让调参、神经架构搜索等过程实现自动化,无需研究人员人工决策,大大降低了机器学习模型的使用门槛。
项目地址:https://github.com/awslabs/autogluon
Lyft Flyte
Flyte 是一款由美国网约车公司 Lyft 开源的自家的云本地机器学习和数据处理平台。Flyte 是一个结构化编程和分布式处理平台,用于高度并发、可伸缩和可维护的工作流。
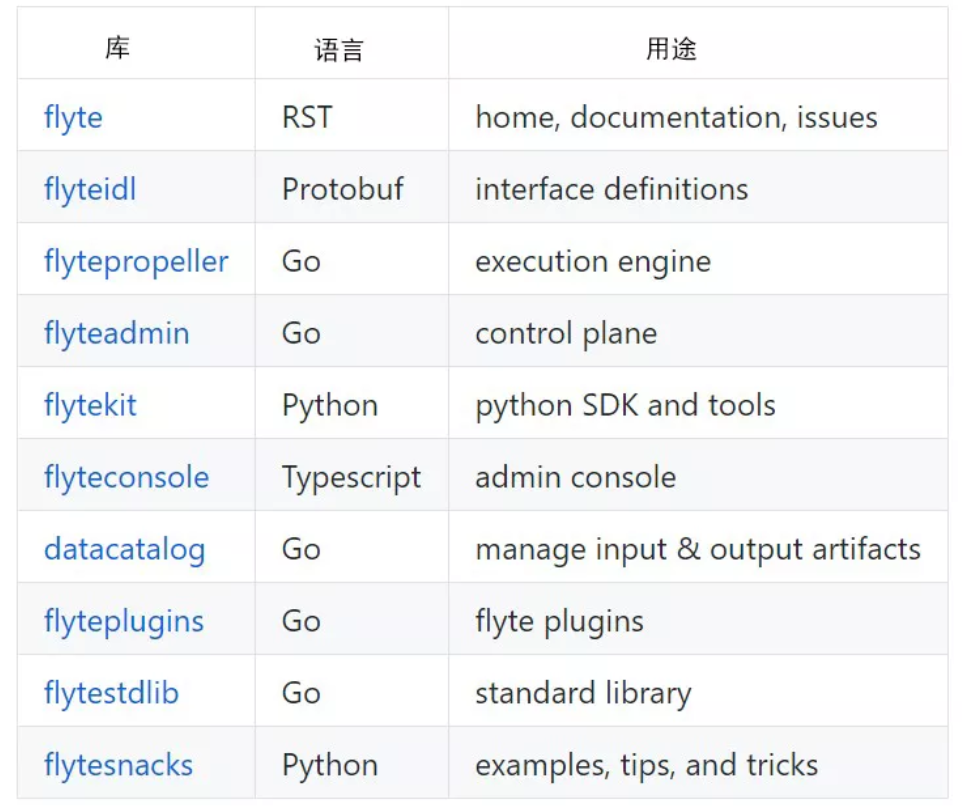
项目地址:https://github.com/lyft/flyte
Manifold
Uber 开源的 Manifold 是一种与模型无关的视觉工具,它可以显示特征分布的差异(即所观察到的现象的可测量属性)。Manifold 的性能比较视图可比较模型和数据子集的预测性能。它也是米开朗基罗机器学习平台的一部分,该平台已帮助各种产品团队分析了无数的 AI 模型。
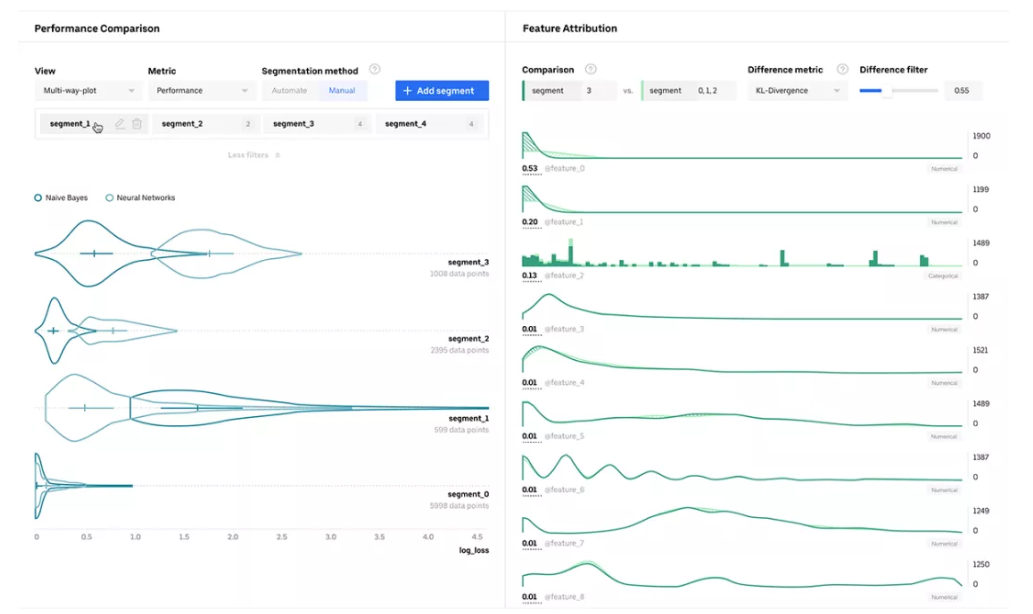
项目地址:https://github.com/uber/manifold
NNI (神经网络智能)
NNI (Neural Network Intelligence) 是一个轻量但强大的工具包,帮助用户自动进行特征工程、神经网络架构搜索、超参调优以及模型压缩。
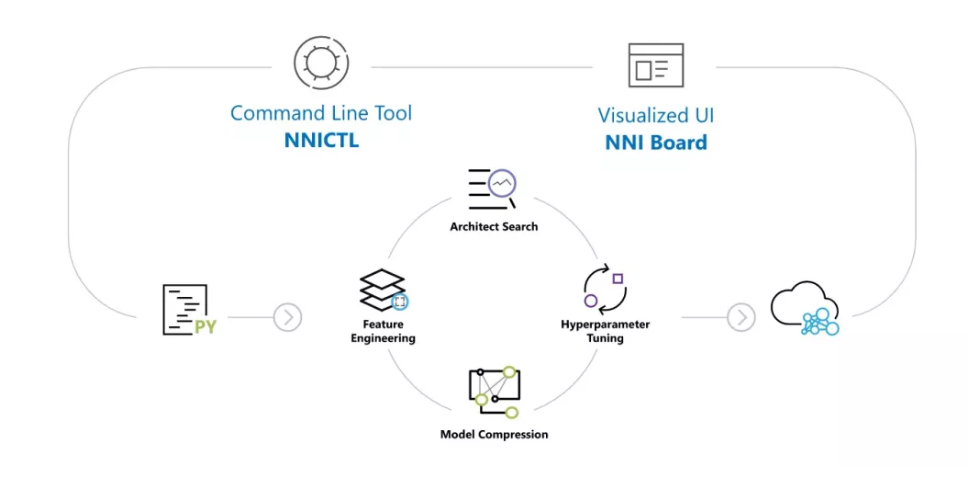
NNI 管理自动机器学习 (AutoML) 的 Experiment,调度运行由调优算法生成的 Trial 任务来找到最好的神经网络架构和/或超参,支持各种训练环境,如本机、远程服务器、OpenPAI、Kubeflow、基于 K8S 的 FrameworkController(如,AKS 等),以及其它云服务。
项目地址:https://github.com/microsoft/nni
GPipe
GPipe 是一个分布式机器学习库,使用同步随机梯度下降和流水线并行技术进行训练,适用于任何由多个序列层组成的 DNN。重要的是,GPipe 让研究人员无需调整超参数,即可轻松部署更多加速器,从而训练更大的模型并扩展性能。核心 GPipe 库是在 Lingvo 框架 下开源的。
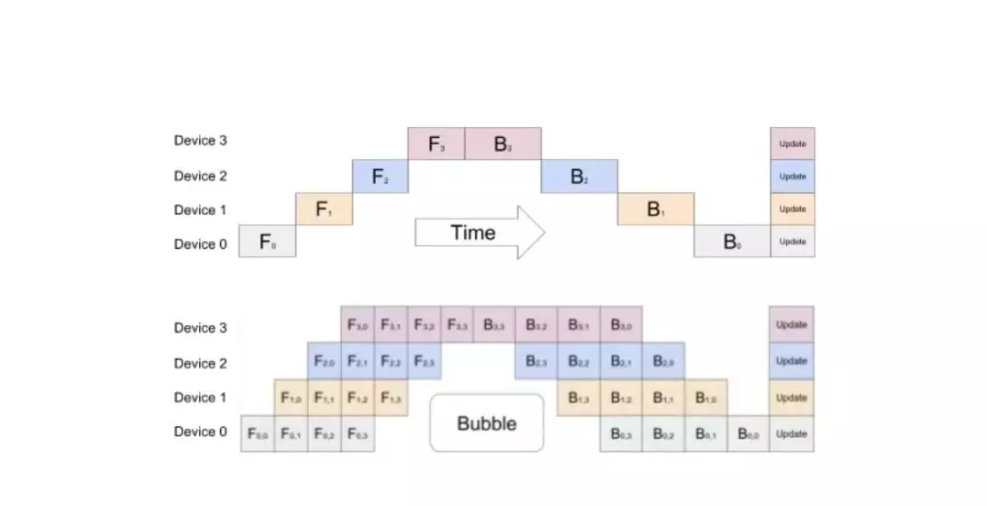
项目地址:https://github.com/tensorflow/lingvo
PyText
PyText 是一个基于 PyTorch 构建的 NLP 建模(基于深度学习)框架,核心功能可以支持文本分类、序列标注等神经网络模型。PyText 可以简化工作流程,加速试验,同时还能促进大规模部署。
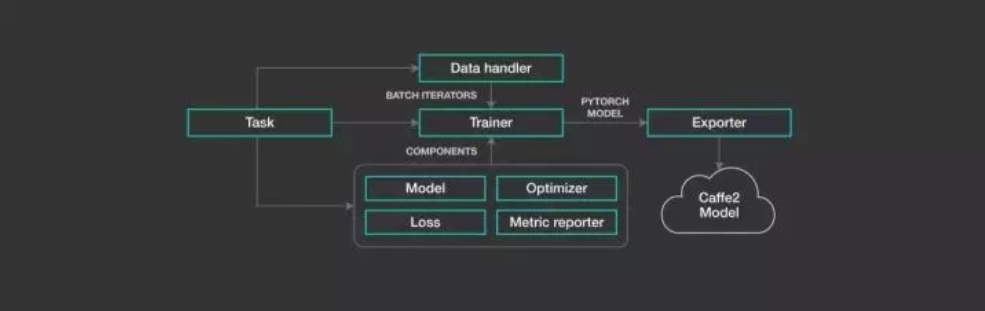
项目地址:https://github.com/facebookresearch/pytext
Reformer PyTorch 中有效的 Transformer
该款 Reformer Transformer 架构改变了 NLP 的“版图”。它催生了大量的 NLP 框架,例如 BERT、XLNet 和 GPT-2 等。但是我们过去所了解的 Transformer 框架的规模都是巨大的,成本也非常高,让很多想要学习和实现它们的人望尘莫及。
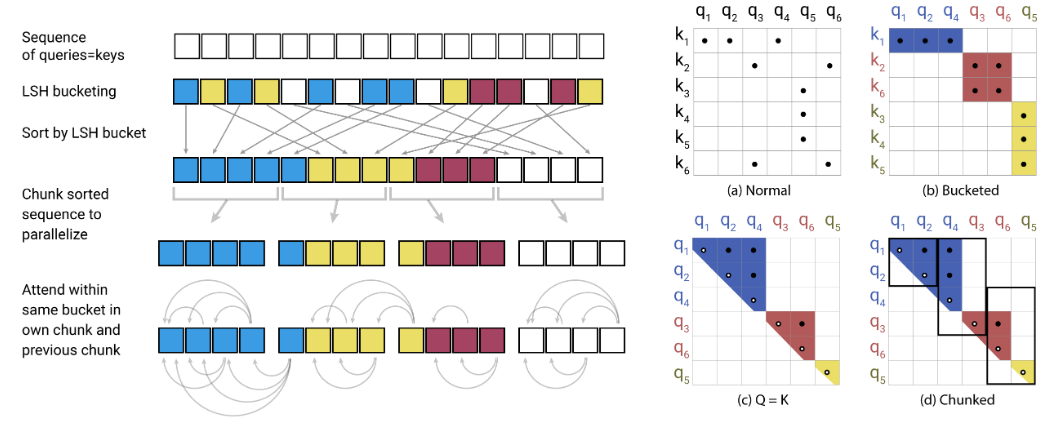
GitHub 上包含了 Reformer 的 PyTorch 实现。该项目的作者提供了一个简单但有效的示例并开放了整个代码,用户可以根据需求搭建自己的模型。
可按照下列指令将 Reformer 安装在机器上:
项目地址:
https://github.com/lucidrains/reformer-pytorch
PandaPy (将成为新的最受欢迎的 Python 库)
如果您正在处理一个带有混合数据类型(int、float、datetime、str 等)的机器学习项目,那么您应该尝试使用 PandaPy 而不是 Pandas。对于这些数据类型,它比 Pandas 少消耗近三分之一的内存。
用 pip 安装 PandaPy:
项目地址:https://github.com/firmai/pandapy
AVA 阿里巴巴智能可视分析框架
AVA 由蚂蚁金服 AntV & DeepInsight、新零售技术事业群 FBI、盒马 Kanaries 等阿里巴巴集团内多个核心数可视化技术和产品团队联合共建。
AVA 是为了更简便的可视分析而生的技术框架。 其名称中的第一个 A 具有多重涵义:它说明了这是一个出自阿里巴巴集团(Alibaba)技术框架,其目标是成为一个自动化(Automated)、智能驱动(AI driven)、支持增强分析(Augmented)的可视分析解决方案。
演示案例:
项目地址:
https://github.com/antvis/AVA/blob/master/zh-CN/README.zh-CN.md
fast-neptune(加速机器学习项目进程)
fast-neptune 是一个能帮你快速记录启动实验时所需的所有信息的库,可在 Jupyter 笔记本上运行。可再现性已经成为了机器学习中的关键一环,对于实验研究和现实应用都至关重要。我们希望在现实应用中得到可靠的结果,跟踪每个测试参数的设置及其结果。
fast-neptune 在 pypi 上可用,所以只需简单运行下列指令:
项目地址:https://github.com/DanyWind/fast_neptune
ergo
ergo 是从拉丁语“我思故我在 Cogito ergo sum”中而来,这是一款能让 Keras 机器学习更加简单的命令行工具。它可以:
用最少数量的代码在数秒内构建新项目;
编码样本、导入和优化 CSV 数据集并且用这些来训练模型;
在训练中可视化模型结构、损失和精准函数;
借助差分推理决定每个输入特征如何影响精准度;
从服务器导出一个简单的 REST API 来使用模型。
项目地址:https://github.com/evilsocket/ergo
哪吒
这是华为诺亚方舟实验室自研的预训练语言模型,在一些 NLP 任务上取得了 SOTA 的表现。这一模型基于 BERT,可以在普通的 GPU 集群上进行训练,同时融合了 英伟达 和谷歌代码的早期版本。哪吒模型已有四种中文的预训练模型,分别是 base、large 和对应的 mask 和全词 mask 类型。
项目地址:
https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/NEZHA
TinyBERT
TinyBERT 同样是由华为诺亚方舟实验室开源的预训练语言模型,这是一个通过蒸馏方法获得的 BERT 模型。相比原版的 BERT-base,TinyBERT 比它小了 7.5 倍,推理速度则快了 9.4 倍。无论是在预训练阶段还是特定任务学习阶段,TinyBERT 的性能都更好。
项目地址:
https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TinyBERT
Metaflow
Metaflow 是 Netflix 机器学习基础架构的关键部件,主要用于加速数据科学工作流的构建和部署,Netflix 希望通过开源 Metaflow 简化机器学习项目从原型阶段到生产阶段的过程,进而提高数据科学家的工作效率。在过去两年中,Metaflow 已在 Netflix 内部用于构建和管理从自然语言处理到运营研究的数百个数据科学项目。
Metaflow 也可以与当前主流的 Python 数据科学库一起使用,包括 PyTorch、Tensorflow 和 SciKit Learn。
项目地址:https://github.com/Netflix/metaflow
ZEN
ZEN 是由创新工场 AI 工程院和香港科技大学联合研究的一款基于 BERT 的中文预训练模型。在中文任务中,ZEN 不仅性能优于 BERT,也比之前中文预训练模型更好。ZEN 对高概率成词的 n-gram 添加了独有的编码和向量表示,此模型可以提供更强的文本的编码能力和理解能力。
项目地址:https://github.com/sinovation/zen
Megatron-LM
Megatron 是一款强大的 transformer。目前,它支持 GPT2 和 BERT 混合精度的模型并行、多模训练。我们的代码库能有效地训练一个在 512 个 GPU 上让 8-way 和 64-way 数据并行的 72 层、83 亿参数 CPT2 语言模型。
研发团队发现更大的语言模型能够在短短 5 次训练中超越当前 GPT2 15 亿参数 wikitext。为了训练 BERT,存储库在 3 天内训练了 64 个 V100 GPU 上的 BERT Large。最终的语言建模 perplexity 为 3.15,SQuAD 为 90.7。
项目地址:https://github.com/NVIDIA/Megatron-LM
RoughViz
RoughViz 是一款很棒的 JavaScript 数据可视化库,能够生成手绘草图或可视化数据,基于 D3v5、roughjs 和 handy。可以按下列指令安装 RoughViz:
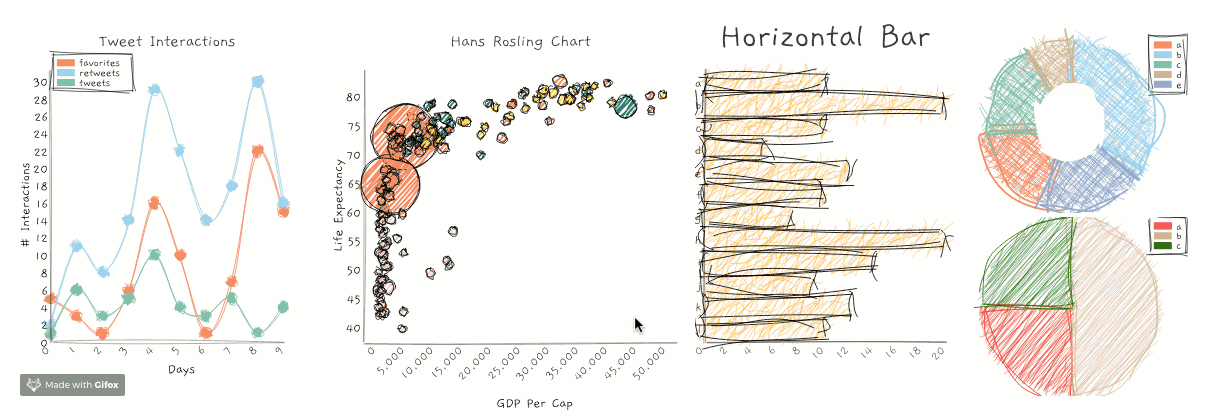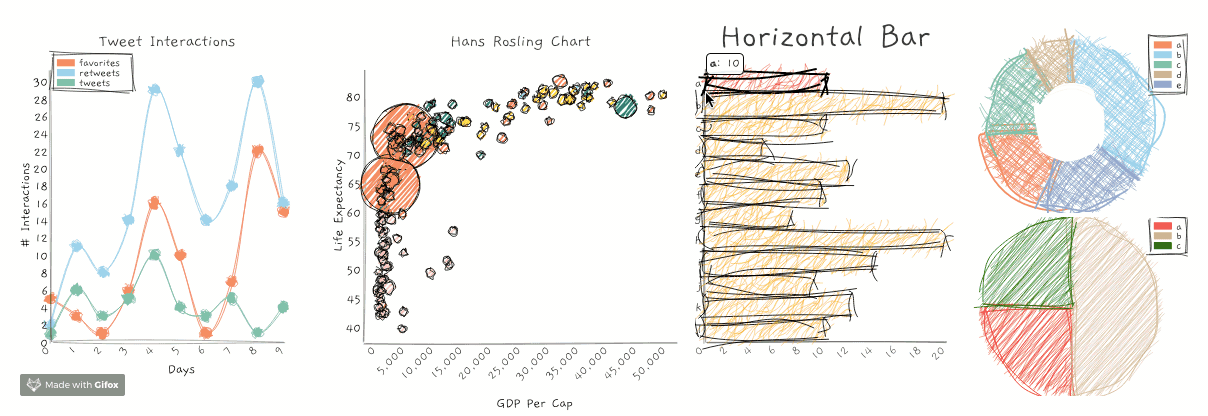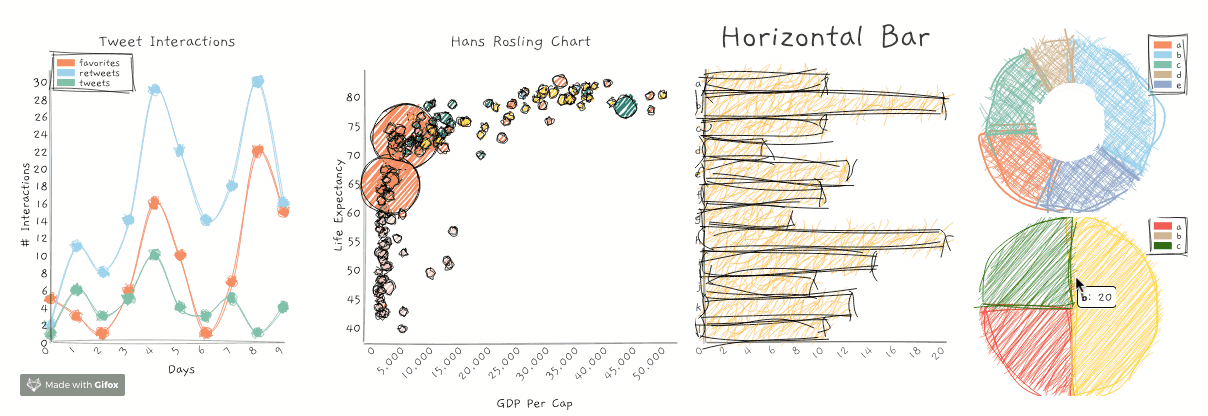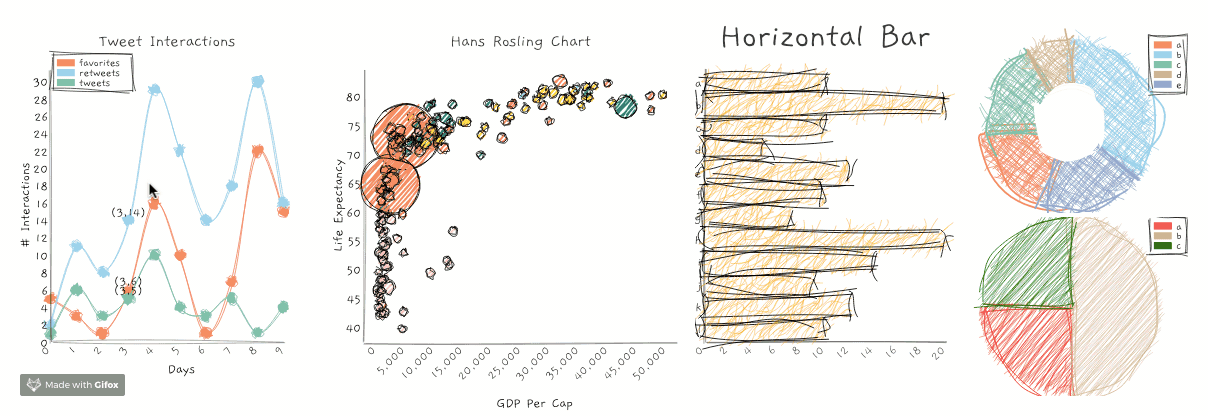
项目地址:https://github.com/jwilber/roughViz
T5 Text-to-Text Transfer Transformer
T5 是谷歌研发的一款文本到文本转换框架,基于 Transformer。该框架在多个 benchmarks 上的总结、问题回答、文本归类任务表现突出。开发团队已经在 GitHub 上开源了 T5 相关数据集、预训练模型以及所有代码。T5 为文本到文本任务的模型训练和微调提供了非常实用的模块,开发者可以将它用于未来的模型开发工作中。
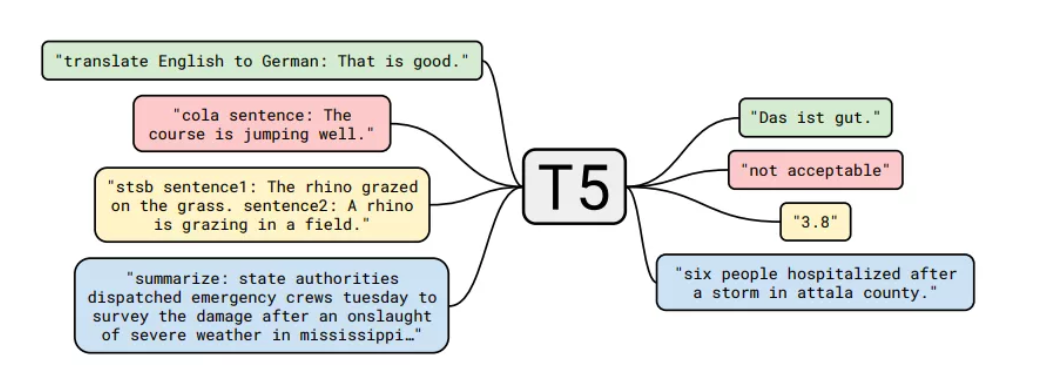
项目地址:
https://github.com/google-research/text-to-text-transfer-transformer
Ultra-Light and Fast Face Detector
这是一个超级轻量级的人脸检测模型,也是非常实用的计算机视觉应用,它的模型大小仅有 1MB,堪称现象级的开源发布。
项目地址:
https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB
NVIDIA Few-Shot viv2vid
vid2vid 能够将输入的视频语义标签转换为非常逼真的视频输出,比如可以输入姿势、谈话内容,生成一套完整动作的视频。
项目地址:https://github.com/NVlabs/few-shot-vid2vid
腾讯分布式消息中间件 TubeMQ
TubeMQ 是腾讯开源的分布式消息中间件系统,专注服务大数据场景下海量数据的高性能存储和传输。相比 Kafka 依赖于 Zookeeper 完成元数据的管理和实现 HA 保障不同,Tube MQ 系统采用的是自管理的元数据仲裁机制方式进行,Master 节点通过采用内嵌数据库 BDB 完成集群内元数据的存储、更新以及 HA 热切功能,负责 Tube MQ 集群的运行管控和配置管理操作,对外提供接口等;通过 Master 节点,Tube MQ 集群里的 Broker 配置设置、变更及查询实现了完整的自动化闭环管理,减轻了系统维护的复杂度。
项目地址:https://github.com/Tencent/TubeMQ
SandDance 数据可视化工具
SandDance 是微软研究院推出的以 Web 为基础的数据视觉化应用,并且提供了触控式的界面,实现使用者和 3D 信息图表进行互动,更加特别的是可以以不同的角度不同的方式呈现分析结果,使用户可以通过可视化的方式更加直观的接受数据信息。
项目地址:https://github.com/microsoft/SandDance
NeuralClassifier(NLP)神经分类器
神经分类器的设计是为了快速实现分层多标签分类任务的神经模型,这在现实场景中更具有挑战性和普遍性。一个突出的特点是神经分类器目前提供了多种文本编码器,如 FastText、TextCNN、TextRNN、RCNN、VDCNN、DPCNN、DRNN、AttentiveConvNet、Transformer encoder 等。它还支持其他文本分类场景,包括二进制类和多类分类。
项目地址:
https://github.com/Tencent/NeuralNLP-NeuralClassifier
基于深度学习的 CTR 预测算法库 DeepCTR-Torch
这是一个免费的 Python 库,使用 Pyforest 可在一行代码中导入所有 python 数据科学库。Pyforest 目前可导入包括 pandas、numpy、matplotlib 等等众多的数据科学库。
Pyforest 的使用方式也非常简单,只要使用 pip install pyforest 在您的计算机上安装库,就可以使用了。您可以在一行代码中导入所有流行的用于数据科学的 python 库:
项目地址:https://github.com/8080labs/pyforest


Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...
京 ICP 备 16027448 号 - 5

京公网安备 11010502039052号

<script type="text/javascript" src="//www.infoq.cn/static/infoq/www/article/main.js?v=1.2"></script>




















 到【灌水乐园】发言
到【灌水乐园】发言









评论