







我也有过题主的疑问,但是感觉其他人都没有回答到点子上。
题主应该是想问,既然K和Q差不多(唯一区别是W_k和W_Q权值不同),直接拿K自己点乘就行了,何必再创建一个Q?创建了还要花内存去保存,不断去更新,多麻烦。
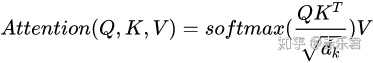
(这个是self-attention的公式,主要有Q,K,V三个向量)
想要回答这个问题,我们首先要明白,为什么要计算Q和K的点乘。
现补充两点
-
先从点乘的物理意义说,两个向量的点乘表示两个向量的相似度。
-
Q,K,V物理意义上是一样的,都表示同一个句子中不同token组成的矩阵。矩阵中的每一行,是表示一个token的word embedding向量。假设一个句子"Hello, how are you?"长度是6,embedding维度是300,那么Q,K,V都是(6, 300)的矩阵
简单的说,K和Q的点乘是为了计算一个句子中每个token相对于句子中其他token的相似度,这个相似度可以理解为attetnion score,关注度得分。比如说 "Hello, how are you?"这句话,当前token为”Hello"的时候,我们可以知道”Hello“对于” , “, “how”, “are”, “you”, "?"这几个token对应的关注度是多少。有了这个attetnion score,可以知道处理到”Hello“的时候,模型在关注句子中的哪些token。

这个attention score是一个(6, 6)的矩阵。每一行代表每个token相对于其他token的关注度。比如说上图中的第一行,代表的是Hello这个单词相对于本句话中的其他单词的关注度。添加softmax只是为了对关注度进行归一化。
虽然有了attention score矩阵,但是这个矩阵是经过各种计算后得到的,已经很难表示原来的句子了。然而V还代表着原来的句子,所以我们拿这个attention score矩阵与V相乘,得到的是一个加权后结果。也就是说,原本V里的各个单词只用word embedding表示,相互之间没什么关系。但是经过与attention score相乘后,V中每个token的向量(即一个单词的word embedding向量),在300维的每个维度上(每一列)上,都会对其他token做出调整(关注度不同)。与V相乘这一步,相当于提纯,让每个单词关注该关注的部分。
好了,该解释为什么不把K和Q用同一个值了。
经过上面的解释,我们知道K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_Q来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。这里解释下我理解的泛化能力,因为K和Q使用了不同的W_k, W_Q来计算,得到的也是两个完全不同的矩阵,所以表达能力更强。
但是如果不用Q,直接拿K和K点乘的话,你会发现attention score 矩阵是一个对称矩阵。因为是同样一个矩阵,都投影到了同样一个空间,所以泛化能力很差。这样的矩阵导致对V进行提纯的时候,效果也不会好。
推荐看一下这篇文章,对Q,K,V进行了很详细的讲解。
https://medium.com/dissecting-bert/dissecting-bert-part-1-d3c3d495cdb3















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









