







动态SQL字符长度超过8000,我记得SQL SERVER 2005中用SP_EXECUTESQL打破了这个限制。
平常用动态SQL,可能都会用EXEC(),但是有限制,就是8000字符串长度。自从SQL SERVER 2005起,在 INSIDE SQLSERVER 2005 T-SQL PROGRAMMING中提到,使用SP_EXECUTESQL()和NVARCHAR(MAX)可以超越8000个字符的限制。因为SP_EXECUTESQL()必须使用NVARCHAR,NCHAR,NTEXT作为参数,所以SP_EXECUTESQL()的最长字符限制就是4000。
我们看一个NVARCHAR(4000)的例子:
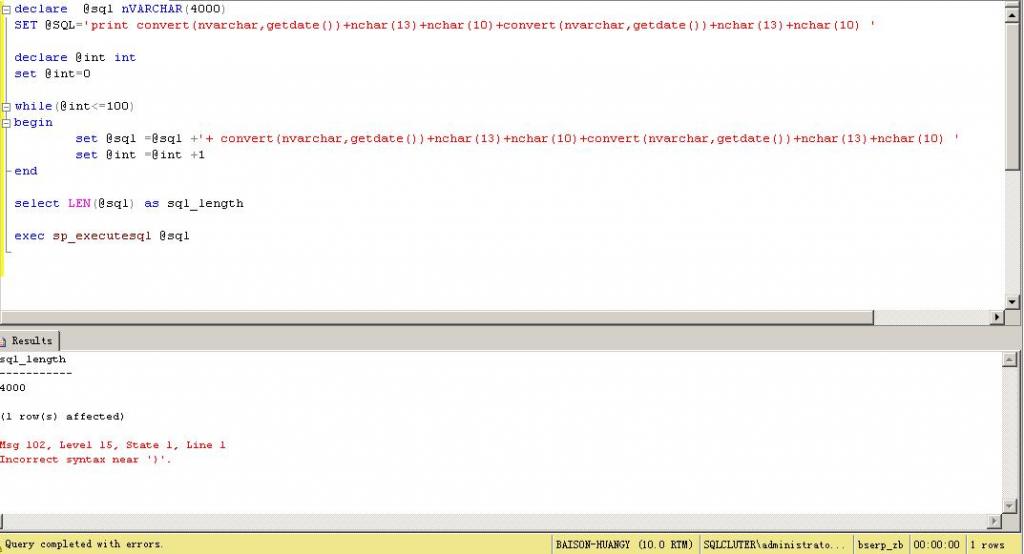
如何打破这个限制,我们再看(将SQL字符变量类型设置为NVARCHAR(MAX)):
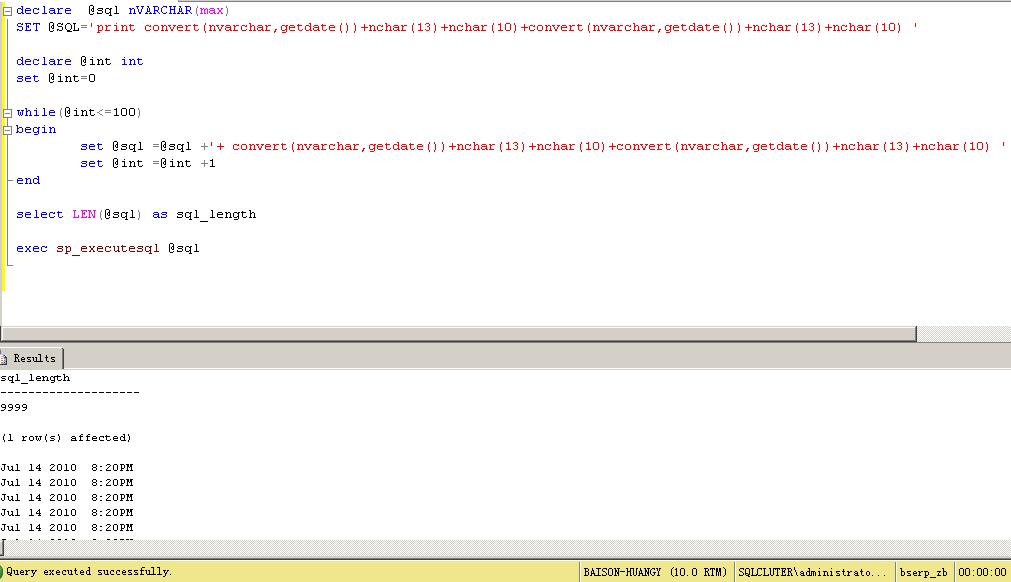
可以看到,成功执行了SQL字符长度为9999的动态SQL。。
看一个SQL字符超过100000的例子:
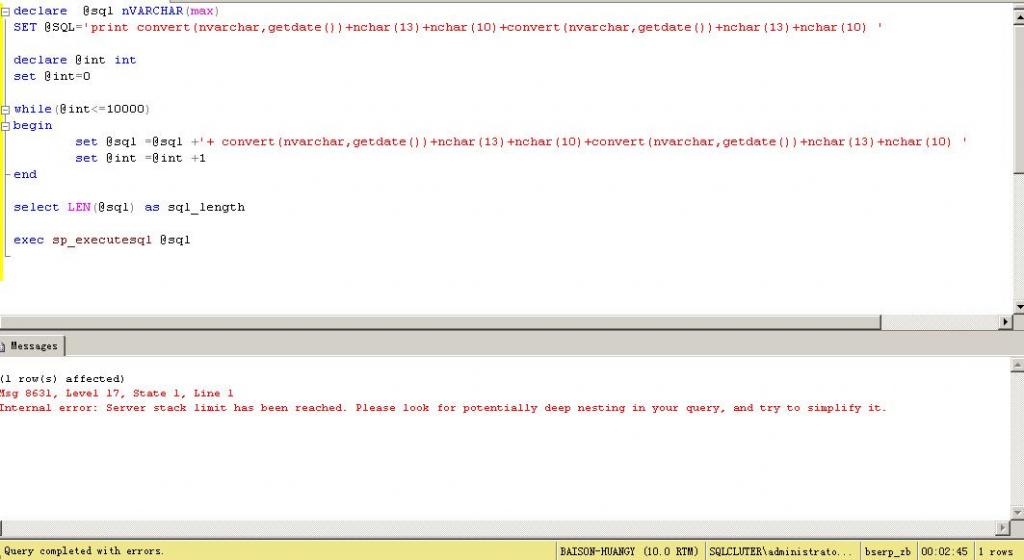
字符串长度巨大,我只能将结果保存到RPT文件,可惜的是,我的机器(2.5内存+32位WIN2003)还是不能显示,肯定是资源不够用
















 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









