







暴力匹配字符串
- 代码实现暴力匹配
class KMP(object):
def violence_match(self, str1, str2):
str1_array = list(str1)
str2_array = list(str2)
str1_len = len(str1_array)
str2_len = len(str2_array)
i = 0
j = 0
while i < str1_len and j < str2_len: # 保证匹配时不越界
if str1_array[i] == str2_array[j]:
i += 1
j += 1
else:
i = i - j + 1
j = 0
# 判断是否匹配成功
if j == str2_len:
return i - j
else:
return -1
if __name__ == '__main__':
str1 = "渡我被身子 渡我被身子 绿谷丽日御茶子渡我被身子赛高"
str2 = "渡我被身子赛高"
m = KMP()
print(m.violence_match(str1, str2)) # 19
- 暴力匹配思路图解
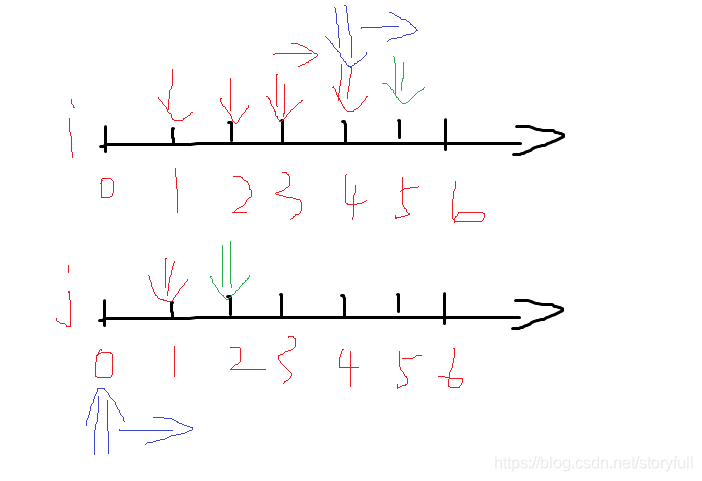
(1)逐一匹配,如果没有相当的,就让待匹配的字符串不断后移,要匹配的字符串不动
(2)如果两者匹配到一个相同的,就同时向后移动一位,看下一位是否配
(3)如果在上一步的匹配过程中出现不匹配的,待匹配的字符串位置要回到“两者开始匹配的后一个位置”即是 i-j+1 (也可以理解为,开始匹配时,两者一共走过的距离,后移一位);而要匹配的字符串则要回到开始0的位置
(4)整体来说,暴力匹配的方式会产生不必要的回溯
KMP算法
KMP算法基本概况
- 介绍:

- 提出问题:

- 思路分析:








部分匹配表
- 先了解前缀和后缀是什么?

- 举例说明:
(1)假如字符串是:ABCDA 前缀和后缀相同的位A,那么到A的位置字符串的部分匹配表值应该为1,注意是元素的长度,不是有几组相同的元素,所以ABCDA 的部分匹配表为:↓↓↓
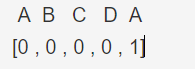
(2)还有部分匹配表中,每一位所代表的含义是:第一个0 表示的是"A" 字符串 它所以对应的部分匹配表的值为0;第二个0表示"AB" 字符串 它所以对应的部分匹配表的值为0;第三个0表示"ABC"字符串 它所以对应的部分匹配表的值为0;第四个0表示"ABCD"字符串 它所以对应的部分匹配表的值为0,为什么都等于,请分别求出他们的前缀和后缀,就会发现他们公共部分不存在,所有共部分的长度也就为0;直到字符串"ABCDA" 此时 前缀和后缀公共部分为 “A” ,它的长度为1 ,所有该字符串对应的部分匹配表的值为1;

(3)知道上面的规则后,我们回去看:字符串"ABCDABD" 所对应的部分匹配值

KMP算法Python实现
算法的本质是:原本暴力求解,当匹配字符串出现不同时,我们回到两者最开始相等的后一位,
重新开始匹配,造成不必要的回溯;
而KMP是回到我们求出的部分匹配表的前一位,再重新开始匹配;
class KMP(object):
def kmp_match(self, string1, string2):
# 第一步获取到一个字符串(子串)的部分匹配值表
# aim_string = "ABCDABD" # 目标匹配值
part_match_form = self.get_part_match_form(string2) # 求出部分匹配表
res_index = self.kmp_search_core(string1, string2, part_match_form)
print(res_index)
# kmp搜索算法
def kmp_search_core(self, string1, string2, next_array):
'''
:param string1: 原字符串(待匹配字符串)
:param string2: 子串(匹配字符串)
:param next_array:部分匹配表,是子串对应的部分匹配表
:return: 返回时-1就是没有匹配到,否则返回第一个匹配的位置
'''
j = 0
for i in range(len(string1)):
# 需要处理两者不相等时(核心)
while j > 0 and string1[i] != string2[j]:
j = next_array[j - 1]
if string1[i] == string2[j]:
j += 1
if j == len(string2): # 找到了
return i - j + 1
return -1
# 获取部分匹配值表
def get_part_match_form(self, aim_str):
# 创建一个next 数组保存部分匹配值
next_array = [0] * len(aim_str)
next_array[0] = 0 # 如果字符串长度为1部分匹配的值就是0
j = 0
for i in range(1, len(aim_str)):
while j > 0 and aim_str[i] != aim_str[j]: # KMP算法的核心
j = next_array[j - 1]
if aim_str[i] == aim_str[j]:
j += 1
next_array[i] = j
return next_array
if __name__ == '__main__':
str1 = "BBC ABCDAB ABCDABCDABDE"
str2 = "ABCDABD"
m = KMP()
m.kmp_match(str1, str2)
'''输出结果
15
'''














 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









