



 博客介绍了使用UMI - OCR、PDFBOX插件实现PDF文字识别的思路。先通过PDFBOX识别文字,若为图片则调用OCR识别;OCR识别慢且长图有问题,需用PDFBOX转图片再拼接。还给出UMI - OCR下载地址、安装设置及PDFBOX配置等内容。
博客介绍了使用UMI - OCR、PDFBOX插件实现PDF文字识别的思路。先通过PDFBOX识别文字,若为图片则调用OCR识别;OCR识别慢且长图有问题,需用PDFBOX转图片再拼接。还给出UMI - OCR下载地址、安装设置及PDFBOX配置等内容。
使用插件:UMI-OCR、PDFBOX
实现思路:通过PDFBOX识别PDF文字,如果是图片,则识别不出来,再调用OCR进行识别返回文字;OCR识别较慢,长图识别不出来,目前HTTP方式只支持图片格式,还需使用PDFBOX要将每一页PDF转换为图片再进行识别拼接。
UMI-OCR下载地址:https://github.com/hiroi-sora/Umi-OCR/releases/latest
下载后直接在WIN系统安装(目前只支持WIN系统),安装包内含PaddleOCR-json,无需再进行下载;安装启动,设置HTTP请求参数
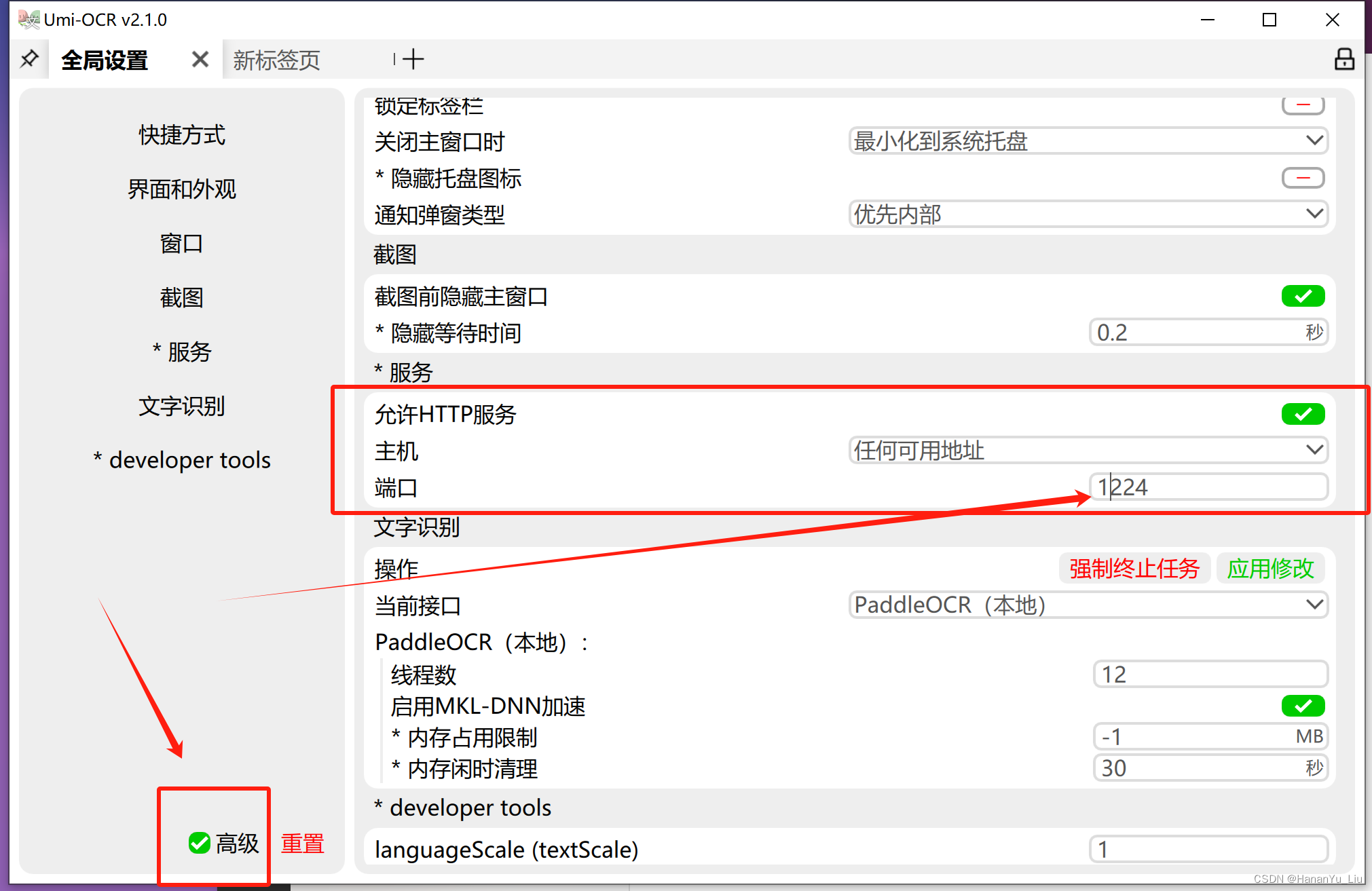
全局设置 --> 高级 --> 允许HTTP服务:
主机设置为:任何可用地址
端口:自己设置
PDFBOX MAVEN版本配置:
<!-- PDF文档处理 -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.8</version>
</dependency>代码实现文字识别:
String text = "";
try {
PDDocument pdDocument = PDDocument.load(image.getInputStream());
PDFTextStripper pdfTextStripper = new PDFTextStripper();
//读取pdf中所有的文件
//前端HTML不识别><,需要进行更换
text = pdfTextStripper.getText(pdDocument);
text = text.replace(" ", "")
.replace("\r", "")
.replace("\t", "")
.replace("\n", "");
if (StrUtil.isNotEmpty(text)){
text = text.replace("<","<").replace(">",">");
}else{
/**
* 如果没有识别到文字,
* 则转成图片
* 进行OCR识别获取文本
*/
text = uploadPDF2OcrGetText(accessUrl, image);
}
}catch (IOException e){
log.error(e.getMessage());
}如果文档里面含有"<"">",前端HTML不识别,则需要进行转换
uploadPDF2OcrGetText:
/**
* 上传图片文件至OCR
* @param accessUrl 访问地址
* @param image 图片文件
* @return
*/
public static String uploadPDF2OcrGetText(String accessUrl, MultipartFile image) {
List<ByteArrayOutputStream> list = getStreamList(image);
StringBuilder sb = new StringBuilder();
if (list != null && !list.isEmpty()){
for (ByteArrayOutputStream outputStream : list) {
String str = getData(accessUrl, outputStream);
if (StrUtil.isNotEmpty(str)){
sb.append(str);
}
}
}
return sb.toString();
}将PDF转为图片流方法getStreamList:
/**
* PDFBOX将PDF转成png流
* @param file 图片文件
* @return List
*/
public static List<ByteArrayOutputStream> getStreamList(MultipartFile file) {
List<ByteArrayOutputStream> list = new ArrayList<>();
try{
PDDocument pdf = PDDocument.load(file.getInputStream());
PDFRenderer renderer = new PDFRenderer(pdf);
int pageCount = pdf.getNumberOfPages();
for (int i = 0; i < pageCount; i++){
BufferedImage image = renderer.renderImageWithDPI(i, 120);//120为DPI根据自己设置
ByteArrayOutputStream bas = new ByteArrayOutputStream();
ImageIO.write(image, "png", bas);
list.add(bas);
}
}catch (IOException e){
log.error(e.getMessage());
}
return list;
}调用OCR识别文字方法getData:
/**
* 上传图片文件至OCR
* @param accessUrl 访问地址
* @param outputStream 图片流
* @return
*/
public static String getData(String accessUrl, ByteArrayOutputStream outputStream){
//转换为Base64
String base64Image = new String(Base64.encodeBase64(outputStream.toByteArray()));
//如果文件属于图片则进行文件转换
JSONObject jb = new JSONObject();
jb.set("base64", base64Image);
JSONObject jb1 = new JSONObject();
jb1.set("tbpu.parser", "multi_para");
jb1.set("data.format", "text");
jb.set("options", jb1);
String result2 = HttpRequest.post(accessUrl)
.body(jb.toString())//表单内容
.timeout(300000)//数据可能较大,超时时间调的较长
.execute().body();
JSONObject jsonObject = JSONUtil.parseObj(result2);
String text = null;
if ("100".equals(jsonObject.getStr("code"))){
text = jsonObject.getStr("data");
}
return text;
}
















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









