






2012年的一篇关于表示学习的综述文章,至今引用近2000篇,翻译出来学习一下
之前看了其他的翻译,将其中的逻辑没有翻译出来,一头雾水,所以自己总结翻译一下,希望对大家有帮助
文中有几部分没有翻译,主要是对比联系,大家有兴趣 可以自己看一下
关键词:neural networks, deep learning and representation learning
先放个框架图,主要内容
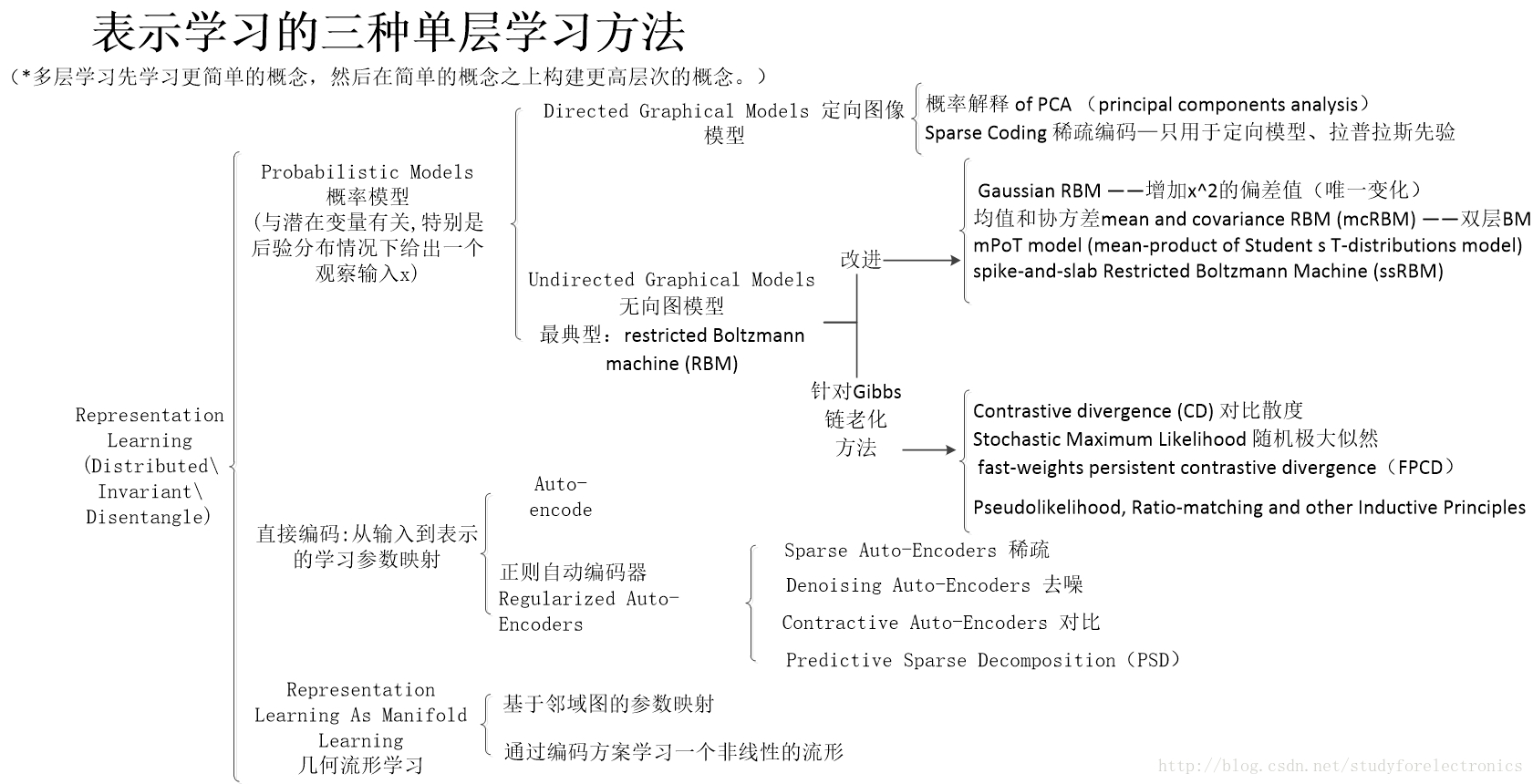
1. 应用领域
(1)
语音识别和信号处理
(2)目标识别
(3)自然语言处理
(4)多任务和转移学习,领域适应(寻找不同特征间的共性)
——————
2.表征学习的优势
(1)通用先验条件
平滑性、不同解释因素、分层结构下的更抽象特征、半监督学习(条件间有相互影响)、学习任务间的关联因素、Manifolds:流形学习、分类变量值、时间和空间相干性、相关观测量稀疏的视为0
(2)Smoothness and the Curse of Dimensionality
虽然平滑可以是一个有用的假设,但它还不足以解决维度的问题,因为当数据在原始输入空间中表示时,这样的皱纹数量wrinkles(目标函数的起伏)可能随着相关的交互因子的数量呈指数增长。
因此需要将 平滑性条件与其他通用先验条件 结合,
来发现这些特征,或者等价地,一个相似函数。
(3)Distributed representations
一个one-hot表示,例如传统的聚类算法、高斯混合模型。
最近邻算法、高斯SVM等的结果都需要O(N)个参数来区分O(N)个输入区域。
但是像RBM、sparse coding、auto-encoder或者多层神经网络可以用O(N)个参数表示O(2^k)个输入区域。它们就是分布式表示。
聚类到分布式表示的泛化是多聚类,不同聚类并行发生或单个聚类同时应用于多输入
在分布式表示中,可以在给定输入的响应中激活大量可能的功能子集或隐藏单元。
(4)Depth and abstraction
deep architecture 能够促进 特征重用 和 使用更高层的抽象特征
•
特征重用: 深度学习的核心(
构建多个层次的表示或学习特征层次结构)
深回路的长度•是输入至输出的最长长度。回路的路径数基于他的深度而指数增长。
可通过改变节点计算公式或通过一个常量,而改变回路的深度
我们在每个节点中所允许的典型计算包括:加权和、乘积、人工神经元模型(例如在仿射变换上的单调非线性)、核的计算或逻辑门。
•
抽象和不变性:
更抽象的概念通常不受输入的局部变化影响 (不变)。
更抽象的表示可以检测到包含更多不同现象的类别。
抽象还可以出现在高级的连续值属性中,这些属性只对输入中的某些非常特定类型的更改敏感。学习这些不变的特性是模式识别中的一个长期目标。
(5)Disentangle factors of variation
最鲁棒的特征学习是尽可能多的解耦Disentangle factors,抛弃尽可能少的信息
原因: 输入分布中,各因素独自变化,但是考虑连续输入的时候,会有部分因素一起变化
如果某种形式的维数减少是可取的,那么我们假设在训练数据中最少代表的变化的局部方向应该首先被删除。
分离方法:
利用大量未标记的示例,来学习分离各种 explanatory sources的表示。
总结! 对representation 的因素的要求:
- Distributed : 分布式 包含更多的输入
- Invariant: 更抽象,对输入的局部变化有不变性
- Disentangle : 分离更多因素,减小因素间的互相影响
学习的好标准:
建立明确的目标,或培训目标。
我们已经提出了一个很好的表示方法,它能使变化的潜在因素分离开来,但是我们如何将其转化为合适的训练标准呢?
是否有必要绝不在一个好的模型下尽可能地增加可能性?
我们可以引入一些先验(可能是依赖于数据的)来帮助更好地分离?
——————
3. Building deep representations
06年在特征学习方面有一个突破,中心思想就是贪婪单层非监督预训练greedy layerwise unsupervised pre-training
,学习层次化的特征,每次一层,用非监督学习来学习组合之前学习的transformation。
单层训练模式也可以用于监督训练,虽然效果不如非监督训练,但比没有预训练要好。
下面几种方法组合单层网络来构成监督模型:
层叠RBM形成DBN
,但是怎么去估计最大似然来优化生产模型目前还不是很清楚,一种选择是wake-sleep算法。
另一种方法是
结合RBM参数到DBM
中,基本上就是减半。
还有一种方法是
层叠RBM或者AE形成深层自编码器
,
另一种方法训练深层结构是iterative construction of a free energy function
——————
4. Single-layer learning modules
在特征学习方面,有两条主线:一个根源于PGM(probabilistic graphical models概率图模型
),一个根源于NN(neural networks 神经网络
)。
根本上这两个的区别在于每一层是描述为PGM还是computational graph,简单的说,就是隐层节点便是latent random variables
潜在的随机变量
还是computational nodes
计算节点
。
以上两者很相似,具体上,RBM(restricted Boltzmann machine
)是在PGM这一边,AE(auto-encoder variants
)在NN这一边。在RBM中,用score matching训练模型本质上与AE的规则化重建目标是相通的。 若NN中的计算图像与概率模型中的计算图像相对应,则其也和图像模型本身结构相对应。
研究简单的非监督单层表示学习算法是研究基于此的深度学习单层算法发展的基础、
PCA(principal components analysis
)最老的特征提取算法,1901年,三种解释:
a. 与PM(probabilistic models概率模型
)相关,例如probabilistic PCA、factor analysis和传统的多元变量高斯分布。
b. 它本质上和线性AE相同
c. 它可以看成是线性流形学习的一种形式
但是线性特征的表达能力有限,他不能层叠来获取更抽象的表示,因为组合线性操作最后还是产生线性操作。
以下讲述了三种表示学习方法:概率模型、基于重构的算法和几何流形学习方法。
5.Probabilistic Models 概率模型
特征:与潜在变量有关,特别是后验分布情况下给出一个观察输入x
Within the framework of probabilistic models, the learned representation is always associated with latent variables, specifically with their posterior distribution given an observed input x.
基于概率模型,特征学习是恢复一组潜在的随机变量的尝试,这些变量描述了在观察到的数据上的分布。
学习是在估计一组模型参数(局部)的基础上进行的,这些模型参数在这些潜在变量的分布上最大化了训练数据的可能性。
概率图模型的2种建模方法 : 定向 与 非定向 图像模型 (两者区别:
推理和学习的算法方法的性质和计算代价。
)
5.1Directed Graphical Models 定向图像模型
通过对联合分布的分解,参数化了定向潜伏因子模型。
p(x, h) = p(x|h)p(h)
(1)
在潜在因素模型的背景下,定向模型的形式往往会导致一个重要的属性,即解释:
一个事件的先验独立原因可以在事件的观察中成为非独立的
。潜在的因子模型通常可以被解释为潜在的原因模型,其中h的激活导致观察到的x,这使得一个先验的独立h成为非独立的。
因此,恢复h, p(h | x)的后验分布(我们将其作为特征表示的基础),通常是计算上具有挑战性的,并且可能是完全难以处理的,特别是当h是离散的时候。
由于事件h 产生了 观察的x,因此h与x相关,h非独立
(2)Probabilistic Interpretation概率解释 of PCA (principal components analysis)
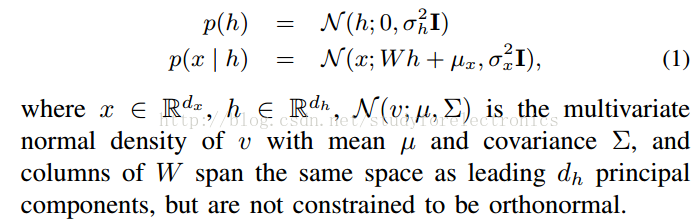
以上解释,可以使PCA 变为考虑的分析要素
(3)Sparse Coding 稀疏编码--只用于定向模型
与PCA一样,稀疏编码具有概率性和非概率性的解释。稀疏编码还涉及到一个潜在的表示h(随机变量的向量或特征向量,取决于解释)到数据x的一个
线性映射W,我们称之为字典
。稀疏编码和PCA的区别是,稀疏编码包括一个惩罚来确保稀疏激活h是用于编码每个输入x,可用于用于恢复特征向量编码
相对于RBMs和自动编码器等方法而言,稀疏编码中的推理涉及到一个
额外的优化内部循环
,这将使发现h与特征提取的计算成本相应增加。
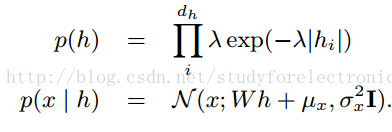
稀疏编码的概率表示,包含
拉普拉斯先验
,不同于PCA的表示
稀疏性标准也可以被成功地推广到更倾向于零的特性组,但是如果其中一个或几个是活跃的,那么在这个组中激活其他成员的惩罚就很小了。不同的群体稀疏模式可以包含不同形式的先验知识。
e.gSpike-and-Slab Sparse Coding
5.2 无向图模型 Undirected Graphical Models
无向图模型,也叫马尔科夫随机场Markov random fields (MRFs)
在无监督特征学习的背景下,我们通常会看到一种特定形式的马尔可夫随机场,它被称为波兹曼分布,其势约束为正。
一种特殊形式叫BM(Boltzmann machine
),其能力方程:
p是 非负的集团势,包括能力方程
一般来说,Boltzmannmachine
(BM)的推理是难以处理的。
然而,在可视化和隐藏单元之间的交互模式中有一些明智的选择,我们接下来将讨论模型家族中更易于处理的子集。
5.3 restricted Boltzmann machine (RBM)
--most popular
限制能量方程各因素间的相互作用
重要的是,RBM的可跟踪性并没有扩展到它的配分函数,它仍然包含了一个指数级的项。因此,我们仍需要估计值。
(1)RBM的实值数据推广
RBM中推理和学习的可追溯性启发了许多作者,通过
对其能量函数的修改
来扩展它,以建模其他类型的数据分布。
改进1: Gaussian RBM ——增加x^2的偏差值(唯一变化)
GRBM未能充分捕获自然图像的统计结构,其根源在于模型容量的唯一使用,即以
条件协方差为代价获取条件平均值。但是,
自然图像的主要特征是像素值的协方差,而不是它们的绝对值。
改进2:均值和协方差mean and covariance RBM (mcRBM) ——双层BM
将可见单位 建模为 高斯分布量。————训练困难
与GRBM不同的是,mcRBM使用它的隐藏层来通过两套隐藏单元来独立地参数化数据的均值和协方差。
改进3:mPoT model (mean-product of Student s T-distributions model)
一种基于能量的模型,其中对隐藏变量的可见单元的条件分布是一种多元高斯(非对角协方差),而在已知的隐变量上的附加条件分布是一组独立的伽玛分布。
应用:合成大规模的自然图像
改进4:spike-and-slab Restricted Boltzmann Machine (ssRBM)
目的:使隐藏单元对均值和协方差信息进行编码
定义:
与隐藏层中的每个单元相关联的具有一个实值的平板变量和一个二进制峰值变量。
效果图:

总结
- mcRBM、mPoT和ssRBM均对实值数据进行建模,使隐藏单元不仅对数据的条件均值进行编码,而且对其条件协方差进行编码。
- mcRBM和mPoT使用隐藏单元的激活来加强对x的协方差的约束,ssRBM使用隐藏单元沿对应的权重向量指定的方向缩放精度矩阵。当隐含层的维度与输入的维度有显著差异时,这两种建模条件协方差的方法是不同的。
- mPoT和mcRBM似乎并不适合在过于完整的设置中提供稀疏表示。
(2)RBM parameter estimation 训练RBM
方法都适用于更通用的无定向图形模型,但在RBM设置中尤其实用。
在训练概率模型参数时,通常是为了最大化训练数据的可能性(或等价于对数似然,或其惩罚的版本,这增加了正则化项)。
方法:在对数似然梯度的情况下,小步上坡,以找到可能的局部最大值。
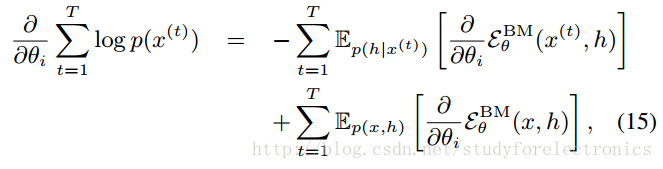
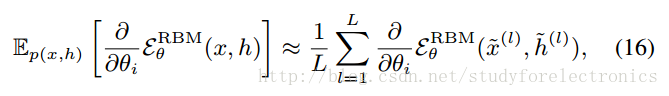
利用RBM的条件独立性来指定对关节期望的蒙特卡罗近似Ep。
此时充分的统计量(能量函数的梯度)与训练分布中的x或从模型中取样的x具有相等的期望。
缺点: 梯度更新使用Gibbs采样链,但是采样链会老化,以致不能实现训练
为了降低Gibbs
采样链老化
影响而采取的改进方法
(1)Contrastive divergence (CD) 对比散度
缩短
Gibbs采样链,以减少基于从短期运行的吉布斯采样器样本的负面期望的方差。
PS:
虽然从非常短的吉布斯链中抽取的样本可能是模型分布的严重偏倚(和差)表示,但它们至少在模型分布的方向上移动
(2)Stochastic Maximum Likelihood
随机极大似然(SML)算法(也称为持续对比散度或
persistent contrastive divergence
PCD)
SML使用一个持续运行的吉布斯链(或者通常是并行运行的吉布斯链数),从中抽取样本来估计负相期望。
尽管更新之间的模型参数发生了变化,但这些变化足够小。从吉布斯链的均衡分布(即模型分布)中维护样本只需要吉布斯(在实践中,通常使用了一个步骤)的几个步骤。
*通常,随着学习的进展和RBM的权重的增加,吉布斯样本的遍历性开始崩溃。
(3) fast-weights persistent contrastive divergence(FPCD)
来自SML吉布斯链的样品 使用负面相位梯度
negative phase of the gradient, 学习更新后,该样本的能量增加,被该模式重新取样的概率降低,被其他模式选取的概率增加。
(4)Pseudolikelihood, Ratio-matching and other Inductive Principles
拟似然、比率匹配等归纳原则
避免显式地处理配分函数,并分析了它们的渐近效率。
伪似然寻求将形式P (Xd | Xnd)的所有一维条件分布的乘积最大化,而比值匹配可以解释为分数匹配的扩展到离散数据类型。
缺点:计算每个训练数据点的所有邻居的统计数据需要
大量的计算开销
,与输入的维数线性地伸缩。
(5)其他的训练原则
- 噪声对比估计(Gutmann and Hyvarinen, 2010),其中训练准则转化为概率分类问题:区分(正)训练样本和(负)由广义分布产生的(如高斯分布)的噪声样本。
- 基于CD的 依赖于区分正面的例子(训练的分布)和一些消极的例子
6.直接编码:从输入到表示的学习参数映射
与概率模型的联系:
概率模型是由显式概率函数定义的,并经过训练以最大化(通常近似)数据可能性(或代理),自动编码器通过编码器和解码器进行参数化,并使用不同的训练原理进行训练。参数化的一个显著区别是,RBMs使用一个单独的权重矩阵,这是由它们的能量函数自然产生的,而自动编码器框架允许在编码器和解码器中使用不同的矩阵。
概率模型的框架内,总是学习表示与潜变量有关,特别是与后验分布给出一个观察输入x。
(a)不幸的是,如果模型有超过两个互联层,无论是直接的或间接的图形模型框架,潜在变量的后验分布给出输入往往变得非常复杂和棘手的。然后,需要采用抽样或近似推理技术,并支付相关的计算和近似错误价格。这是在非定向图形模型中难以解决的配分函数所带来的困难。
(b)此外,潜在变量的后验分布还不是一个简单的可用特征向量。因此,实际的特征值通常来自于该分布,以潜在变量s期望(通常用RBMs完成)、它们的边际概率或找到最有可能的值(就像在稀疏编码中一样)。
——————
所以,为了在最后提取出稳定的确定性的数值特征值,采用自动编码器和其他直接参数化特征或表示函数:学习直接编码(
从输入到其表示的参数映射
)
(1)Auto-encoder
训练自动编码器变体的一个实际优点是,
它们定义了一个简单的可跟踪优化目标,可以用来监视进程。
A practical advantage of training auto-encoder variants is that they define a simple tractable optimization objective that can be used to monitor progress.
为了将重构误差最小化,以捕获数据生成分布的结构,因此,在训练准则或参数化过程中,一定要防止自动编码器学习自身函数,从而在任何地方产生零重建错误。
基础的auto-encoder训练在于找到一个值的参数向量θ,以重建误差最小化
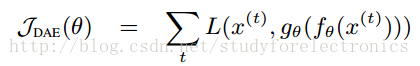
(2)正则自动编码器Regularized Auto-Encoders
传统上,像PCA这样的自动编码器主要被看作是一种降维技术,因此使用了瓶颈,即dh < dx。但是,稀疏编码和RBM方法的成功使用倾向于学习过度完整的表示,即dh > dx。
这可能使自动编码问题过于简单。
瓶颈效应或这些正则化条件的影响是,自动编码器不能重建所有的东西,它被训练来重建训练的例子。
两个正则化的自动编码器的变体:收缩的自动编码器通过使编码器收缩来减少表示(在每个点附近)的有效自由度的数量(使编码器的导数小(从而使隐藏单元饱和)),而去噪自动编码器使整个映射更加健壮(鲁棒性更好)(对微小的随机扰动或收缩不敏感,确保在训练样本周围的大部分方向上,不能很好重建。)
改进1:Sparse Auto-Encoders 稀疏
当直接惩罚隐层单元时,有很多变体,但没有文章比较他们哪一个更好
。虽然L1 penalty看上去最自然,但很少SAE的文章用到。一个类似的规则是student-t penalty
改进2:Denoising Auto-Encoders 去噪
去除一个人工制造的噪声点,指向附近高密度的点
噪声类型:additive isotropic Gaussian noise, salt and pepper noise for gray-scale images, and masking noise (salt or pepper only)
改进3: Contractive Auto-Encoders 对比
加入一个解析收缩惩罚项(
the Frobenius norm of the encoder s Jacobian
),
将学习特征的灵敏度与输入的无穷小变化相结合
CAE拥有更好性能的原因:
a)特征的敏感性是直接的,而不是重建的敏感性;
b)惩罚是分析性的,而不是随机的:一个有效的可计算表达式取代了原本可能需要的dx腐败样本的大小(即dx方向的灵敏度);
c)hyper-parameter
超参数
λ允许精细控制的重建与鲁棒性之间的权衡。
CAE分析惩罚的一个潜在缺点是,它只会鼓励对输入的无穷小变化的鲁棒性。
CAE的学习表示往往是饱和的,而不是稀疏的
改进4: Predictive Sparse Decomposition(PSD)
PSD是sparse coding和AE的一个变种,目标函数为:
PSD可以看做是sparse coding的近似,只是多了一个约束,可以将稀疏编码近似为一个参数化的编码器。
7.Representation Learning As Manifold Learning
based on the geometric notion of manifold.
基于流形的几何概念
其前提是多重假设
根据在高维空间中呈现的真实世界的数据,预计将集中在大量
低维度
dM,嵌入在高维的输入空间Rdx中。
在这些非参数化方法中,每个高维的训练点都有自己的一套自由的低维嵌入坐标,这是最优化的,使得在原始的高维输入空间中计算的邻域图的某些性质得到了最好的保护。
(1)
Learning a parametric mapping based on a neighborhood graph
学习基于邻域图的参数映射。
2种方法:
(a)
基于训练集的邻域图。
通常是从训练点之间的成对欧几里得距离推导出来的
原理:这些坐标现在通过在输入空间坐标上的显式参数化函数得到,它的参数是要学习的。
在非参数化版本中,同样的优化目标可以通过梯度下降最小化:现在,在嵌入的坐标上,梯度下降不再是梯度下降,而是反向传播到映射函数的参数。
(b)
学习直接编码的方法是半监督嵌入
一个深度参数化的神经网络体系结构同时学习了多重嵌入和分类器。
在优化监督分类成本的同时,训练标准还利用每个训练实例的训练集邻域来鼓励在改变一个邻居的训练样本时,中间层次的表示保持不变。
然而,在高维度空间(由于维数的限制而导致稀少)的基础上,基于训练集邻里关系的模型建立模型,可能是有风险的,因为大多数的欧几里得近邻的邻居在语义上都有太少的风险。
(2)Learning a non-linear manifold through a coding scheme 通过编码方案学习一个非线性的流形。
在非线性表征学习算法中,可以很方便地考虑输入中的局部变量。即使配对是随机挑选的,在获得一个对优化目标有重大影响的指标之前,也必须考虑很多。
对于与非饱和隐藏单元相关联的输入空间方向,x的计算表示法只会非常敏感(如sigmoid层的雅可比矩阵)
精确的低维流形模型(如PCA)会产生非零的奇异值,这些值与流形上的方向相关联,而与流形正交的方向则是精确的零。但是在平滑的模型中,例如收缩自动编码器或RBM,我们将会有较大的相对较小的奇异值(相对于非零和完全为零的)。CAE确实模拟了一个低维流形的切线空间。
主要的奇异向量构成了估计流形的切平面的基础。

(3)Leveraging the modeled tangent spaces
利用建模的
切线空间
。
在流形上的一个点上,局部的切线空间可以考虑捕捉在训练数据中突出的局部有效转换。
在数据流形上的这种非常局部的转换不希望改变类的标识。
为了构建它们的歧义分类器(MTC),采用切距等技术,构建对输入变形不敏感的分类器。
应用于
由CAE中的局部主切线方向,即不使用任何先验知识(除了广泛的先验存在之外)。
8.
GLOBAL TRAINING OF DEEP MODELS
how should we jointly train all the levels?
在上一节中,我们只讨论了如何将单层模型组合成一个具有联合训练标准的深度模型。
在这里,我们考虑联合训练所有级别和可能出现的困难。
(1)
On the Training of Deep Architectures
更高层次的抽象意味着更多的非线性。 高级抽象需要更少的数据进行学习,但是由于增加了非线性,使得更抽象的表示函数和训练都更困难。
无监督或监督分层的培训更容易,这可以利用将单层模型叠加到较深的模型中。
先学习更简单的概念,然后在简单的概念之上构建更高层次的概念。
改变优化过程的数值条件
会对深层架构的联合训练产生深远的影响,例如改变初始化范围和改变使用的非线性类型(Glorot和Bengio, 2010),这比浅层架构的影响要大得多。一个假设解释了深层架构优化的一些困难,主要集中在与从一个层次的特性转换到下一个级别的特性相关的雅可比矩阵的奇异值(Glorot和Bengio, 2010)。
如果这些奇异值都是小的(小于1),那么映射在每个方向上都是收缩的,当向后传播多个层时,梯度就会消失。
-------选择初始化(使每一层的雅可比矩阵所有奇异值接近1)可以大大减少深层网络的训练难度
想法1:
将每个隐藏单元输出的平均值和斜率(Raiko et al., 2012)和可能局部正常化的值(Jarrett et al., 2009)取消。
在使用诸如随机梯度下降法和使用大量小批量(数千个例子)的二阶方法等在线方法之间的争论仍然存在。
想法2:
在适当的初始化和非线性选择的情况下,可以成功地训练非常深的纯监督网络,而不需要任何分层的预训练。
无
监督的预训练作为先验,当大量有标记的数据可用时,这可能就不那么必要了。-----依赖于GPU高效训练
(2)
Joint Training of Deep Boltzmann Machines
联合训练的所有层的一个特定的无监督模型——深度玻尔兹曼机(DBM)
DBM拥有多层隐藏单元,在奇数层中有条件独立于偶数层的单元,反之亦然。
方法1:Mean-field approximate inference
平均场近似推理
方法2:Training Deep Boltzmann Machines 训练DBM
基于sml的算法最大限度地实现了这个下界,如下:
1)将可见单元夹在一个训练示例中。
2)迭代Eq.(31-32)直到收敛。
3)通过SML生成负相样品v、h(1)和h(2)。
4)使用在步骤2 - 3获得的值,计算 。
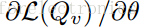
5)最后,用近似随机梯度上升的步骤更新模型参数。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









