







个人感觉B+树来源于B树(表象),也不来来源于B树(思想)。
背后的思想不同:B+树元素自底向上插入,背后的想法是内部节点可以有在预定范围内的可变数目的子节点。因此,B+树不需要象其他自平衡二叉查找树那样经常的重新平衡。对于特定的实现在子节点数目上的低和高边界是固定的。引用自百度百科
B+树在节点访问时间(比对查找)远远超过节点内部访问时间的时候,比可作为替代的实现有着实在的优势。这通常在多数节点在次级存储比如硬盘中的时候出现。通过最大化在每个内部节点内的子节点的数目减少树的高度,平衡操作不经常发生,而且效率增加了。这种价值得以确立通常需要每个节点在次级存储中占据完整的磁盘块或近似的大小。
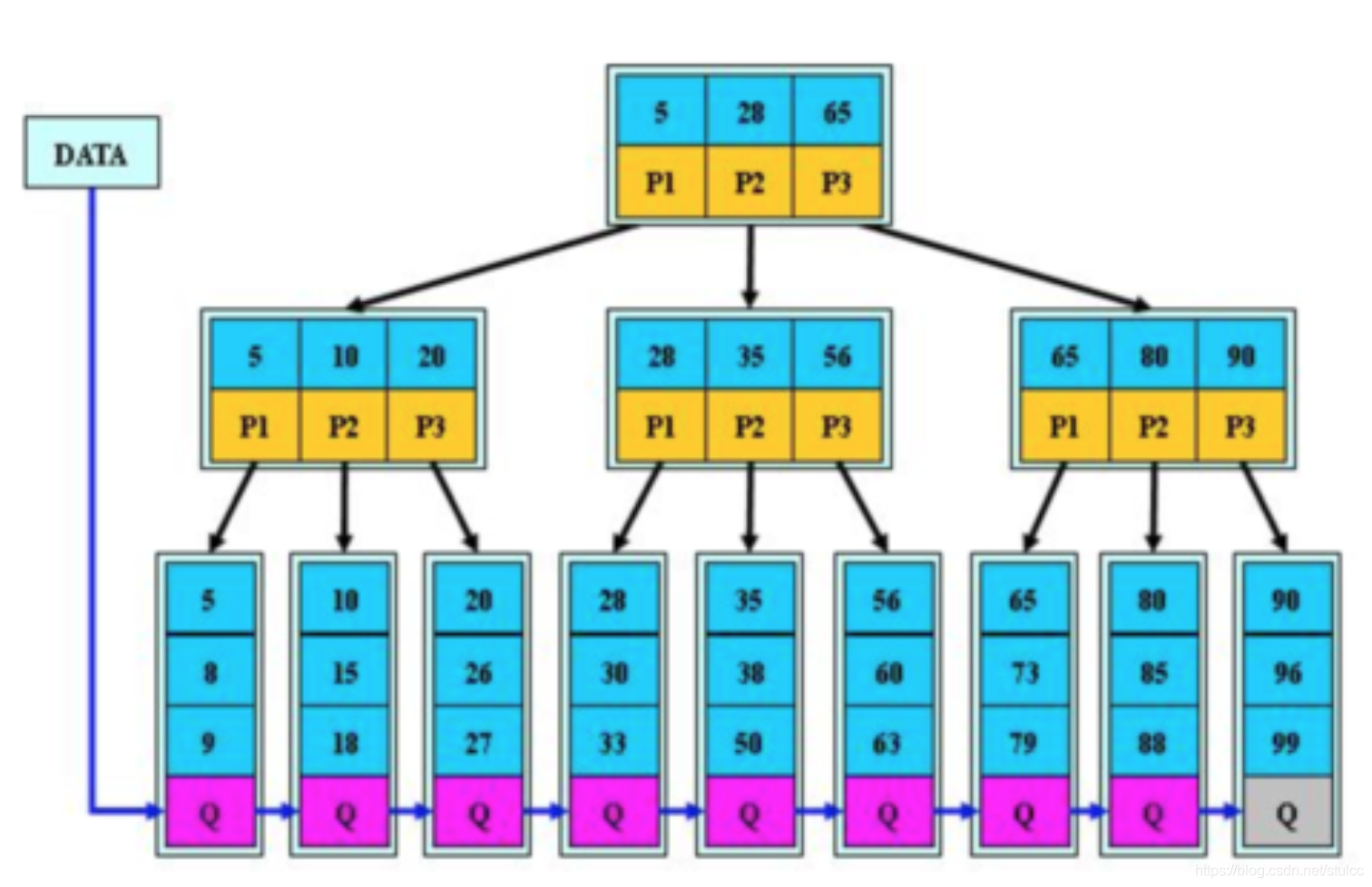
规则
(1)B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加;
(2)B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样;
(3)B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
(4)非叶子节点的子节点数=关键字数(来源百度百科)(根据各种资料 这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(来源维基百科),虽然他们数据排列结构不一样,但其原理还是一样的Mysql 的B+树是用第一种方式实现);
B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
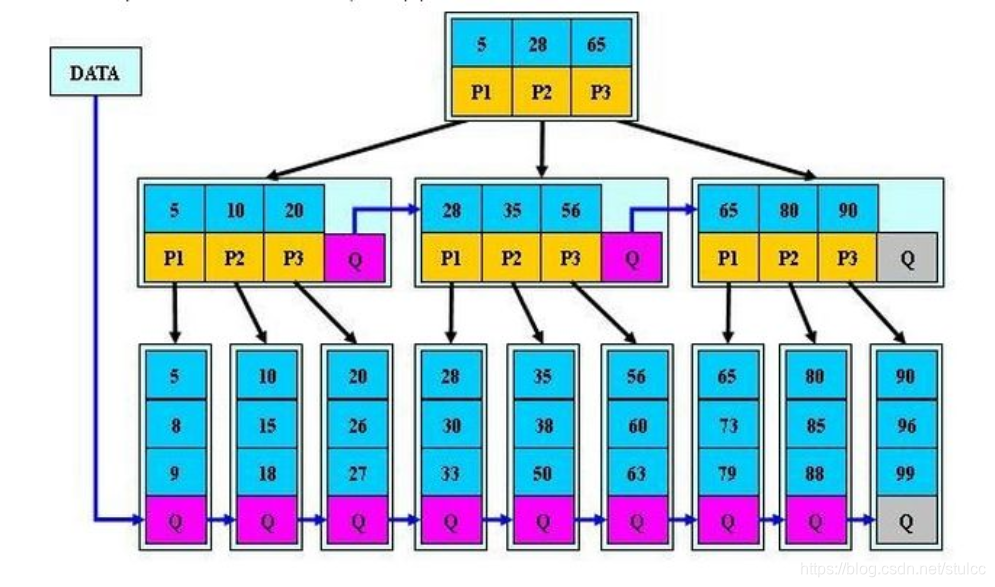
B*树
B*树是B+树的变种,相对于B+树他们的不同之处如下:
(1)首先是关键字个数限制问题,B+树初始化的关键字初始化个数是cei(m/2),b树的初始化个数为(cei(2/3m))
(2)B+树节点满时就会分裂,而B*树节点满时会检查兄弟节点是否满(因为每个节点都有指向兄弟的指针),如果兄弟节点未满则向兄弟节点转移关键字,如果兄弟节点已满,则从当前节点和兄弟节点各拿出1/3的数据创建一个新的节点出来;
特点
在B+树的基础上因其初始化的容量变大,使得节点空间使用率更高,而又存有兄弟节点的指针,可以向兄弟节点转移关键字的特性使得B*树额分解次数变得更少;
问题:B+树的关键字个数为何和子节点个数相同,B树却不是,有什么意义?














 474
474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









