









转自:http://blog.csdn.net/zhang1bao2/article/details/77800941
MobileNet
(1)文章介绍
- google 201704在archive上的论文。
- 采用depthwise separable卷积核,减少计算量和模型大小。
- 引入了两个超参数,用于选择合适大小的模型。
- 在imagenet, object dectection, face atrributes,分类等任务上验证了效果。
(2)核心思想
将标准卷积层分解为depthwise conv和 pointwise conv(1*1)两个卷积层。即一个depthwise separable卷积核包括depth wise卷积操作和pointwise卷积操作。
对于标准卷积,输入大小为D_f*D_f*M,输出大小为D_f *D_f *N,卷积核的大小为D_k*D_k*M*N。(这里假设stride为 1,padding=0, 因此长宽不变)
标准卷积计算: F和G分别表示输入和输出特征图,(s=0, p=1, h_o = h_in -k + 1)
计算量分析:(要计算出D_f * D_f个值, 计算每个值需要对应的所有对应滑动窗口的值相乘,然后所有通道的值相加merge, 这里加法的计算量忽略不计)
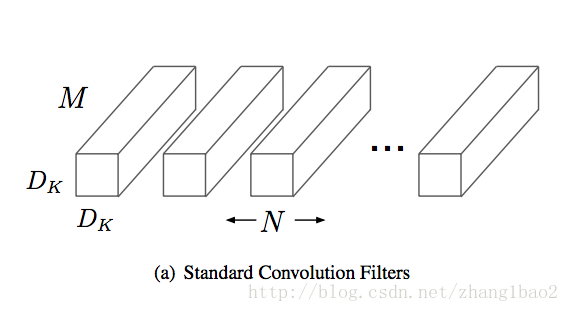
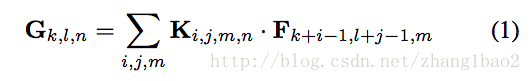
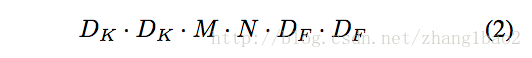
第一步为depth wise卷积
对于输入的每一个通道分别用1个D_k * D_k*1的卷积核进行卷积,共使用了M个卷积核,操作M次,得到M个D_f * D_f * 1的特征图。这些特征图分别是从输入的不同通道学习而来,彼此独立。
depth wise计算(注意与标准卷积对比,求和的下标里面没有m, 说明其实各个通道是独立的,这里将m次操作表达为一个公式,论文中也表述depth wise kernel大小为D_k * D_k * M, 但这个跟标准卷积核不一样,M不代表卷积核的通道数)
计算量分析: (需要计算出 D_f * D_ f个值,每次的计算量为 D_k * D_k, 循环M次)
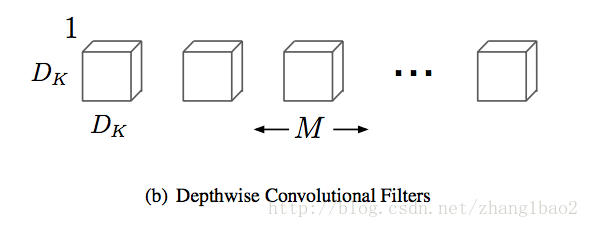
第二步为point wise卷积
对于上一步得到的M个特征图作为M个通道的输入,用N个1*1*M的卷积核进行标准卷积,得到D_f * D_f * N的输出。
计算量分析: 计算量按标准卷积的公式,其中D_k = 1, 计算量为1*1*M*N*D_f*D_f
节约计算量分析:
一般卷积核为3*3,计算量能节省9倍左右。
(3)网络结构设计
- 局部结构
- 输入第一层不用deptwise separable convolution
- 每一层后面接bn与relu.(除了最后一层全连接层不接非线性直接接入softmax)
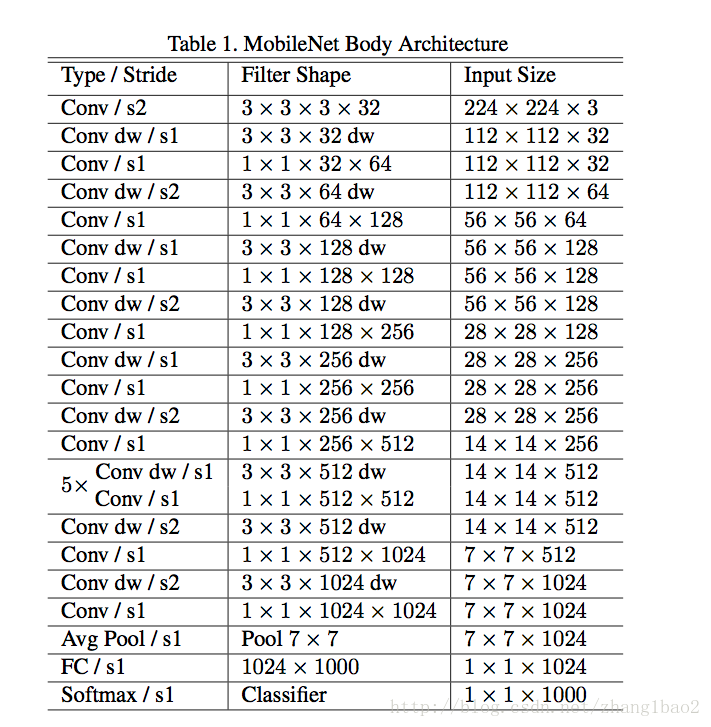
总的网络结构
- 下采样部分通过第一层卷积以及某些 depth wise convolution的stride =2实现。
- 最后一层的average pooling是为了把输出分辨率压缩到1*1
- Mobile Net共28层

(3)实验经验
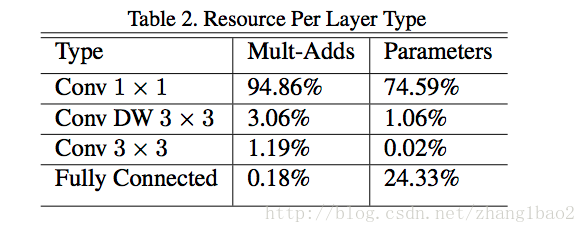
- 基本上所有的计算量均集中在1*1的conv操作上, GEMM的方法中有im2col的步骤,1*1conv不需要这个recording步骤。
- 对于depth wise filters采用很小或没有的weight decay(L2 regularization)
(4)新的超参数
width multiplier: thinner models
将某个层的将输入和输出的channel 均压缩α
倍
resolution multiplier:Reduced Representation
将网络输入的大小降至224,192,160,128,可以将计算量减少 ρ2因子ρ
倍
将网络变瘦比将网络变浅的效果要好,说明网络深度的重要性。














 6601
6601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









