



我的目的是将数值版的文件与文本版的文件进行配对,再筛选出是否删除中为否的数值版数据作为分析的原始数据。
但是我写的比较复杂,应该说是步骤很多,程序应该可以再简洁一些
import numpy as np
import pandas as pd
df1=pd.read_excel('C:\\Users\\username\\Desktop\\data1.xlsx')
df2=pd.read_csv('C:\\Users\\username\\Desktop\\data2.csv')
#数据写入,其中df1是文本版,df2是数值版数据
#数据合并
df3=pd.merge(df1,df2,on='ID')
#数据筛选
df4=df3.loc[df3['是否删除']=='否']
#数据提取
#从df4中提取列,因为df4是两个文件合并在一起的,只需提取数值版的列+答题ID,在excel中填充数字看是第几列,再对应选取(方法一)
#方法二
df6=df4.iloc[0:942,[1]]
df7=df4.iloc[0:942,101:194]
df=pd.DataFrame()
#再次做数据合并
df=pd.concat([df6,df7],axis=1)
df
df.to_excel('C:\\Users\\username\\Desktop\\df.xlsx',index=False)
这里还想留存自用一些数据提取的语法
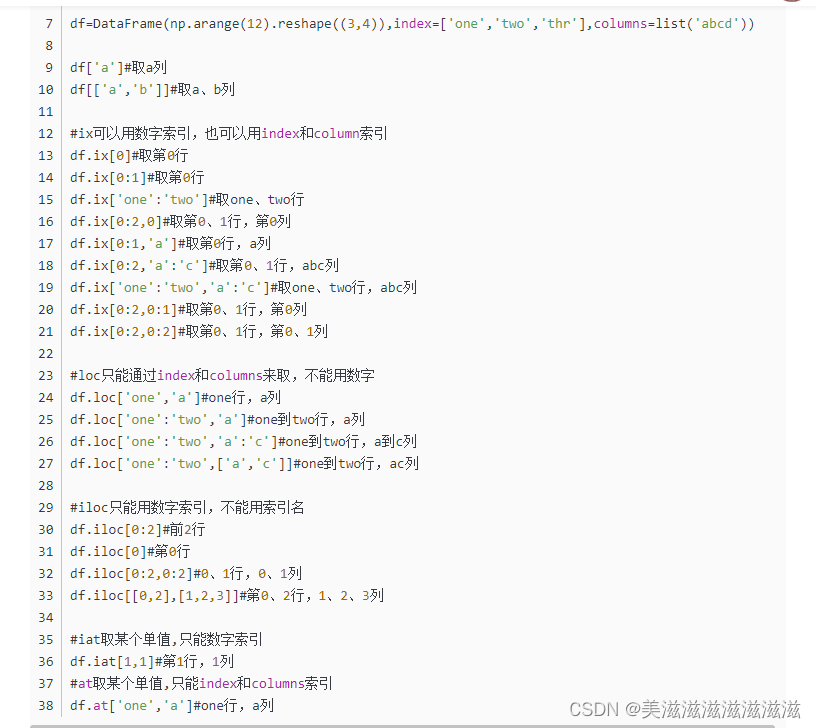

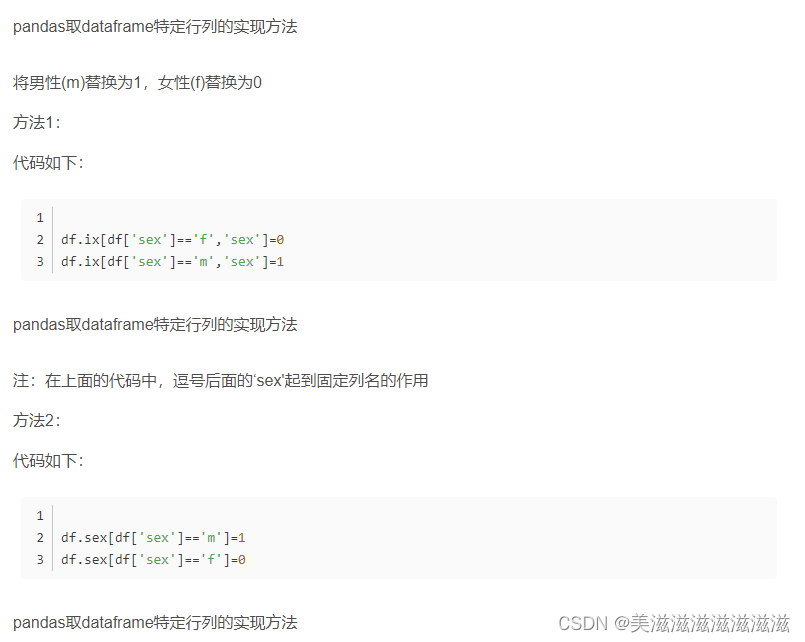

以上方法来源于https://blog.csdn.net/u012559269/article/details/127528883,创作者@OhYeah~李若愚,如果侵权请联系我删除此部分
还有一些数据合并的方法
分别是merge和concat
指路:https://blog.csdn.net/DiAsdream/article/details/124887452?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169664944016800215013003%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=169664944016800215013003&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-124887452-null-null.142v94chatsearchT3_1&utm_term=merge&spm=1018.2226.3001.4187
(这个链接是merge 的使用方法)
https://blog.csdn.net/qq_34160248/article/details/122573719?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169664954616800225520113%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=169664954616800225520113&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-2-122573719-null-null.142v94chatsearchT3_1&utm_term=python%20%20concat&spm=1018.2226.3001.4187
(这个链接是concat的使用方法)
这里不能用到去重的方法,去重只能针对一列下的重复数据,针对不了重复列,也指定不了去除前列还是后列,所以去重不可行,只能是抽取写出。

















 525
525




 到【灌水乐园】发言
到【灌水乐园】发言







