







引言
本篇内容为通过flask加ajax完成对web微信的模拟登录,直到获取到完整信息,
web微信
web微信即为微信PC客户端网页版,即可连接键盘,在网页上收发会话消息,事实上,微信扫码实际上是通过长轮询实现的,如果看过我之前的有一篇博文,flask+ajax实现轮询和长轮询,里面详细介绍了长轮询的概念,如果有些忘记的可以再去复习一下,那么懂了这一点,我们便可以来创建二维码了。微信扫码登录网址如下:
创建二维码
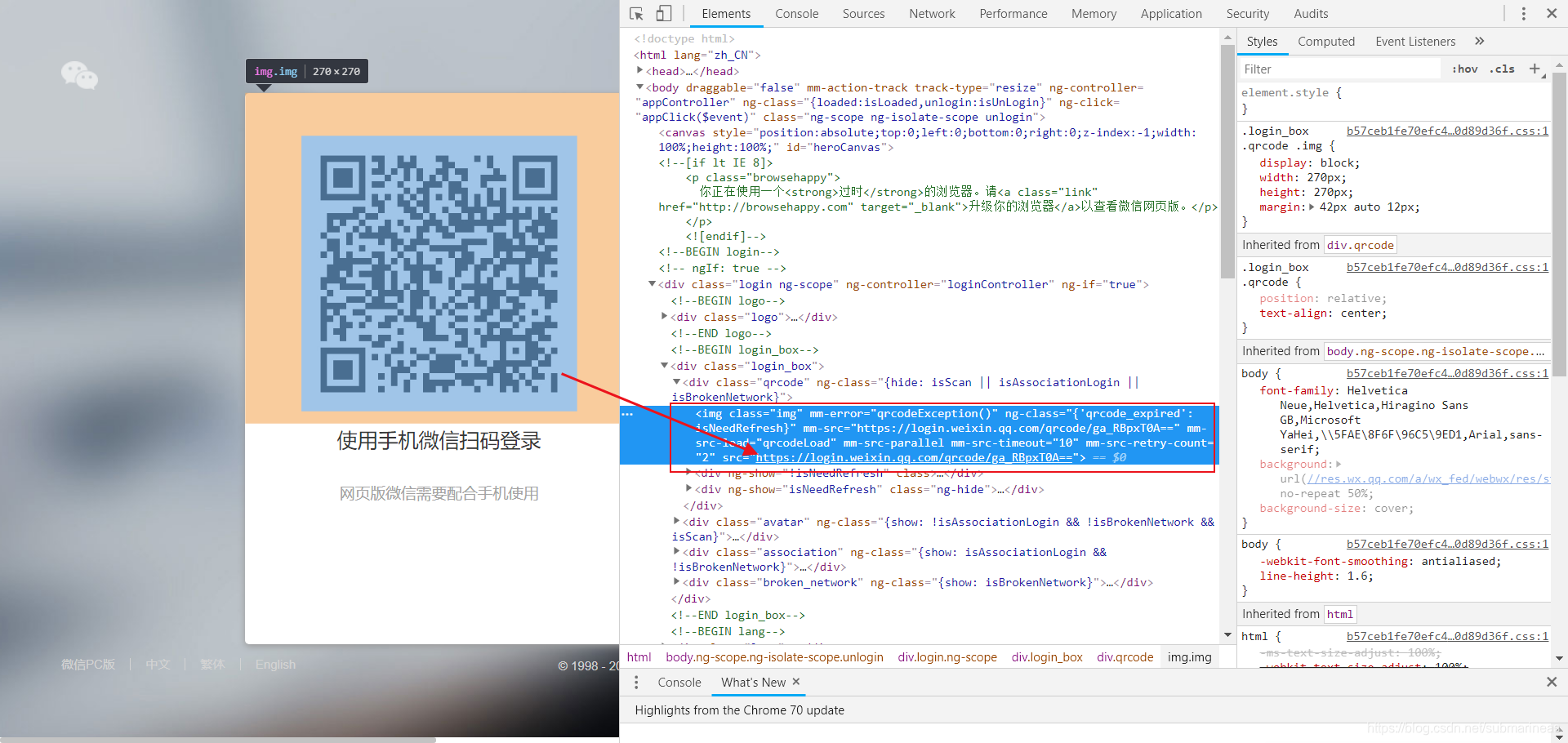
首先我们进入官网后便可以分析当前网页的模式,按F12查看源代码,然后我们发现二维码位于img标签下的src链接里,即https://login.weixin.qq.com/qrcode/ga_RBpxT0A==,这和csdn也很类似,同时我们也能够发现,当我们刷新网页时,上面网址/qrcode/后的ga_RBpxT0A==是随机变换的,所以就是这个在改变二维码图片,那么很容易就想到是对某个url发送了特定的请求,然后我们进入network中找到了相应的response,那么便找到了这个请求,另外,我们可以看下图的最后三个同样的以及状态码为408的请求,这个便是长轮询的体现,实时的在等待,只要我们拿起手机扫码,立马就会获得响应。
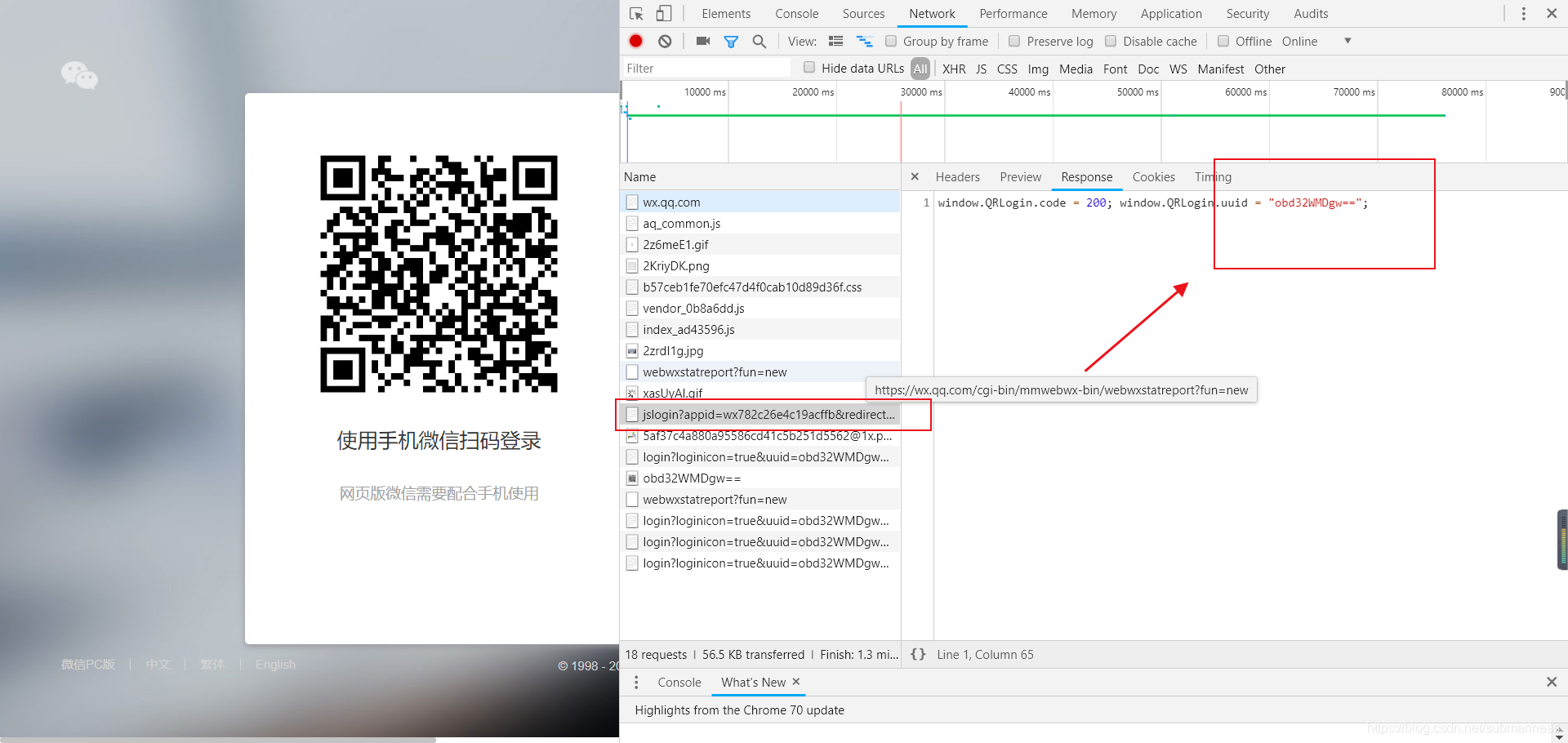
好了,既然我们知道了该请求,那么接下来就是通过flask和正则模拟向这个url发起同样的请求,同时前端还要写一个相应的页面,这里可以先把固定的写出来,比如说不考虑请求,直接复制我上面那段ga_RBpxT0A= =的src地址,然后有图片再动态化,考虑到篇幅问题我们直接列出完整的了,后端代码如下:
import re
import time
import requests
from flask import Flask, render_template
app = Flask(__name__)
app.secret_key = 'fawdwfa1234'
@app.route('/login')
def login():
ctime = int(time.time() * 1000)
qcode_url = "https://login.wx.qq.com/jslogin?appid=wx782c26e4c19acffb&redirect_uri=https%3A%2F%2Fwx.qq.com%2Fcgi-bin%2Fmmwebwx-bin%2Fwebwxnewloginpage&fun=new&lang=zh_CN&_={0}".format(
ctime)
rep = requests.get(
url=qcode_url
)
# print(rep.text) # window.QRLogin.code = 200; window.QRLogin.uuid = "gb8UuMBZyA==";
qcode = re.findall('uuid = "(.*)";', rep.text)[0]
return render_template('login.html', qcode=qcode)
if __name__ == '__main__':
app.run()
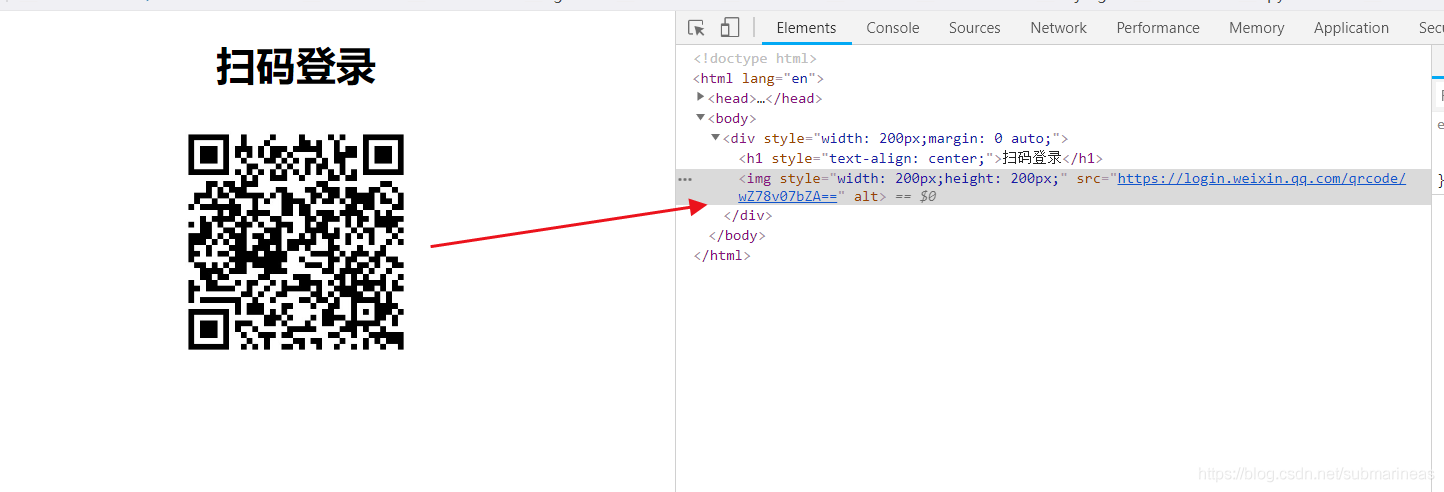
qcode_url前面那一段url没有改变,就最后的时间戳,这里的时间戳在原有基础上少了最后三位,那么我们乘上1000就相当于和这里的一样了,所以才能发送请求,示例页面如下,我们可以发现创建的二维码也能随着页面刷新而改变:
模拟登录
上面已经创建好了一张动态的二维码,但这个二维码仅仅只有展示的效果。我们可以回看官网的步骤,当我们完成扫码后,首先是在页面上二维码会变成扫码者微信的头像,然后手机这时候就可以进行确认登录了,一旦确认登录被验证,那么网页端就可以进入相应的聊天界面进行真正的聊天,大概的意思就是这样,所以我们现如今要完善的,便是扫码登录的功能,后端提供相应的头像,前端需要构造长轮询,以至于能立即更改为头像框。
接下来我们更进一步的分析,首先是前端要构造出长轮询,以至于后端才能将数据传送给前端并立刻替换掉二维码,所以我们的长轮询ajax部分的代码为:
$(function () {
checkLogin(); // 页面加载完就执行checklogin
});
function checkLogin() {
$.ajax({
url:'/check/login',
method:'GET',
dataType:'json',
success:function (arg) {
console.log(arg);
checkLogin(); // 回调checklogin
}
而后端部分,找到一直在pending的request URL,同样发现一段很长的请求,那么和上面创建时的一样,我们需要模拟这个请求,但我们发现这个url其实是有两段需要拼接的信息。我们去微信登录看看:
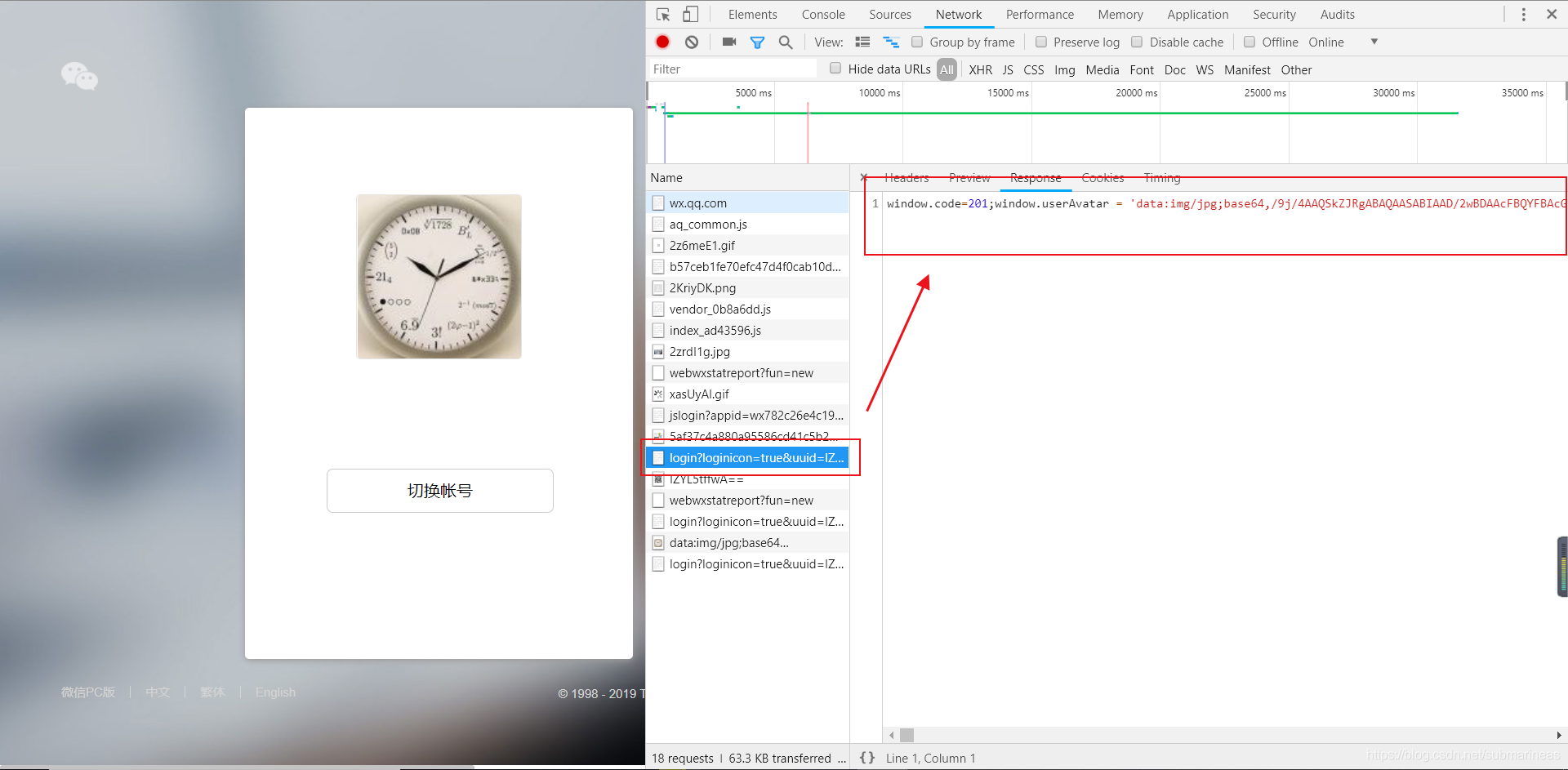
前面一段是上面uuid=IZYL5tffwA== 是二维码状态的延续,所以我们在二维码用session来存储这个信息,这里从session里取即可完成拼接,后面的1553857484581依然还是时间戳,所以我们乘上1000即可完成拼接。
@app.route('/check/login')
def check_login():
qcode = session['qcode']
ctime = int(time.time() * 1000)
check_login_url = 'https://login.wx.qq.com/cgi-bin/mmwebwx-bin/login?loginicon=true&uuid={0}&tip=0&r=-976036168&_={1}'.format(qcode,ctime)
rep = requests.get(
url=check_login_url
)
result = {'code': 408}
if 'window.code=408' in rep.text:
# 用户未扫码
result['code'] = 408
elif 'window.code=201' in rep.text:
# 用户扫码,获取头像
result['code'] = 201
result['avatar'] = re.findall("window.userAvatar = '(.*)';",rep.text)[0]
elif 'window.code=200' in rep.text:
# 用户确认登录
redirect_uri = re.findall('window.redirect_uri="(.*)";',rep.text)[0]
print(redirect_uri)
result['code'] = 200
return jsonify(result)
然后我们还可以分析响应状态码,在微信这里,408为pending,即等待登录状态,而201看上图,为获取头像的状态码,我们还可以发现状态码后面的userAvatar,那就是我的头像。所以,后端部分需要截取出图像出来,通过jsonify返回result字典,然后再前端显示:
$(function () {
checkLogin();
});
function checkLogin() {
$.ajax({
url:'/check/login',
method:'GET',
dataType:'json',
success:function (arg) {
if(arg.code === 408){
checkLogin();
}else if(arg.code === 201){
$('#userAvatar').attr('src',arg.avatar);
checkLogin();
}else if(arg.code === 200){
location.href = "/index"
}
}
})
}
arg.code == 200的跳转可以再在后端补充一个index接口,然后加一个index页面。那么就可以在手机上显示详情页面了,但登录要出现聊天框还有验证消息。
获取验证信息
获取验证信息同样和上面登录是一样的,相当于我们要写一个跳转的url,而这个跳转的url还有点坑的地方在于,它并不是普通的url,至少它是在我们的手机上确认登录后,后端提示给我们的状态码是200的情况下,再拼接了一段地址,见下图所示,即redirect_uri + “&fun=new&version=v2”,那么我们同样需要按照它的方式来,拿到这个url并获取response。
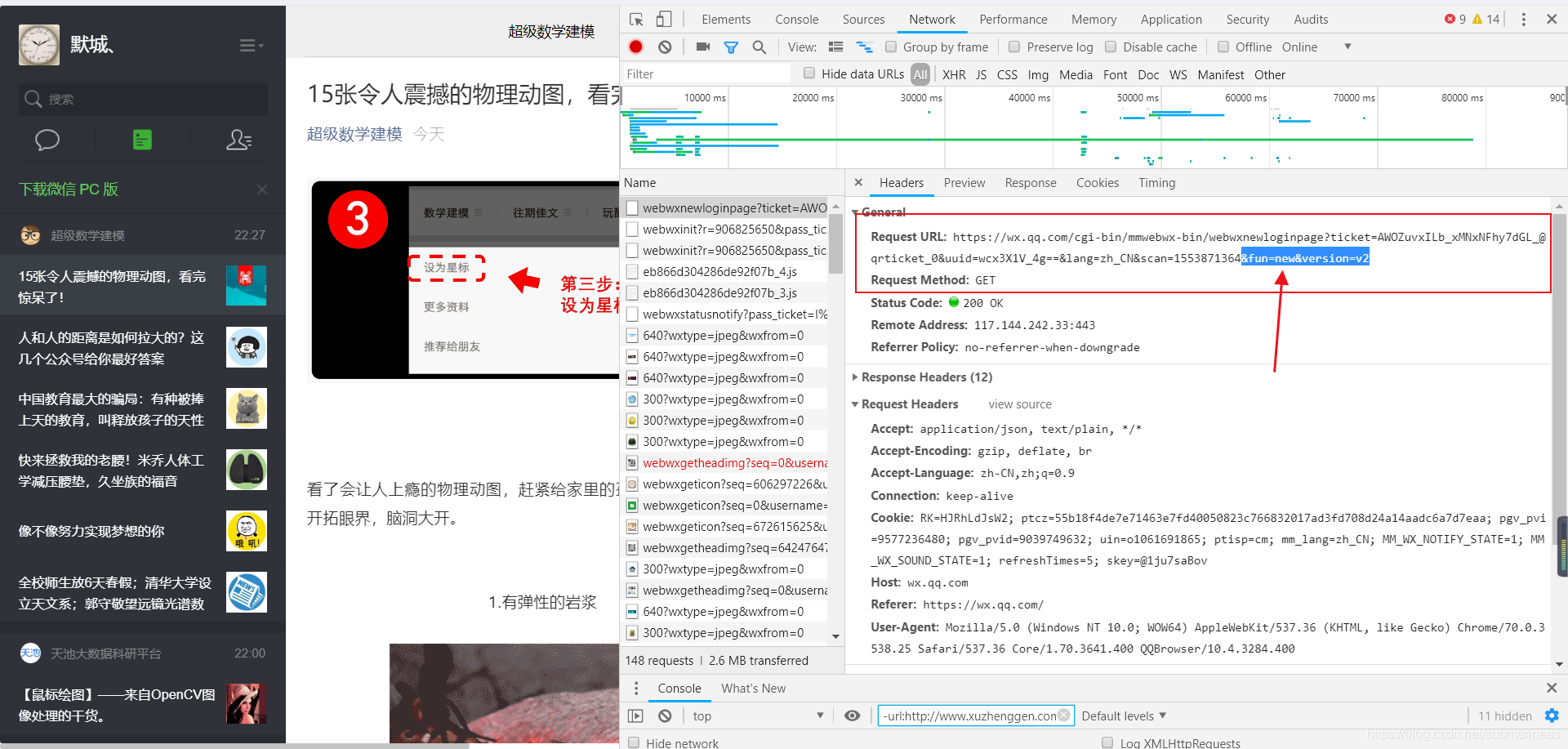
我们还可以通过观察这个接收得到的response是什么,在notepad++进行整理如下:
<error>
<ret>0</ret>
<message></message>
<skey>@crypt_818405e_7cd9b808bc444003e0f56027ac4c4503</skey>
<wxsid>9PD0qel98e+VYQI</wxsid>
<wxuin>2173758581</wxuin>
<pass_ticket>I%2FHz7vKRhhnisJMQ8P%2F7yC4P6KCfIXDVqbqYL0vc6BL51iQlKctfRLw9s5JiLA%2BW</pass_ticket>
<isgrayscale>1</isgrayscale>
</error>
上面这个是xml,xml是一种特殊的形式,在html之前,XML被设计为传输和存储数据,其焦点是数据的内容,而HTML被设计用来显示数据。这里回应中的xml提供了我们登录后进行聊天操作的凭证,这里有ret、skey、wxwin、pass_ticket/我们可以从其他url的一些拼接中可以看到。所以现在我们的目的应该是从该url爬取到相关的凭证,那么我们可以写一个离线的小脚本,这里可以使用beautifulsoup来试试:
from bs4 import BeautifulSoup
def xml_parse(text):
result = {}
soup = BeautifulSoup(text,'html.parser')
tag_list = soup.find(name='error').find_all()
for tag in tag_list:
result[tag.name] = tag.text
return result
res = "<error><ret>0</ret><message></message><skey>@crypt_818405e_7cd9b808bc444003e0f56027ac4c4503</skey><wxsid>9PD0qel98e+VYQI</wxsid><wxuin>2173758581</wxuin><pass_ticket>I%2FHz7vKRhhnisJMQ8P%2F7yC4P6KCfIXDVqbqYL0vc6BL51iQlKctfRLw9s5JiLA%2BW</pass_ticket><isgrayscale>1</isgrayscale></error>"
result = xml_parse(res)
print(result)
"""
{'ret': '0', 'message': '', 'skey': '@crypt_8185405e_7cd9b808bc44003e0f56027ac4c4503', 'wxsid': '9PD0iqel98e+VYQI', 'wxuin': '2173758581', 'pass_ticket': 'I%2FHz7vKRhhnisJMQ8P%2F7yC4P6KCfXDVqbqYL0vc6BL51iQlKctfRLw9s5JiLA%2BW', 'isgrayscale': '1'}
"""
展示用户信息
上面我们拿到了存储我们验证信息的xml数据,我们也用BS4进行了抓取,所以下一步就能通过这些抓取到的凭证来对获取用户信息的url发送请求,我们可以看下图,在真正的微信网页版上,找到真正获取用户信息的,然后我们可以看到它的response具体是什么样的。
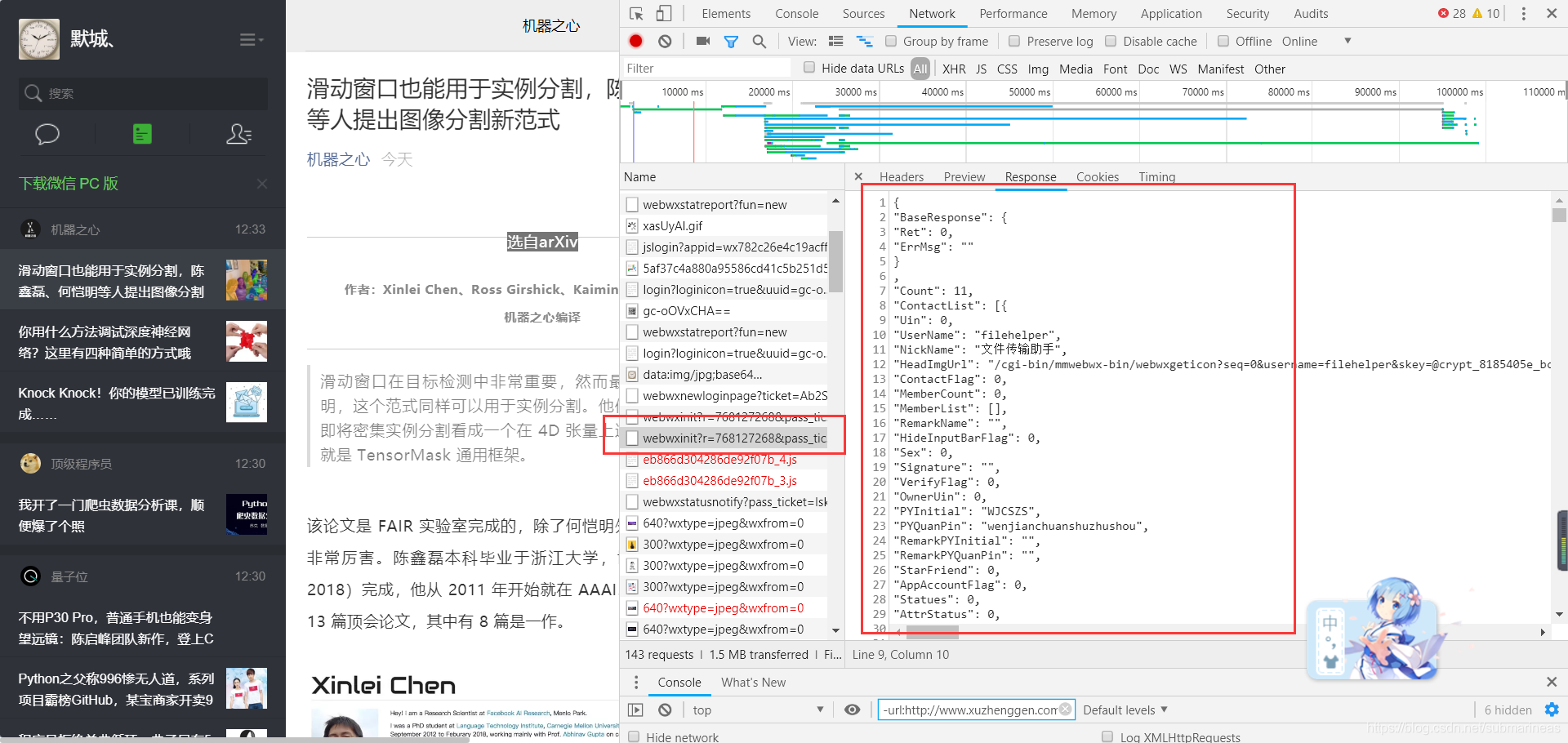
我们发现想要获取到的用户联系人的信息被ContactList这个列表包起来了,而我们的公众号信息是被MemberList,所以如果是post请求,后端只需要向该地址拼接一些我们xml中取得的验证信息,这个信息是通过session传递,然后前端照着它给的信息格式用for循环取信息就够了。但我们需要注意的是这个请求是post,我们看请求头发现,有一些我们需要携带的信息,这些信息作为一种验证方式,并且会帮助我们做初始化。
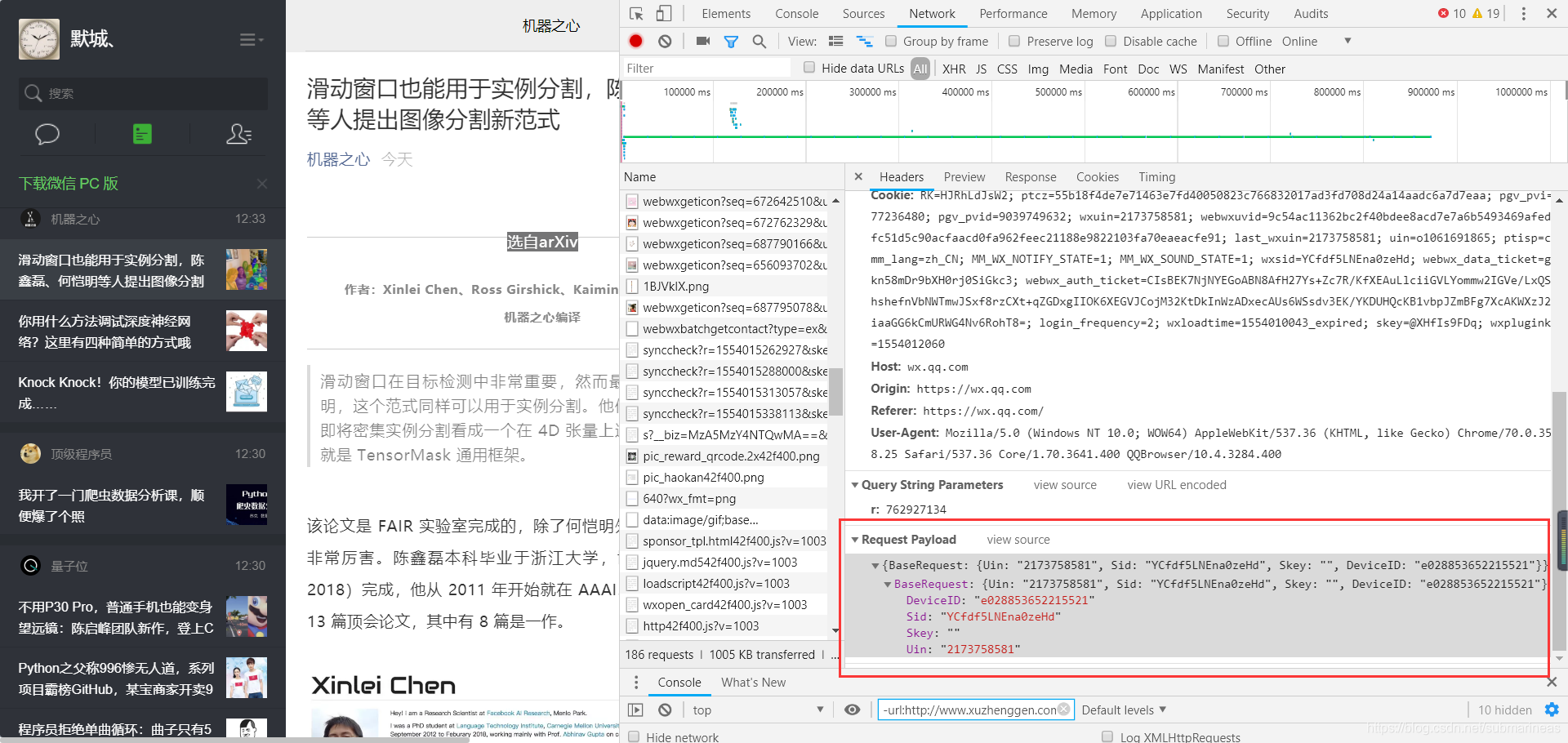
所以代码为:
@app.route('/index')
def index():
pass_ticket = session['ticket_dict']['pass_ticket']
init_url = "https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxinit?r=-979112921&lang=zh_CN&pass_ticket={0}".format(pass_ticket)
rep = requests.post(
url=init_url,
json={
'BaseRequest':{
'DeviceID':"e700290354098676",
'Sid':session['ticket_dict']['wxsid'],
'Skey':session['ticket_dict']['skey'],
'Uin':session['ticket_dict']['wxuin'],
}
}
)
rep.encoding = 'utf-8'
init_user_dict = rep.json()
print(init_user_dict)
return render_template('index.html',init_user_dict=init_user_dict)

然后我们就能获取到相关信息了,后端也有显示。但还只是部分的,如果要拿到全部信息,还要再做一次检验,如果要拿到用户头像,这里还有一些检验。但后面的关键就主要是cookies了。
获取全部用户信息
从上面来看,我们获取的只能算是最近联系人信息,而如果我们需要全部的联系人,以及他们的头像等信息,还需要做一个跳转,而这里就主要与cookies有关了。所以代码为:
@app.route('/contact/list')
def contack_list():
ctime = int(time.time() * 1000)
pass_ticket = session['ticket_dict']['pass_ticket']
skey = session['ticket_dict']['skey']
contact_url = "https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxgetcontact?lang=zh_CN&pass_ticket={0}&r={1}&seq=0&skey={2}".format(pass_ticket,ctime,skey)
res = requests.get(
url=contact_url,
cookies=session['ticket_cookies']
)
res.encoding = 'utf-8'
user_list = res.json()
return render_template('contact_list.html',user_list=user_list)
这里就不再解释了,所以我们整理一下,flask的逻辑代码为:
import re
import time
import requests
import json
from flask import Flask,render_template,session,jsonify,request
from bs4 import BeautifulSoup
app = Flask(__name__)
app.secret_key = 'fawdwfa1234'
def xml_parse(text):
result = {}
soup = BeautifulSoup(text,'html.parser')
tag_list = soup.find(name='error').find_all()
for tag in tag_list:
result[tag.name] = tag.text
return result
@app.route('/login')
def login():
ctime = int(time.time() * 1000)
qcode_url = "https://login.wx.qq.com/jslogin?appid=wx782c26e4c19acffb&redirect_uri=https%3A%2F%2Fwx.qq.com%2Fcgi-bin%2Fmmwebwx-bin%2Fwebwxnewloginpage&fun=new&lang=zh_CN&_={0}".format(ctime)
rep = requests.get(
url=qcode_url
)
# print(rep.text) # window.QRLogin.code = 200; window.QRLogin.uuid = "gb8UuMBZyA==";
qcode = re.findall('uuid = "(.*)";',rep.text)[0]
session['qcode'] = qcode
return render_template('login.html',qcode = qcode)
@app.route('/check/login')
def check_login():
qcode = session['qcode']
ctime = int(time.time() * 1000)
check_login_url = 'https://login.wx.qq.com/cgi-bin/mmwebwx-bin/login?loginicon=true&uuid={0}&tip=0&r=-976036168&_={1}'.format(qcode,ctime)
rep = requests.get(
url=check_login_url
)
result = {'code': 408}
if 'window.code=408' in rep.text:
# 用户未扫码
result['code'] = 408
elif 'window.code=201' in rep.text:
# 用户扫码,获取头像
result['code'] = 201
result['avatar'] = re.findall("window.userAvatar = '(.*)';",rep.text)[0]
elif 'window.code=200' in rep.text:
# 用户确认登录
redirect_uri = re.findall('window.redirect_uri="(.*)";',rep.text)[0]
print(redirect_uri)
redirect_uri = redirect_uri + "&fun=new&version=v2"
ru = requests.get(url=redirect_uri)
# <error><ret>0</ret><message></message><skey>@crypt_ac8812af_0ffde1190007c7c044bc31ae51407c45</skey><wxsid>fRwfacRtjRFpEIwt</wxsid><wxuin>1062220661</wxuin><pass_ticket>0M1plebTzNQ%2FKaSIfTfk65laCSXUWmjpxvJEerZSnBaEDjNIyOafaQLtpQBhnCDa</pass_ticket><isgrayscale>1</isgrayscale></error>
ticket_dict = xml_parse(ru.text)
session['ticket_dict'] = ticket_dict
session['ticket_cookies'] = ru.cookies.get_dict()
result['code'] = 200
return jsonify(result)
@app.route('/index')
def index():
pass_ticket = session['ticket_dict']['pass_ticket']
init_url = "https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxinit?r=-979112921&lang=zh_CN&pass_ticket={0}".format(pass_ticket)
rep = requests.post(
url=init_url,
json={
'BaseRequest':{
'DeviceID':"e700290354098676",
'Sid':session['ticket_dict']['wxsid'],
'Skey':session['ticket_dict']['skey'],
'Uin':session['ticket_dict']['wxuin'],
}
}
)
rep.encoding = 'utf-8'
init_user_dict = rep.json()
# print(init_user_dict)
return render_template('index.html',init_user_dict=init_user_dict)
@app.route('/contact/list')
def contack_list():
ctime = int(time.time() * 1000)
pass_ticket = session['ticket_dict']['pass_ticket']
skey = session['ticket_dict']['skey']
contact_url = "https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxgetcontact?lang=zh_CN&pass_ticket={0}&r={1}&seq=0&skey={2}".format(pass_ticket,ctime,skey)
res = requests.get(
url=contact_url,
cookies=session['ticket_cookies']
)
res.encoding = 'utf-8'
user_list = res.json()
return render_template('contact_list.html',user_list=user_list)
总结
本篇初步完成了对web微信的一些信息的获取,主要还是要熟悉长轮询机制,懂它的原理,另外就是提升一下分析网页的能力,完善一下爬虫知识。
其实获取微信好友的信息、头像,以及发送信息等,还可以直接借助于微信已经给出的第三方接口,下一篇我考虑可以调用微信的第三方,然后对微信好友以及朋友圈等等做一个可视化,这个我过年的时候就玩过,网上都有现成代码,并且实验楼里做过相关的实验。只不过当时时间很紧,我并没有做任何记录,趁着有时间的时候,我准备另写一篇博文分析一下。
参考与推荐:
[1]. Flask–网页微信登陆示例
[2]. 基于Flask 实现Web微信登陆















 318
318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











