









1 什么是MapReduce?
Map本意可以理解为地图,映射(面向对象语言都有Map集合),这里我们可以理解为从现实世界获得或产生映射。Reduce本意是减少的意思,这里我们可以理解为归并前面Map产生的映射。
2 MapReduce的编程模型
按照google的MapReduce论文所说的,MapReduce的编程模型的原理是:利用一个输入key/value对集合来产生一个输出的key/value对集合。MapReduce库的用户用两个函数表达这个计算:Map和Reduce。用户自定义的Map函数接受一个输入的key/value对值,然后产生一个中间key/value对值的集合。MapReduce库把所有具有相同中间key值的中间value值集合在一起后传递给Reduce函数。用户自定义的Reduce函数接受一个中间key的值和相关的一个value值的集合。Reduce函数合并这些value值,形成一个较小的value值的集合。
3 MapReduce实现
通过将Map调用的输入数据自动分割为M个数据片段的集合,Map调用被分布到多台机器上执行。输入的数据片段能够在不同的机器上并行处理。使用分区函数将Map调用产生的中间key值分成R个不同分区(例如,hash(key) mod R),Reduce调用也被分布到多台机器上执行。分区数量(R)和分区函数由用户来指定。
MapReduce实现的大概过程如下:
1.用户程序首先调用的MapReduce库将输入文件分成M个数据片度,每个数据片段的大小一般从16MB到64MB(可以通过可选的参数来控制每个数据片段的大小)。然后用户程序在集群中创建大量的程序副本。
2.这些程序副本中的有一个特殊的程序master。副本中其它的程序都是worker程序,由master分配任务。有M个Map任务和R个Reduce任务将被分配,master将一个Map任务或Reduce任务分配给一个空闲的worker。
3.被分配了map任务的worker程序读取相关的输入数据片段,从输入的数据片段中解析出key/value对,然后把key/value对传递给用户自定义的Map函数,由Map函数生成并输出的中间key/value对,并缓存在内存中。
4.缓存中的key/value对通过分区函数分成R个区域,之后周期性的写入到本地磁盘上,会产生R个临时文件。缓存的key/value对在本地磁盘上的存储位置将被回传给master,由master负责把这些存储位置再传送给Reduce worker。
5.当Reduce worker程序接收到master程序发来的数据存储位置信息后,使用RPC从Map worker所在主机的磁盘上读取这些缓存数据。当Reduce worker读取了所有的中间数据(这个时候所有的Map任务都执行完了)后,通过对key进行排序后使得具有相同key值的数据聚合在一起。由于许多不同的key值会映射到相同的Reduce任务上,因此必须进行排序。如果中间数据太大无法在内存中完成排序,那么就要在外部进行排序。
6.Reduce worker程序遍历排序后的中间数据,对于每一个唯一的中间key值,Reduce worker程序将这个key值和它相关的中间value值的集合(这个集合是由Reduce worker产生的,它存放的是同一个key对应的value值)传递给用户自定义的Reduce函数。Reduce函数的输出被追加到所属分区的输出文件。
上面过程中的排序很容易理解,关键是分区,这一步最终决定该键值对未来会交给哪个reduce任务,如统计单词出现的次数可以用前面说的hash(key) mod R来分区,如果是对数据进行排序则应该根据key的分布进行分区。
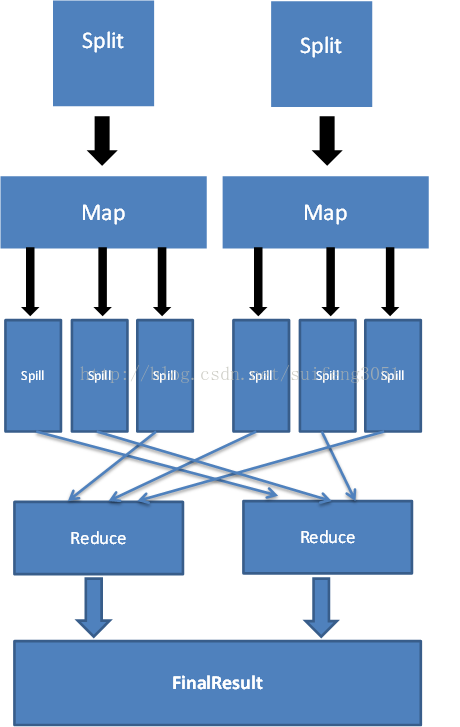
图1 MapReduce过程
4 例子
假设我们需要处理一批有关天气的数据,其格式如下: 按照ASCII码存储,每行一条记录,每一行字符从0开始计数,第15个到第18个字符为年,第25个到第29个字符为温度,其中第25位是符号+/-,现在需要统计出每年的最高温度。
0067011990999991950051507+0000+
0043011990999991950051512+0022+
0043011990999991950051518-0011+
0043012650999991949032412+0111+
0043012650999991949032418+0078+
0067011990999991937051507+0001+
0043011990999991937051512-0002+
0043011990999991945051518+0001+
0043012650999991945032412+0002+
0043012650999991945032418+0078+
MapReduce主要包括两个步骤:Map和Reduce 每一步都有key/value对作为输入和输出:
Map阶段的key/value对的格式是由输入的格式所决定的,如果是默认的TextInputFormat,则每行作为一个记录进程处理,其中key为此行的开头相对于文件的起始位置,value就是此行的字符文本,Map阶段的输出的key/value对的格式必须同Reduce阶段的输入key/value对的格式相对应
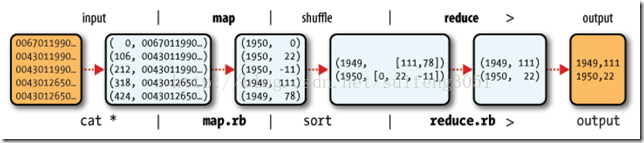
对于上面的例子,在map过程,输入的key-value对如下:
(0 ,0067011990999991950051507+0000+)
(1 ,0043011990999991950051512+0022+)
(2 ,0043011990999991950051518-0011+)
(3 ,0043012650999991949032412+0111+)
(4 ,0043012650999991949032418+0078+)
(5 ,0067011990999991937051507+0001+)
(6 ,0043011990999991937051512-0002+)
(7 ,0043011990999991945051518+0001+)
(8 ,0043012650999991945032412+0002+)
(9 ,0043012650999991945032418+0078+)
将上面的数据作为用户编写的map函数的输入,通过对每一行字符串的解析,得到年/温度的key/value对作为输出:
(1950, 0)
(1950, 22)
(1950, -11)
(1949, 111)
(1949, 78)
(1937, 1)
(1937, -2)
(1945, 1)
(1945, 2)
(1945, 78)
在Reduce过程,将map过程中的输出,按照相同的key将value放到同一个列表中作为用户写的reduce函数的输入
(1950, [0, 22, –11])
(1949, [111, 78])
(1937, [1, -2])
(1945, [1, 2, 78])
在Reduce过程中,在列表中选择出最大的温度,将年/最大温度的key/value作为输出:
(1950, 22)
(1949, 111)
(1937, 1)
(1945, 78)
其逻辑过程可用如下图表示:
参考:
http://desert3.iteye.com/blog/865243
http://www.cnblogs.com/duguguiyu/archive/2009/02/28/1400278.html















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









