







因为我们现在要处理31个省的数据,但是每个省的数据量都很大,顺序执行是在太慢了。本来想用多线程,但是都是类里面的方法,用起来也很扯淡,所以就选择了多进程。
fork()函数
#include <unistd.h>
//On success, The PID of the process is returned in the parent, and 0 is returned in the child. On failure,
//-1 is returned in the parent, no child process is created, and errno is set appropriately.
pid_t fork (void);在操作系统的基本概念中进程是程序的一次执行,且是拥有资源的最小单位和调度单位(在引入线程的操作系统中,线程是最小的调度单位)。在Linux系统中创建进程有两种方式:一是由操作系统创建,二是由父进程创建进程(通常为子进程)。系统调用函数fork()是创建一个新进程的唯一方式,当然vfork()也可以创建进程,但是实际上其还是调用了fork()函数。fork()函数是Linux系统中一个比较特殊的函数,其一次调用会有两个返回值,下面是fork()函数的声明:
当程序调用fork()函数并返回成功之后,程序就将变成两个进程,调用fork()者为父进程,后来生成者为子进程。这两个进程将执行相同的程序文本,但却各自拥有不同的栈段、数据段以及堆栈拷贝。子进程的栈、数据以及栈段开始时是父进程内存相应各部分的完全拷贝,因此它们互不影响。从性能方面考虑,父进程到子进程的数据拷贝并不是创建时就拷贝了的,而是采用了写时拷贝(copy-on -write)技术来处理。调用fork()之后,父进程与子进程的执行顺序是我们无法确定的(即调度进程使用CPU),意识到这一点极为重要,因为在一些设计不好的程序中会导致资源竞争,从而出现不可预知的问题。
#include<stdio.h>
#include<unistd.h>
#include <sys/types.h>
#include<vector>
#include <iostream>
using namespace std;
int main()
{
string sMatch;
pid_t pid;
vector<string> provList;
provList.push_back("100");
provList.push_back("200");
provList.push_back("300");
provList.push_back("400");
provList.push_back("500");
cout<<"main process,id="<<getpid()<<endl;
//循环处理"100,200,300,400,500"
for (vector<string>::iterator it = provList.begin(); it != provList.end(); ++it)
{
sMatch=*it;
pid = fork();
//子进程退出循环,不再创建子进程,全部由主进程创建子进程,这里是关键所在
if(pid==0||pid==-1)
{
break;
}
}
if(pid==-1)
{
cout<<"fail to fork!"<<endl;
exit(1);
}
else if(pid==0)
{
//这里写子进程处理逻辑
cout<<"this is children process,id="<<getpid()<<",start to process "<<sMatch<<endl;
sleep(10);
exit(0);
}
else
{
//这里主进程处理逻辑
cout<<"this is main process,id="<<getpid()<<",end to process "<<sMatch<<endl;
exit(0);
}
return 0;
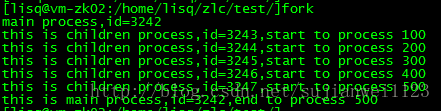
}运行效果如下图:














 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









