







 本文介绍了决策树的基本概念,包括信息熵、数据集划分和最优特征选择,并提供了Python代码实现的概述。
本文介绍了决策树的基本概念,包括信息熵、数据集划分和最优特征选择,并提供了Python代码实现的概述。
一、一些定义:
1. 信息: 西瓜有好瓜和坏瓜,好瓜的信息为
l(xi)=−log2p(xi)
p(xi)
为好瓜的概率,根据-log函数的图像,如果好瓜的概率越大,信息会趋近于0,也就是从一堆瓜里选出好瓜所需要的信息量越少。
2. 信息熵:熵是信息的期望值
Ent(D)=−∑k=1npklog2pk
D是西瓜数据集,Ent(D)的值越小,D的纯度越高。
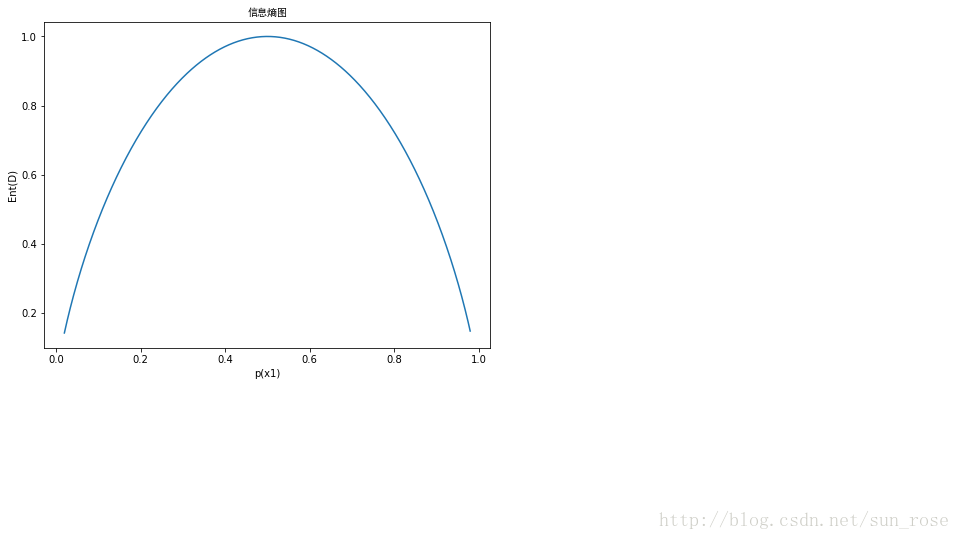
在西瓜只分为好瓜和坏瓜的情况下,p(x1)是好瓜的概率,p(x2)为坏瓜的概率,p(x1)+p(x2)=1,这时候信息熵在它们均为0.5时达到最大,若是纯度较高,即好瓜的概率较大,则信息熵比较小。
3.信息增益:假定离散属性a有V个可能的取值,若使用属性a对样本集D进行划分,则会有V个分支节点,第v个分支节点上的样本 Dv
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 96
96

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









