







http://blog.csdn.net/cutesource/article/details/5811914
在IDF05(Intel Developer Forum 2005)上,Intel首席执行官Craig Barrett就取消4GHz芯片计划一事,半开玩笑当众单膝下跪致歉,给广大软件开发者一个明显的信号,单纯依靠垂直提升硬件性能来提高系统性能的时代已结束,分布式开发的时代实际上早已悄悄地成为了时代的主流,吵得很热的云计算实际上只是包装在分布式之外的商业概念,很多开发者(包括我)都想加入研究云计算这个潮流,在google上通过“云计算”这个关键词来查询资料,查到的都是些概念性或商业性的宣传资料,其实真正需要深入的还是那个早以被人熟知的概念------分布式。
分布式可繁也可以简,最简单的分布式就是大家最常用的,在负载均衡服务器后加一堆web服务器,然后在上面搞一个缓存服务器来保存临时状态,后面共享一个数据库,其实很多号称分布式专家的人也就停留于此,大致结构如下图所示:

这种环境下真正进行分布式的只是web server而已,并且web server之间没有任何联系,所以结构和实现都非常简单。
有些情况下,对分布式的需求就没这么简单,在每个环节上都有分布式的需求,比如Load Balance、DB、Cache和文件等等,并且当分布式节点之间有关联时,还得考虑之间的通讯,另外,节点非常多的时候,得有监控和管理来支撑。这样看起来,分布式是一个非常庞大的体系,只不过你可以根据具体需求进行适当地裁剪。按照最完备的分布式体系来看,可以由以下模块组成:
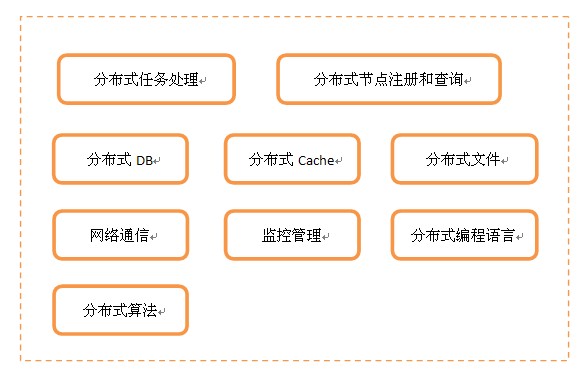
分布式任务处理服务:负责具体的业务逻辑处理
分布式节点注册和查询:负责管理所有分布式节点的命名和物理信息的注册与查询,是节点之间联系的桥梁
分布式DB:分布式结构化数据存取
分布式Cache:分布式缓存数据(非持久化)存取
分布式文件:分布式文件存取
网络通信:节点之间的网络数据通信
监控管理:搜集、监控和诊断所有节点运行状态
分布式编程语言:用于分布式环境下的专有编程语言,比如Elang、Scala
分布式算法:为解决分布式环境下一些特有问题的算法,比如解决一致性问题的Paxos算法
因此,若要深入研究云计算和分布式,就得深入研究以上领域,而这些领域每一块的水都很深,都需要很底层的知识和技术来支撑,所以说,对于想提升技术的开发者来说,以分布式来作为切入点是非常好的,可以以此为线索,探索计算机世界的各个角落。
分布式设计与开发中有些疑难问题必须借助一些算法才能解决,比如分布式环境一致性问题,感觉以下分布式算法是必须了解的(随着学习深入有待添加):
- Paxos算法
- 一致性Hash算法
Paxos算法
1)问题描述
分布式中有这么一个疑难问题,客户端向一个分布式集群的服务端发出一系列更新数据的消息,由于分布式集群中的各个服务端节点是互为同步数据的,所以运行完客户端这系列消息指令后各服务端节点的数据应该是一致的,但由于网络或其他原因,各个服务端节点接收到消息的序列可能不一致,最后导致各节点的数据不一致。举一个实例来说明这个问题,下面是客户端与服务端的结构图:
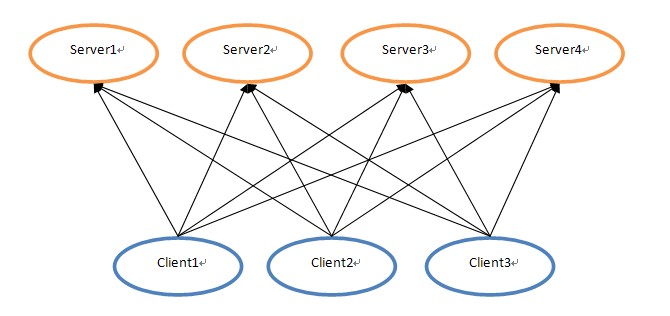
当client1、client2、client3分别发出消息指令A、B、C时,Server1~4由于网络问题,接收到的消息序列就可能各不相同,这样就可能由于消息序列的不同导致Server1~4上的数据不一致。对于这么一个问题,在分布式环境中很难通过像单机里处理同步问题那么简单,而Paxos算法就是一种处理类似于以上数据不一致问题的方案。
2)算法本身
算法本身我就不进行完整的描述和推导,网上有大量的资料做了这个事情,但我学习以后感觉莱斯利·兰伯特(Leslie Lamport,paxos算法的奠基人,此人现在在微软研究院)的Paxos Made Simple 是学习paxos最好的文档,它并没有像大多数算法文档那样搞一堆公式和数学符号在那里吓唬人,而是用人类语言让你搞清楚Paxos要解决什么问题,是如何解决的。这里也借机抨击一下那些学院派的研究者,要想让别人认可你的成果,首先要学会怎样让大多数人乐于阅读你的成果,而这个描述Paxos算法的文档就是我们学习的榜样。
言归正传,透过Paxos算法的各个步骤和约束,其实它就是一个分布式的选举算法,其目的就是要在一堆消息中通过选举,使得消息的接收者或者执行者能达成一致,按照一致的消息顺序来执行。其实,以最简单的想法来看,为了达到大伙执行相同序列的指令,完全可以通过串行来做,比如在分布式环境前加上一个FIFO队列来接收所有指令,然后所有服务节点按照队列里的顺序来执行。这个方法当然可以解决一致性问题,但它不符合分布式特性,如果这个队列down掉或是不堪重负这么办?而Paxos的高明之处就在于允许各个client互不影响地向服务端发指令,大伙按照选举的方式达成一致,这种方式具有分布式特性,容错性更好。
说到这个选举算法本身,可以联想一下现实社会中的选举,一般说来都是得票者最多者获胜,而Paxos算法是序列号更高者获胜,并且当尝试提交指令者被拒绝时(说明它的指令所占有的序列号不是最高),它会重新以一个更好的序列参与再次选举,通过各个提交者不断参与选举的方式,达到选出大伙公认的一个序列的目的。也正是因为有这个不断参与选举的过程,所以Paxos规定了三种角色(proposer,acceptor,和 learner)和两个阶段(accept和learn),三种角色的具体职责和两个阶段的具体过程就见Paxos Made Simple ,另外一个国内的哥们写了个不错的PPT ,还通过动画描述了paxos运行的过程。不过还是那句话不要一开始就陷入算法的细节中,一定要多想想设计这些游戏规则的初衷是什么。
Paxos算法的最大优点在于它的限制比较少,它允许各个角色在各个阶段的失败和重复执行,这也是分布式环境下常有的事情,只要大伙按照规矩办事即可,算法的本身保障了在错误发生时仍然得到一致的结果。
3)算法的实现
Paxos的实现有很多版本,最有名的就是google chubby ,不过看不了源码。开源的实现可见libpaxos 。另外,ZooKeeper 也基于paxos解决数据一致性问题,也可以看看它是如果实现paxos的。
4)适用场景
弄清楚paxos的来龙去脉后,会发现它的适用场景非常多,Tim有篇blog《Paxos在大型系统中常见的应用场景》 专门谈这个问题。我所见到的项目里,naming service是运用Paxos最广的领域,具体应用可参考ZooKeeper
一致性Hash算法
1)问题描述
分布式常常用Hash算法来分布数据,当数据节点不变化时是非常好的,但当数据节点有增加或减少时,由于需要调整Hash算法里的模,导致所有数据得重新按照新的模分布到各个节点中去。如果数据量庞大,这样的工作常常是很难完成的。一致性Hash算法是基于Hash算法的优化,通过一些映射规则解决以上问题
2)算法本身
对于一致性Hash算法本身我也不做完整的阐述,有篇blog《一致性hash算法 - consistent hashing》 描述这个算法非常到位,我就不重复造轮子了。
实际上,在其他设计和开发领域我们也可以借鉴一致性Hash的思路,当一个映射或规则导致有难以维护的问题时,可以考虑更一步抽象这些映射或规则,通过规则的变化使得最终数据的不变。一致性hash实际就是把以前点映射改为区段映射,使得数据节点变更后其他数据节点变动尽可能小。这个思路在操作系统对于存储问题上体现很多,比如操作系统为了更优化地利用存储空间,区分了段、页等不同纬度,加了很多映射规则,目的就是要通过灵活的规则避免物理变动的代价
3)算法实现
一致性Hash算法本身比较简单,不过可以根据实际情况有很多改进的版本,其目的无非是两点:
- 节点变动后其他节点受影响尽可能小
- 节点变动后数据重新分配尽可能均衡
实现这个算法就技术本身来说没多少难度和工作量,需要做的是建立起你所设计的映射关系,无需借助什么框架或工具,sourceforge上倒是有个项目libconhash ,可以参考一下
以上两个算法在我看来就算从不涉及算法的开发人员也需要了解的,算法其实就是一个策略,而在分布式环境常常需要我们设计一个策略来解决很多无法通过单纯的技术搞定的难题,学习这些算法可以提供我们一些思路。
分布式设计与开发中有些疑难问题必须借助一些算法才能解决,比如分布式环境一致性问题,感觉以下分布式算法是必须了解的(随着学习深入有待添加):
- Paxos算法
- 一致性Hash算法
Paxos算法
1)问题描述
分布式中有这么一个疑难问题,客户端向一个分布式集群的服务端发出一系列更新数据的消息,由于分布式集群中的各个服务端节点是互为同步数据的,所以运行完客户端这系列消息指令后各服务端节点的数据应该是一致的,但由于网络或其他原因,各个服务端节点接收到消息的序列可能不一致,最后导致各节点的数据不一致。举一个实例来说明这个问题,下面是客户端与服务端的结构图:
当client1、client2、client3分别发出消息指令A、B、C时,Server1~4由于网络问题,接收到的消息序列就可能各不相同,这样就可能由于消息序列的不同导致Server1~4上的数据不一致。对于这么一个问题,在分布式环境中很难通过像单机里处理同步问题那么简单,而Paxos算法就是一种处理类似于以上数据不一致问题的方案。
2)算法本身
算法本身我就不进行完整的描述和推导,网上有大量的资料做了这个事情,但我学习以后感觉莱斯利·兰伯特(Leslie Lamport,paxos算法的奠基人,此人现在在微软研究院)的Paxos Made Simple 是学习paxos最好的文档,它并没有像大多数算法文档那样搞一堆公式和数学符号在那里吓唬人,而是用人类语言让你搞清楚Paxos要解决什么问题,是如何解决的。这里也借机抨击一下那些学院派的研究者,要想让别人认可你的成果,首先要学会怎样让大多数人乐于阅读你的成果,而这个描述Paxos算法的文档就是我们学习的榜样。
言归正传,透过Paxos算法的各个步骤和约束,其实它就是一个分布式的选举算法,其目的就是要在一堆消息中通过选举,使得消息的接收者或者执行者能达成一致,按照一致的消息顺序来执行。其实,以最简单的想法来看,为了达到大伙执行相同序列的指令,完全可以通过串行来做,比如在分布式环境前加上一个FIFO队列来接收所有指令,然后所有服务节点按照队列里的顺序来执行。这个方法当然可以解决一致性问题,但它不符合分布式特性,如果这个队列down掉或是不堪重负这么办?而Paxos的高明之处就在于允许各个client互不影响地向服务端发指令,大伙按照选举的方式达成一致,这种方式具有分布式特性,容错性更好。
说到这个选举算法本身,可以联想一下现实社会中的选举,一般说来都是得票者最多者获胜,而Paxos算法是序列号更高者获胜,并且当尝试提交指令者被拒绝时(说明它的指令所占有的序列号不是最高),它会重新以一个更好的序列参与再次选举,通过各个提交者不断参与选举的方式,达到选出大伙公认的一个序列的目的。也正是因为有这个不断参与选举的过程,所以Paxos规定了三种角色(proposer,acceptor,和 learner)和两个阶段(accept和learn),三种角色的具体职责和两个阶段的具体过程就见Paxos Made Simple ,另外一个国内的哥们写了个不错的PPT ,还通过动画描述了paxos运行的过程。不过还是那句话不要一开始就陷入算法的细节中,一定要多想想设计这些游戏规则的初衷是什么。
Paxos算法的最大优点在于它的限制比较少,它允许各个角色在各个阶段的失败和重复执行,这也是分布式环境下常有的事情,只要大伙按照规矩办事即可,算法的本身保障了在错误发生时仍然得到一致的结果。
3)算法的实现
Paxos的实现有很多版本,最有名的就是google chubby ,不过看不了源码。开源的实现可见libpaxos 。另外,ZooKeeper 也基于paxos解决数据一致性问题,也可以看看它是如果实现paxos的。
4)适用场景
弄清楚paxos的来龙去脉后,会发现它的适用场景非常多,Tim有篇blog《Paxos在大型系统中常见的应用场景》 专门谈这个问题。我所见到的项目里,naming service是运用Paxos最广的领域,具体应用可参考ZooKeeper
一致性Hash算法
1)问题描述
分布式常常用Hash算法来分布数据,当数据节点不变化时是非常好的,但当数据节点有增加或减少时,由于需要调整Hash算法里的模,导致所有数据得重新按照新的模分布到各个节点中去。如果数据量庞大,这样的工作常常是很难完成的。一致性Hash算法是基于Hash算法的优化,通过一些映射规则解决以上问题
2)算法本身
对于一致性Hash算法本身我也不做完整的阐述,有篇blog《一致性hash算法 - consistent hashing》 描述这个算法非常到位,我就不重复造轮子了。
实际上,在其他设计和开发领域我们也可以借鉴一致性Hash的思路,当一个映射或规则导致有难以维护的问题时,可以考虑更一步抽象这些映射或规则,通过规则的变化使得最终数据的不变。一致性hash实际就是把以前点映射改为区段映射,使得数据节点变更后其他数据节点变动尽可能小。这个思路在操作系统对于存储问题上体现很多,比如操作系统为了更优化地利用存储空间,区分了段、页等不同纬度,加了很多映射规则,目的就是要通过灵活的规则避免物理变动的代价
3)算法实现
一致性Hash算法本身比较简单,不过可以根据实际情况有很多改进的版本,其目的无非是两点:
- 节点变动后其他节点受影响尽可能小
- 节点变动后数据重新分配尽可能均衡
实现这个算法就技术本身来说没多少难度和工作量,需要做的是建立起你所设计的映射关系,无需借助什么框架或工具,sourceforge上倒是有个项目libconhash ,可以参考一下
以上两个算法在我看来就算从不涉及算法的开发人员也需要了解的,算法其实就是一个策略,而在分布式环境常常需要我们设计一个策略来解决很多无法通过单纯的技术搞定的难题,学习这些算法可以提供我们一些思路。
ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
Zookeeper是Google的Chubby一个开源的实现.是高有效和可靠的协同工作系统.Zookeeper能够用来leader选举,配置信息维护等.在一个分布式的环境中,我们需要一个Master实例或存储一些配置信息,确保文件写入的一致性等.Zookeeper能够保证如下3点:
- Watches are ordered with respect to other events, other watches, and
asynchronous replies. The ZooKeeper client libraries ensures that
everything is dispatched in order. - A client will see a watch event for a znode it is watching before seeing the new data that corresponds to that znode.
- The order of watch events from ZooKeeper corresponds to the order of the updates as seen by the ZooKeeper service.
在Zookeeper中,znode是一个跟Unix文件系统路径相似的节点,可以往这个节点存储或获取数据.如果在创建znode时Flag设置 为EPHEMERAL,那么当这个创建这个znode的节点和Zookeeper失去连接后,这个znode将不再存在在Zookeeper 里.Zookeeper使用Watcher察觉事件信息,当客户端接收到事件信息,比如连接超时,节点数据改变,子节点改变,可以调用相应的行为来处理数 据.Zookeeper的Wiki页面展示了如何使用Zookeeper来处理事件通知,队列,优先队列,锁,共享锁,可撤销的共享锁,两阶段提交.
那么Zookeeper能帮我们作什么事情呢?简单的例子:假设我们我们有个20个搜索引擎的服务器(每个负责总索引中的一部分的搜索任务)和一个 总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕机时替换总服务器),一个web的 cgi(向总服务器发出搜索请求).搜索引擎的服务器中的15个服务器现在提供搜索服务,5个服务器正在生成索引.这20个搜索引擎的服务器经常要让正在 提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以搜索提供服务了.使用Zookeeper可以保证总服务器自动 感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,备用的总服务器宕机时自动启用备用的总服务器,web的cgi能够自动地获知总服务器的网络 地址变化.这些又如何做到呢?
- 提供搜索引擎的服务器都在Zookeeper中创建znode,zk.create("/search/nodes/node1",
"hostname".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateFlags.EPHEMERAL); - 总服务器可以从Zookeeper中获取一个znode的子节点的列表,zk.getChildren("/search/nodes", true);
- 总服务器遍历这些子节点,并获取子节点的数据生成提供搜索引擎的服务器列表.
- 当总服务器接收到子节点改变的事件信息,重新返回第二步.
- 总服务器在Zookeeper中创建节点,zk.create("/search/master", "hostname".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateFlags.EPHEMERAL);
- 备用的总服务器监控Zookeeper中的"/search/master"节点.当这个znode的节点数据改变时,把自己启动变成总服务器,并把自己的网络地址数据放进这个节点.
- web的cgi从Zookeeper中"/search/master"节点获取总服务器的网络地址数据并向其发送搜索请求.
- web的cgi监控Zookeeper中的"/search/master"节点,当这个znode的节点数据改变时,从这个节点获取总服务器的网络地址数据,并改变当前的总服务器的网络地址.
















 2430
2430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









