







文章目录
摘要
本周主要在学习师姐给的深度学习网络模型的代码、桂林市污染气象报告和空气质量预测的一些论文。在代码上,看懂了模型参数配置、数据提取与处理、模型的训练与预测、绘图(训练过程可视化),但是日志文件是怎么记录的、搭建的模型具体是长啥样的还未掌握。在理论上,知道了空气质量预测一般都是用高斯模型、LSTM、GRU、克里金插值的方法。高斯模型通常以点源污染扩散搭建模型,较难考虑风、空间环境等影响因素,局限性较大。更深刻的理解了LSTM和GRU。也知道了桂林空气污染有哪些重要影响因素、空气污染具有持续性,这也就说明了空气质量是可以根据现有数据进行预测的。
一、对PM2.5预测的论文的总结
1.1 背景
近几十年来,我国经济飞速发展,以环境被破坏的"空间"换来了经济发展的“时间”,北京等多地频繁出现雾霾天气,大气污染越来越严重,城市空气质量预报越来越重要,研究这方面的人也在增多,主要是以预测PM2.5的含量来代表空气质量。
1.2 PM2.5
PM2.5是指大气中直径小于等于2.5μm的颗粒物,它的比表面积大,易携带细菌和病毒。PM2.5主要来源是机动车燃油和工厂的废气排放,温度湿度压强等也会影响其形成。
1.3 综述
傅云凤等提出了用点源污染扩散建立高斯模型来预测未来PM2.5的含量,其模型没有考虑地形环境等因素。韦澜等则引入了土地类型因素,模型更加准确了,但毕竟存在风向,风速等因素,以点源污染扩散的高斯模型还是具有其局限性。周永生等用的是LSTM的seq2seq,是用空气中其他气体的平均含量对整个城市的平均PM2.5的含量进行预测。Xi Gao等将所有检测站点连接构成图,用邻接矩阵代表各个站点间的空间关系,然后用GLSTM对PM2.5进行预测。
总的来说高斯模型可以预测整个城市的PM2.5的分布,预测范围广,但准确度较低。LSTM模型预测时因为其具有记忆功能,所以可以很好的将数据间的时空关系联系起来,但现有的大部分用LSTM模型做预测的研究其考虑的影响因素较单一。我们需要一个可以综合地形、空间与空气的各项指标的预测模型,只有这样才能大幅度的提高模型的预测准确度及预测时间。
1.4 对桂林空气质量文章的总结
1.4.1 空气质量变化
2008年到2013年NO2 ,SO2 的浓度年均值平稳,但PM10 的年平均浓度增长较快。三级污染天数从2010年的6天增长到了2013年的31天,且无论哪个季节三级污染可持续2~3天,一、四季节的污染物浓度要高于二、三季度,可见空气污染与季节有关且有持续性,具有可持续性也就说明了我们可以用今天的空气质量指标预测未来的空气质量。初步分析影响桂林市空气质量状况的原因有一下几点:
- 工业发展迅速,污染物排放量增多。
- 机动车保有量猛增,尾气排放量逐年上升。
- 桂林市区西北灵川县定江镇附近的砖厂较多,砖厂排放的废气污染影响了处于下风向的市区环境。
用来衡量空气质量的指标是API:
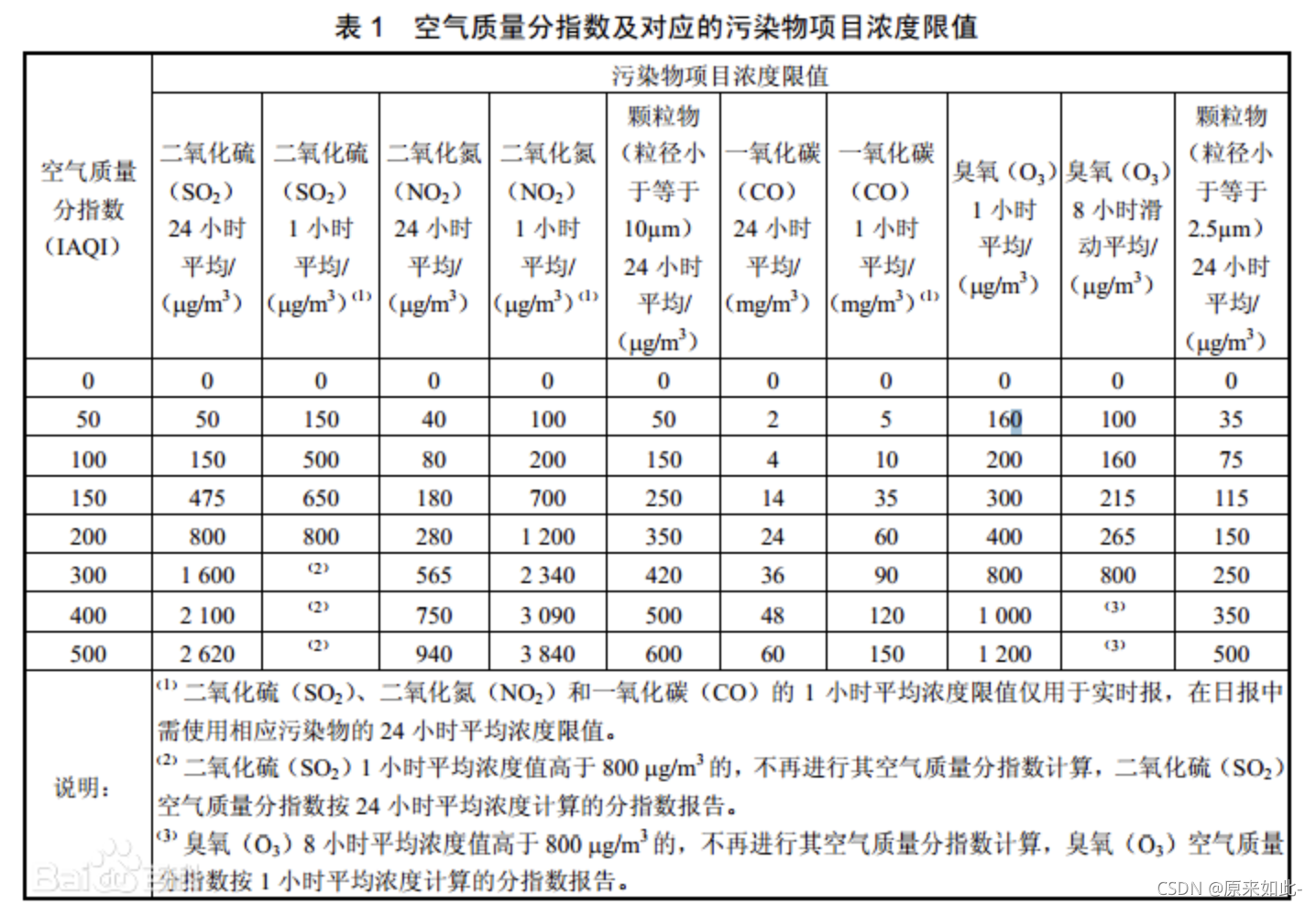
1.4.2 污染物扩散的影响因素
- 风的影响
风速大于3级(5.5m/s),将不会出现霾天气。霾只是出现在轻风和微风的天气里。桂林市全年风向以东北偏北风为主,平均风速为2.2~2.7米/秒,地面风速略减少(历年平均2.5m/s),即桂林平均风速以轻风和微风为主,不利于污染物的扩散,出现霾的概率增加。 - 降水的影响
桂林夏季雨量丰沛,年平均降雨量约2000毫米,在有效降雨时间段内,降水造成空气湿度增加,按规定不能记录为霾;二是雨滴对空气中的颗粒污染物质起冲刷作用,将污染物带到地面,空气质量良好。
然而,如若连续无降水容易造成霾的生成和发展,桂林秋冬季节降水偏少,连续无降水日数多,所以霾的出现也多。统计发现,连续一周无雨,桂林相对容易形成轻霾天气。 - 湿度的影响
湿度为60%-80%容易出现霾,桂林市年平均相对湿度为73%~79%,空气垂直对流变缓,大气稳定度相对较好,不易形成湍流,污染物难扩散,相对容易出现霾。 - 温度的影响
干热天气,强烈的辐射和高温使得光化学反应强烈,地面温度偏高,地表蒸发量加大,地面湿度降低,地表尘土飞扬,造成污染物浓度增加,从而引起霾出现的概率增高。
秋季桂林地区常受副热带高压控制,高温晴热且风小,污染物不易扩散,形成霾。 - 逆温层的影响
据桂林市气象局统计,桂林一年四季都有不同程度的逆温层,完全没有逆温的现象每年也只有不足20天,约占5%左右,有逆温的日数占到了95%左右。有的逆温层出现高度高,有的出现高度低,有时逆温层厚度厚(可以达到2000m),有的仅有几十米,真正对大气垂直运动有重要影响的是发生在低层、厚度较厚的逆温层。
一般情况下,桂林夏秋季节逆温层出现的高度较高,厚度也较薄,冬季的逆温层出现高度相对较低,逆温层的厚度也较厚,最厚的有200hPa。正是由于冬季厚而低的逆温层阻碍,污染物扩散缓慢,使得桂林的冬季更容易出现污染。据统计,桂林冬季逆温1/3的天数可以造成霾;1-2月份出现了霾的日期,基本上在850hPa高度层以下都有逆温层伴随。 - 桂林市基本地貌条件下污染物扩散特点
地处南岭山系的西南部的桂林四周山地环绕,山地丘陵面积广大,地形总体上呈北高南低的趋势,即北、东、西三面环山,地势较高;中部及南部、东北部为岩溶山地与平原、河谷地区,地势较低平,这一地貌特征容易形成山谷环流,在一定程度上影响了空气污染物的稀释、扩散和清除。
此外,随着城市化建设,建筑物不断增多,减低风速,减缓污染物扩散,不仅不利于城市内的污染物扩散,外来污染源进入桂林后,也不易扩散,双重污染集聚,出现大气污染的概率也随之增加。
在气象因子中,风速是影响PM10/2.5值最高的因子,成负相关关系。降雨的累积雨量对第二天的PM10/2.5值有较大的影响,湿度与PM10/2.5值有较显著的统计学规律,温度无明显的统计规律。
二、LSTM与GRU原理详述
2.1 LSTM
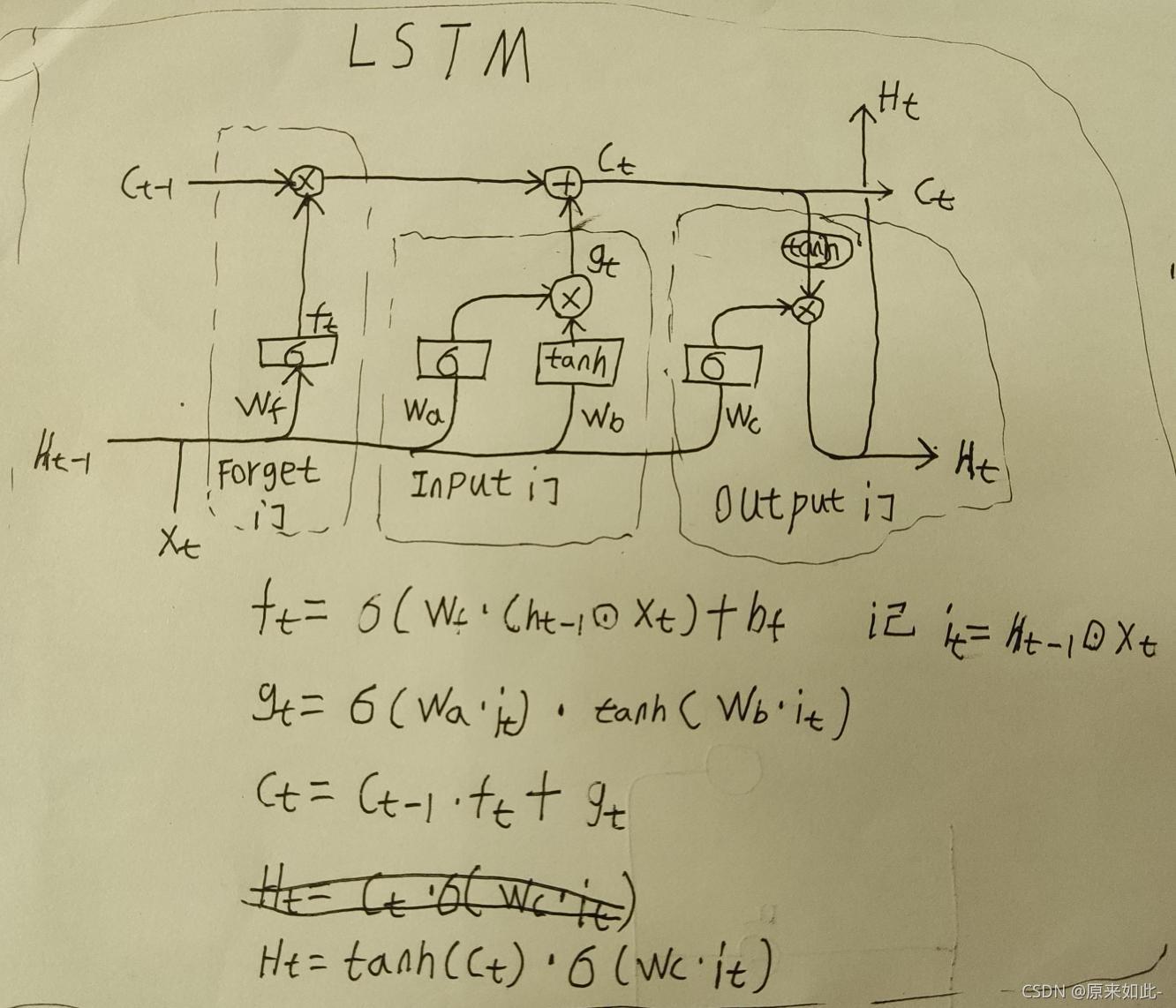
LSTM是由多个门结构组成的网络,它具有遗忘门,输入门,输出门。其中:
- Ht-1是前一时刻的输出也叫隐藏状态。
- Xt是当前 t 时刻网络的输入。
- Ct-1是记忆单元,用来存储看过的信息。
- Ht是当前 t 时刻网络的输出也叫隐藏状态。
- Ct是当前 t 时刻网络看过Xt后的记忆单元。
LSTM看过前一时刻的输出和当前时刻的输入后,遗忘门会决定是否遗忘以前看过的数据,遗忘比例是多少,输入门会决定是否输入数据,输入比例是多少,输出门则会判断是否输出数据,输出比例是多少。这些门的该如何做正确的决定都是从训练中得到的。
2.2 GRU
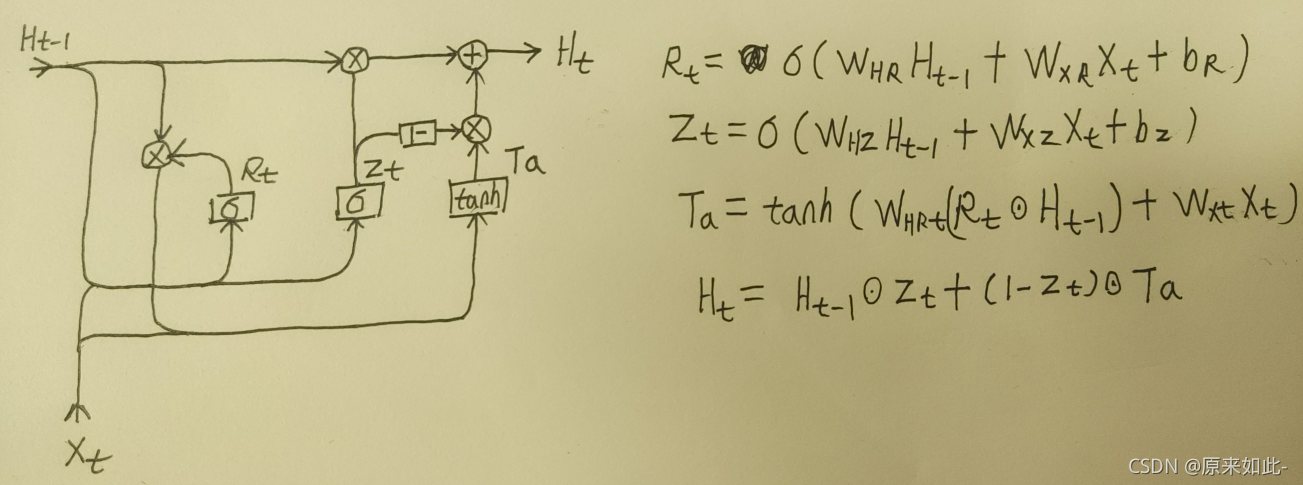
当数据集很大时,LSTM的效果会好一些,大部分情况下,GRU和LSTM的效果差不多,且GRU少一个门结果,只有重置门和更新门,所以GRU的训练时间更短。其中:
- Ht-1是前一时刻的输出也叫隐藏状态。
- Xt是当前t时刻网络的输入。
- Ht是当前t时刻网络的输出也叫隐藏状态。
三、对师姐的深度学习网络基础模型程序的总结
3.1 程序的总结
目前程序是basic的,是根据一个点的SO2、NO2、PM10等的历史数据训练一个GRU或者LSTM的模型去预测未来两天PM2.5的含量,模型训练有三种环境可供选择(tensorflow、pytorch、keras)。主程序包括,配置,数据读取,日志记录,绘图,模型训练和预测。数据读取时,因数据量大,所以为了缩短调试时间,设置了调试模式,调试模式下只读取少量数据进行训练,从data中取一部分数据,将其归一化去量纲,一部分作为训练数据,一部分作为测试数据。训练时,有两种模式可选:
- 非连续训练模式。例如每20行数据作为一个样本,1-20行,2-21行…,对应的label则是3-22行,4-23行…。
- 连续训练模式。例如1-20行,21-40行…,对应的label就为3-22行,23-42行。
读取后将数据丢给GRU或LSTM的模型进行训练,画出Loss函数变化曲线,输出各个配置参数及预测的PM2.5的值。
3.2 其中部分语句的实践操作(Class的使用)
格式 Class 类名:类中的语句(可在类中定义函数变量,类等,它们的生命周期在类中)
3.2.1 类的初始化(init)
class Config:
a = 1
class Data:
def __init__(self,config): #config负责解释Data(Config)中Config的数据,self是类
self.config = config
self.z = 112
def f(self):
self.config.z = 100
return self.config.z
Data(Config).f()
运行结果:
3.2.2 类的交叉使用
class Config:
a = 1
class Data:
def __init__(self, config):
self.config = config
self.z = 112
self.a = 110
def f(self):
num = self.z
self.config.a = 110
self.config.z = 999
return self.config.a
def main(config):
data = Data(config)
print(data.f())
con = Config # con = Config会将类Config的地址给con, con = Config()则只是简单的赋值
main(con)
print(Config.z) #判断是否改变了Config.z中的值
运行结果:

3.2.3 类的嵌套
下图是类的嵌套,我们在第二层的类中改变了第一次类的值,但是改变的值并没有从输出结果中体现出来,所以类的运行顺序是从上到下的,运行一次后类中变量的生命终结。
class Config:
a = 1
b = 2
class inCon:
Config.a = 11
s = 8
print(Config.inCon.s, Config.a)
print(Config.inCon.s, Config.a)
运行结果:

总结与展望
PM2.5的含量可以代表空气质量,预测PM2.5的难点主要是如何将地理环境因素、空间因素、气象因素、空气中其他相关因素结合起来有效的告诉model。
我认为在提取地理环境信息上,可以将地理环境分为森林、城市、平原等类别,用监测站点5KM(可变)内地理环境的面积占比构成一个向量,该向量就包含了该站点的地理环境信息,例如一个检测站点5KM内森林、城市、平原面积占比为6:2:2,那么包含其地理环境因素信息的向量就是[6,2,2]。在提取空间信息时可以以城市为原点,构建空间直角坐标系,检测站点空间信息就可用坐标表示。风向及强度因素和提取空间信息时的操作一样。将最后得到的所有向量组合起来,对model进行训练,此时的model就是综合了各个影响因素对PM2.5进行预测。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









