







一、下载Mahout
参考自:
http://archive.apache.org/dist/mahout/
二、解压
tar -zxvf mahout-distribution-0.9.tar.gz
三、配置Mahout环境变量
# set mahout environment
export MAHOUT_HOME=/usr/local/mahout-distribution-0.9
export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf
export PATH=$MAHOUT_HOME/conf:$MAHOUT_HOME/bin:$PATH
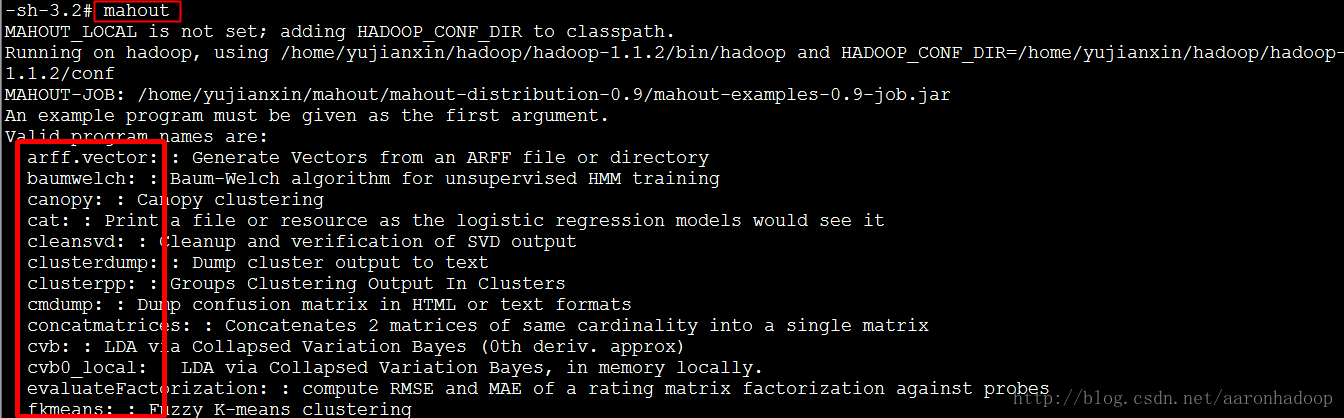
四、验证Mahout是否安装成功
执行命令mahout。若列出一些算法,则成功,如图:
五、使用Mahout 之入门级使用
5.1、启动Hadoop,并创建相应的目录
5.2、下载测试数据
http://archive.ics.uci.edu/ml/databases/synthetic_control/链接中的synthetic_control.data
5.3、上传测试数据
hadoop fs -put synthetic_control.data /user/root/testdata
5.4 使用Mahout中的Canopy聚类算法,执行命令:
hadoop jar $MAHOUT_HOME/mahout-examples-0.7-job.jar org.apache.mahout.clustering.syntheticcontrol.canopy.Job
花费几分钟完成聚类 。
5.5 查看聚类结果
执行命令:
mahout clusterdump -i output/clusters-0-final -p output/clusteredPoints -o /home/sun/t.txt
把聚类产生的序列文件转换为文本文件,打开文本文件之后可看到聚类的结果。
齐活,收工。Mahout继续学习中......















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









