






为JPA和Hibernate构建巩固基础
作者:Stephen B.Morris
你是否被你的Java持久化代码所困惑?或者正尝试着掌握JPA和Hibernate?正如富有经验的Stephen B.Morris用完全实用的例子和核心技术来举例一样,这些问题都能轻松掌握。
聚合中的软件
关注企业软件开发中的最新趋势,我看到很多新兴的模式。现在很多组织热衷于雇佣低廉劳动力这一措施。与此同时,企业的发展也变得越来越复杂。这两个驱动力完全背道而驰。
并不是发展的复杂性与日俱增,而是另一个因素在起作用—可以称之为聚合软件。总之,开发技术的分层化正在融合。对于这种趋势我们来举个例子,你只需看看JPA,Hibernate和EJB3就可以了。这里的每一种技术都代表了我们前述分离原则的影响:
l Java Persistence API(JPA)使用富注释环境来连接Java和持久化代码。
l 本地化Hibernate提供和JPA很多相似的功能,而这些功能可以方便的与数据库进行交互。
l Enterprise JavaBeans 3.0(EJB3)为bean模型化, 持久化支持, web service等提供了一种难以置信的简化但强有力的整合模型。
以我的观点,这些趋势因有助于平均开发人员的能力水平而广受欢迎。如果开发人员X以前专注于象开发web services这一领域,对X来说掌握持久化开发就是一件很容易的事了。
象技术多样化肯定不是长久之计—对于开发人员来说,我们总是在试图提升价值链。好消息就是新兴的技术最终会提供一个自主学习的平台。让我们来看看JPA和Hibernate怎样把它变成现实,让我们来看看用这些有趣的技术怎样创建一个项目。
JPA准备列表
你只需准备以下一些条目并和JPA一起运行:
l 一个或多于一个的实体类
l EntityManager (实体管理者)实例
l EntityTransaction (实体事物)实例
l 用XML编写的持久化单元
l 数据库引擎
一旦准备好上面的这些条目,你就可以实施你的持久化解决方案了。这是不是听起来有些困难?并不是这样的,让我们以实体类开始。
实体是什么?
理解实体的最好方式就是把它看做你的问题领域的被描述作为一个名词的那个东西;举个例子来说,客户、使用者、系统、网络等等都是实体。实体是代表你的问题领域的底层原子。你把这些原子模型化实体。列表1展示了一个完整的实体类叫做Message.java;此时,先忽略以’@’开头的代码行;这些叫做注释,随后我将会讨论的。
列表1 一个实体类
import javax.persistence.*;
@Entity
@Table(name = "MESSAGES")
public class Message {
@Id @GeneratedValue
@Column(name = "MESSAGE_ID")
private Long id;
@Column(name = "MESSAGE_TEXT")
private String text;
@ManyToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "NEXT_MESSAGE_ID")
private Message nextMessage;
Message() {}
public Message(String text) {
this.text = text;
}
public Long getId() {
return id;
}
private void setId(Long id) {
this.id = id;
}
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public Message getNextMessage() {
return nextMessage;
}
public void setNextMessage(Message nextMessage) {
this.nextMessage = nextMessage;
}
}
暂时将注释放在一边,列表1只是一个普通的Java类。事实上,这种语句过去用于描述一个”Plain Old Java”类,或者缩写POJO。列表1中的POJO包含3个数据成员,正如列表2展示的。
列表2 列表1中的POJO域
private Long id;
private String text;
private Message nextMessage;
观察列表1的其余部分,为列表2中的域定义的两个构造器和getter和setter方法组成了列表1中的代码。现在让我们看看这些注释。
走近注释
在大部分中,注释是相当明显的,并且一个聪明的猜测可以轻松的知道代码的目的性。在列表1中注释以这种方式开始:
@Entity
@Table(name = "MESSAGES")
public class Message
@Entity标识这个类是持久的。这对实体管理者是一个暗示就是这个类的实例将会写入到数据库。换句话说,类的每一个实例将会成为关系型数据库表中的一行记录。但是哪个表可以用来存数Message类的实例呢?为了回答这个问题,我们看看第二个注释:
@Table(name = "MESSAGES")
正如我所说,很有可能你已猜到注释的功能。这是因为注释被认为是相对的自我描述。在这个例子中,你可能正确的猜出Message类的实例将会存储在一个叫做MESSAGES的表中。迄今为止—还没有什么太难的。现在对类的代码又提到了些什么呢?下一个注释在Message类里并且象这样:
@Id @GeneratedValue
@Column(name = "MESSAGE_ID")
private Long id;
为了理解这些注释我们必须绕个弯路再进入数据库领域并且考虑数据表中键的一些问题。
使用数据库首要要求之一就是表中记录行的唯一性。这个要求并不难于理解:如果你在酒店预定了一个房间,你会要求你的预定在数据库中是唯一的。这意味着你(只有你)在给定的房间上预定。唯一性可以通过使用键值来设定。键值可以是整型,并且约定所给出的任何键在表中的其他行上都不能重复。
回到酒店预定房间的例子,键值是一个整型值,并且上面的注释就是典型例子。我们的注释使用了一个private Long成员来建模键值。观察完整的注释,你现在可能已经猜出全部的功能:
@Id @GeneratedValue
@Column(name = "MESSAGE_ID")
private Long id;
注释@Id表示注释后面的域是一个标识符或是键值。这些值在表中的行上唯一区分,但涉及到哪列?注释@Column表示键值列叫做MESSAGE_ID。
让我们回顾一下。我们数据库的表叫做MESSAGES并且有一个叫做MESSAGE_ID的键值列。为了完成这个画面,我们来看看使用下面的注释怎样来完成映射表中的非键值列。
@Column(name = "MESSAGE_TEXT")
private String text;
而且,如果你对注释使用一个逻辑方法,你可以猜出接下来怎么做。在这个例子里,我们创建一个列叫MESSAGE_TEXT。这个列也被添加到数据表MESSAGES上。
用注释来写POJO的过程通常称为映射。事实上,在我的顾问工作中我曾用这个词语来描述对客户的过程。大多数主管可以理解你的Java代码,并且对SQL代码也了解。JPA工作原理与一个非技术人员来说理解是非常困难的,但象映射这个普通词语对他们理解还是很有帮助的。事实上,你在两个域中做了映射:Java和关系型数据库。当我们运行代码的时候你会看到映射是怎样工作的,但是此刻要注意我们只是在两个不同的技术上做了连接—旧的技术和新的技术!
回到POJO,下一个注释稍微复杂些。
@ManyToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "NEXT_MESSAGE_ID")
private Message nextMessage;
从这段代码的尾部开始,Message类的每个实例都包含Message的一个实例。记住,数据库为每个Message实例创建一行记录。上面的注释表示表中记录行之间的关系;在这个例子中,是多对一的关系。换句话说,一个实体和很多实体有关系。这些实体是怎样联系起来的呢?关系是通过表中一个数据列建模的,更确切地说是和注释@JoinColumn相映射的。后面指定了列名来构成关联的基础。
对现有实体来说,级联涉及方式改变是通过关系继承产生。
实体类的其他一些细节
实体类的其余部分总结如下:
l 缺省构造器
l 非缺省构造器
l 数据成员的set方法
l 数据成员的get方法
缺省构造器是持久化类必须拥有的。非缺省构造器用来预产生实体类的实例。get和set方法仅仅用来获取或修改成员函数。现在,我们怎样才能实例化一个实体类?很简单—我们使用另一个类。
主程序
我们需要建立一个环境,实体类的实例可以在其中创建。列表3展示了一个建立环境和实例化、持久化我们实体的完整类。
列表3 客户端程序
import java.util.*;
import javax.persistence.*;
public class HelloWorld {
public static void main(String[] args) {
// Start EntityManagerFactory
EntityManagerFactory emf =
Persistence.createEntityManagerFactory("helloworld");
// First unit of work
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
Message message = new Message("Hello World with JPA");
em.persist(message);
tx.commit();
em.close();
// Second unit of work
EntityManager newEm = emf.createEntityManager();
EntityTransaction newTx = newEm.getTransaction();
newTx.begin();
List messages =
newEm.createQuery("select m from Message m order by m.text asc").getResultList();
System.out.println( messages.size() + " message(s) found:" );
for (Object m : messages) {
Message loadedMsg = (Message) m;
System.out.println(loadedMsg.getText());
}
newTx.commit();
newEm.close();
// Shutting down the application
emf.close();
}
}
列表3被分为“作用单元”—事物包括创建实体实例和数据库持久化。一旦持久化,将会获取实例并显示在控制台上。
安装
“Hello World”代码中唯一的安装就是解压zip文件到一个文件夹中。象通常的Java代码一样,可以将目标文件夹路径短些并避免任何空格。在我的系统中,我解压zip文件到一个叫做C:/java的文件夹,这个文件夹构成了后面的目录结构:
C:/java/jpwh-gettingstarted-070401/helloworld-jpa
为了执行代码,你可以打开DOS控制台并且改成上面的路径。
运行代码
最简单执行的方法就是在目录里打开3个DOS控制台,在这个目录里还包含Ant构建文件(build.xml)。查看Ant构建目标,输入下面命令:
Ant –p
你可以看到如列表4的内容
列表4 查看Ant目标
C:/java/jpwh-gettingstarted-070401/helloworld-jpa>ant -p
Buildfile: build.xml
主要目标:
clean 清空构建路径
dbmanager 打开HSQL数据库管理器
run 构建和运行HelloWorld
schemaexport 输出一个方案到数据库和文件
startdb 用干净数据运行HSQL 数据库服务器
缺省目标:compile
下面的3部分描述了怎样去做:
1. 启动数据库管理器
2. 输出Schema到数据库
3. 执行客户端程序
执行这些任务最简单的方式就是从分开的DOS控制台执行合适的命令。换句话说,在下面的路径下打开每个DOS控制台:
C:/java/jpwh-gettingstarted-070401/helloworld-jpa
然后执行合适的Ant目标作为下面部分的描述。
启动数据库管理器
你可能很高兴的听到要执行代码,而且不需要花很长时间就能建立一个数据库管理器。例子程序试用了一个常驻内存的数据库叫做HSQLDB。当然,你可以更改配置信息并使用任何你想用的数据库,但是这个例子缺省使用HSQLDB。为了启动数据库管理器,键入列表5的如下命令
列表5 运行数据库引擎
C:/java/jpwh-gettingstarted-070401/helloworld-jpa>ant startdb
Buildfile: build.xml
startdb:
[delete] Deleting directory C:/java/jpwh-gettingstarted-070401/helloworld-jpa/database
[java] [Server@1d58aae]: [Thread[main,5,main]]: checkRunning(false) entered
[java] [Server@1d58aae]: [Thread[main,5,main]]: checkRunning(false) exited
[java] [Server@1d58aae]: Startup sequence initiated from main() method
[java][Server@1d58aae]:Loadedpropertiesfrom [C:/java/jpwh-gettingstarted-070401/helloworld-jpa/server.properties]
[java] [Server@1d58aae]: Initiating startup sequence...
[java] [Server@1d58aae]: Server socket opened successfully in 15 ms.
[java] [Server@1d58aae]: Database [index=0, id=0, db=file:database/db, alias=] opened sucessfully in 375 ms.
[java] [Server@1d58aae]: Startup sequence completed in 390 ms.
[java] [Server@1d58aae]: 2008-12-04 11:17:19.187 HSQLDB server 1.8.0 is online
[java] [Server@1d58aae]: To close normally, connect and execute SHUTDOWN SQL
[java] [Server@1d58aae]: From command line, use [Ctrl]+[C] to abort abruptly
当你看到如列表5显示的结果,你应该做好将Schema输出到数据库的准备。
将方案输出到数据库
为了常驻数据库,你一定要创建一个Schema文件,这个文件大小不能比一段创建和配置你的数据表的SQL代码多。这个Schema可以被创建并且一次输出全部到列表6的命令行。
列表6 输出Schema
C:/java/jpwh-gettingstarted-070401/helloworld-jpa>ant schemaexport
Buildfile: build.xml
compile:
copymetafiles:
schemaexport:
[hibernatetool] Executing Hibernate Tool with a JPA Configuration
[hibernatetool] 1. task: hbm2ddl (Generates database schema)
[hibernatetool]
[hibernatetool] alter table MESSAGES
[hibernatetool] drop constraint FK131AF14C3CD7F3EA;
[hibernatetool]
[hibernatetool] drop table MESSAGES if exists;
[hibernatetool]
[hibernatetool] create table MESSAGES (
[hibernatetool] MESSAGE_ID bigint generated by default as identity (start with 1),
[hibernatetool] MESSAGE_TEXT varchar(255),
[hibernatetool] NEXT_MESSAGE_ID bigint,
[hibernatetool] primary key (MESSAGE_ID)
[hibernatetool] );
[hibernatetool]
[hibernatetool] alter table MESSAGES
[hibernatetool] add constraint FK131AF14C3CD7F3EA
[hibernatetool] foreign key (NEXT_MESSAGE_ID)
[hibernatetool] references MESSAGES;
[hibernatetool] 1 errors occurred while performing <hbm2ddl>.
[hibernatetool] Error #1: java.sql.SQLException: Table not found: MESSAGES in statement [alter table MESSAGES]
成功创建
列表6所产生的就是创建Schema文件并将这个文件输出到数据库引擎。如果你想查看Schema文件,查看根目录下一个叫做helloworld-jpa-ddl.sql的文件。这个文件的内容在列表7中展示出来。
列表7 自动生成的Schema
alter table MESSAGES
drop constraint FK131AF14C3CD7F3EA;
drop table MESSAGES if exists;
create table MESSAGES (
MESSAGE_ID bigint generated by default as identity (start with 1),
MESSAGE_TEXT varchar(255),
NEXT_MESSAGE_ID bigint,
primary key (MESSAGE_ID)
);
alter table MESSAGES
add constraint FK131AF14C3CD7F3EA
foreign key (NEXT_MESSAGE_ID)
references MESSAGES;
列表7展示了JPA的一些奇妙之处。SQL代码基于Java注释代码自动生成。你可以知道JPA怎样显式连接Java和关系型数据库。
警告
输出Schema到一个动态数据库断然不是一个好的想法!这只是为了配置环境构造的例子。在这里使用只是为了举例JPA解决方案的力度。我应该补充的就是随着力度独立构成,在使用这个知识的时候要头脑清醒。你想要做的最后一件事就是破环一个生产数据库。
列表6尾部的错误信息仅仅反映MESSAGES表并不存在优先运行脚本的事实。所以,如果一切顺利的话,你现在已拥有一个新建的数据库(虽然没有使用)。让我们看看这个数据库。
启动数据库管理器
HSQLDB包含一个非常有用的GUI驱动数据库管理器。你可以用列表8的命令运行管理器。
列表8 运行数据库管理器
C:/java/jpwh-gettingstarted-070401/helloworld-jpa>ant dbmanager
Buildfile: build.xml
dbmanager:
[java] Failed to load preferences. Proceeding with defaults:
[java]
不用担心列表8的诊断信息—它关联到一个丢失的配置文件。重要一点就是你可以看到如图表1的一个新的窗体。
图表1 HSQL数据库管理器GUI
我在图表1中执行了一个SQL查询以证明数据库里无数据。用GUI执行SQL是非常简单的事—只是select命令>Select。这读取文本SELECT * FROM并且你仅仅需要增加表名—在这个例子里,表MESSAGES。一旦键入命令,点击执行SQL按钮。此时,你需注意图表1右下部分所显示的。问题就是这里也没有数据。让我们修正这个情况。
导入数据库
为了导入数据库,我们需要执行主程序,如列表9所显示。
列表9 执行数据库—导入数据
C:/java/jpwh-gettingstarted-070401/helloworld-jpa>ant run
Buildfile: build.xml
compile:
copymetafiles:
run:
[java] 1 message(s) found:
[java] Hello World with JPA
成功创建
如果你用列表3中的Java代码完成列表9中的程序输出,你将看到下面的Java代码通过执行非缺省的构造器来实例化Message:
Message message = new Message("Hello World with JPA");
em.persist(message);
对象信息此时写入(持久化)到数据库。
数据库执行代码后会出现什么结果?图表2显示了数据库内容。
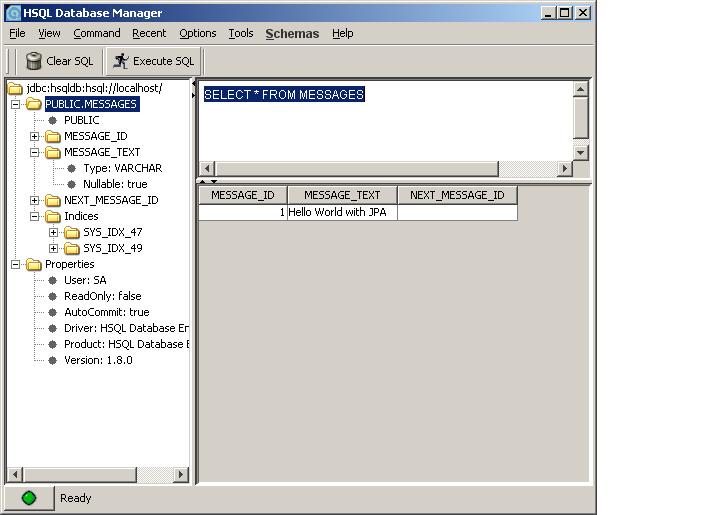
图表2 导入的数据库
注意图表2中的数据行被Message的实例所导入。JPA多么神奇!也要注意NEXT_MESSAGE_ID数据列是空白的,因为还没有执行导入此列的代码。然而,通过调用一个setNextMessage()方法很容易导入。
随着探索JPA和持久化,你已经知道了一个完整的框架。
总结
了解和执行JPA并不是很复杂;你完全可以一步一步按上面来做。甚至注释 (至少大部分) 都是易于理解的。然而,大部分的组织相信Java注释的思想还是很有价值的。然而,很多组织更热衷于可扩展的XML文件这种靠得住的方式。
Java注释在学习语言边缘非常有用。我个人感觉注释非常强大,但与代码非常接近。事实上,注释是代码的一部分。而共性正渐渐倾向注释,随着分离的解决方案注释这可能稍微有些不一致。我不怀疑注释通过产业广泛采用。实际上,我也曾做过用注释做出一些让人印象系统项目。我使用注释过程中遇到的一个问题就是注释可能导致难以解决的问题;举例来说,事物泛滥
在这个文章中,你已经知道如何建立一个实体类和怎样实例化和创建一个实体实例。建立有必要的数据库结构也并不是很难—至少在了解HSQLDB的领域。
我希望我做到使Java的持久化领域不再神秘并且对探索这个领域更深层次的问题起到抛砖引玉的作用。















 1611
1611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









