









简介:Spark包含一个提供常见的机器学习(ML)功能的程序库,叫做MLlib。它提供了很多种机器学习算法,包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。MLlib还提供了一些更底层的机器学习原语,包括一个通用的梯度下降优化算法。所有这些方法都被设计为可以在集群上轻松伸缩的架构。
MLlib的设计理念:把数据以RDD的形式表示,然后在分布式数据集上调用各种算法。Mllib引入了一些数据类型(比如点和向量),不过归根结底,Mllib就是RDD上一系列可供调用的函数的集合。
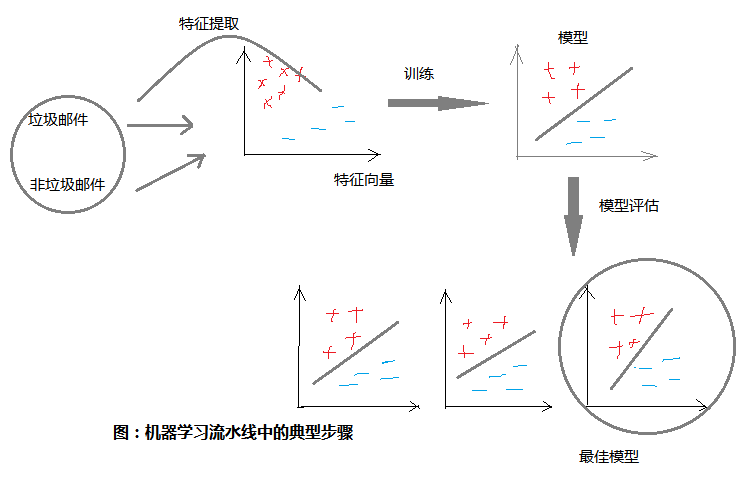
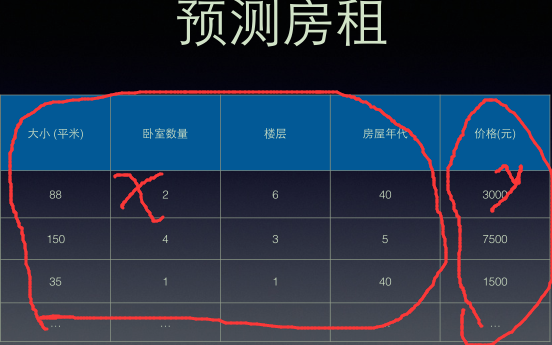
比如需要用MLlib来完成文本分类的任务(识别垃圾邮件):
(1)首先用字符串RDD来表示你的消息。
(2)运行MLlib中的一个特征提取(feature extraction算法来把文本数据转换为数值特征(适合机器学习算法处理);该操作会返回一个向量RDD。
(3)对向量RDD调用分类算法(比如逻辑回归);这步会返回一个模型对象,可以使用该对象对新的数据点进行分类。
(4)使用MLlib的评估函数在测试数据集上评估模型。
【LinearRegression】
线性回归是利用称为线性回归方程的函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。
只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。
基本过程
做回归算法的一般步骤
——构造预测函数(h函数)
——构造cost函数
——利用梯度下降(上升)法来计算
——梯度下降(上升)计算的向量化(思考:为什么要向量化?)(如果不向量化计算过程中有大量嵌套for循环,非常庞大的运算。如果向量化以后,就是对向量矩阵的运行,可以简化运算。)
简单理论知识
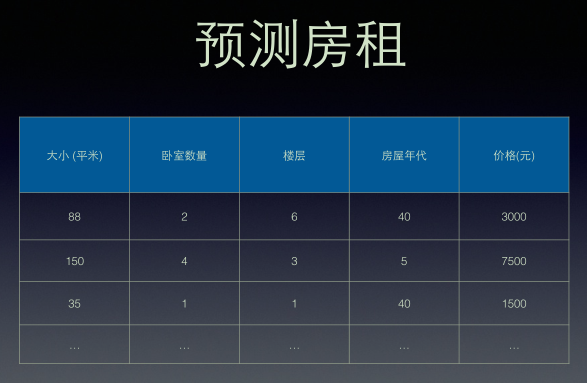
——n代表特征数量
——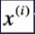
——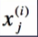

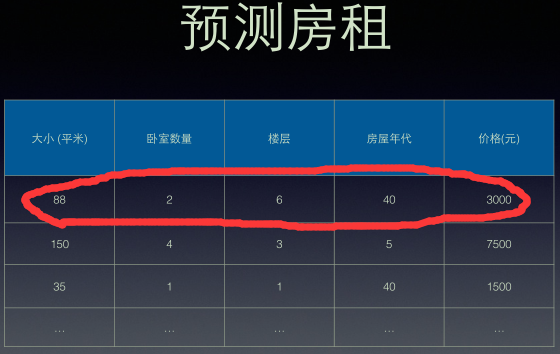
——第i个样本输入一般可以表示为
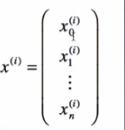
输入输出分别是x与y:
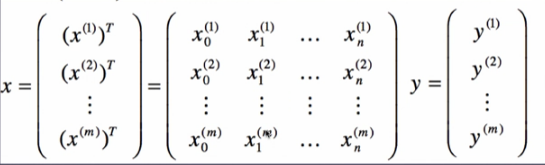
h函数(最终向量化表示):

cost函数:
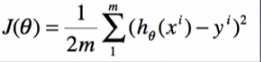
梯度下降:
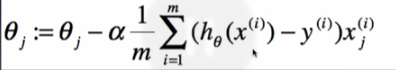
Mean Square Error(均方误差):
真实值Vi减去预测值Pi,越小越好!
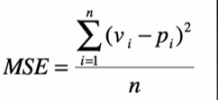
【K-Means聚类】
K-Means将n个观察实例分类到K个聚类中,以使得每个观察实例距离它所在的聚类的中心点比其他的聚类中心点的距离更小。所以它是一种基于距离的迭代式算法。
黄色点为质心,当算出的新质心和原来的质心无限接近时,认为这个聚类已近稳定。
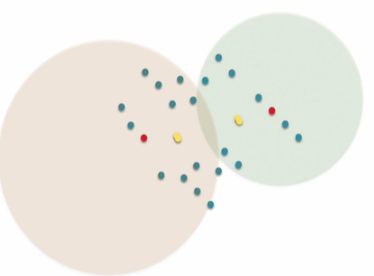
算法:(计算距离–欧拉距离、海绵距离)
1.在所有点(向量)中随机抽取出K个点(向量),作为初始聚类中心点,然后遍历其余的点(向量),找到距离各自最近的聚类中心点,将其加入到该聚类中。
2.求出每个聚类的中心点作为新的聚类中心,然后再遍历所有的观测点,找到距离最近的中心点,加入到该聚类中。重复运行此步骤。
3.当新产生的中心点与前一个中心点一致或者变化不大时,认为迭代结束。
迭代结束条件:(二范式可以简单想象成绝度值)
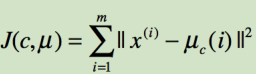
【协同过滤算法】
——最重要的推荐算法
——User-Based
——Item-Based(hadoop中的mahout)
—-个性化(User-Based)
—-非个性化(Item-Based)
一般使用皮尔逊相似度:
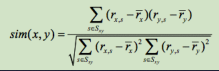
余弦相似度:
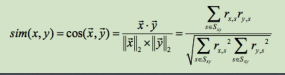
直观感受:
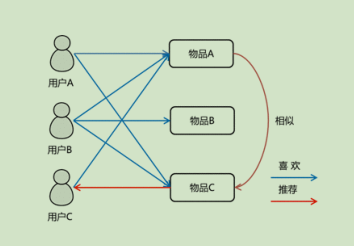
真正智能的推荐,你买个手机推荐手机膜!















 1030
1030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











