










基于如下链接转载整理:
https://www.cnblogs.com/crazymakercircle/p/14731826.html
分布式锁实现原理
在单体的应用开发场景中,在多线程的环境下,涉及并发同步的时候,为了保证一个代码块在同一时间只能由一个线程访问,我们一般可以使用synchronized语法和ReetrantLock去保证,这实际上是本地锁的方式。
也就是说,在同一个JVM内部,大家往往采用synchronized或者Lock的方式来解决多线程间的安全问题。但在分布式集群工作的开发场景中,在JVM之间,那么就需要一种更加高级的锁机制,来处理种跨JVM进程之间的线程安全问题.
解决方案是:使用分布式锁
总之,对于分布式场景,我们可以使用分布式锁,它是控制分布式系统之间互斥访问共享资源的一种方式。
比如说在一个分布式系统中,多台机器上部署了多个服务,当客户端一个用户发起一个数据插入请求时,如果没有分布式锁机制保证,那么那多台机器上的多个服务可能进行并发插入操作,导致数据重复插入,对于某些不允许有多余数据的业务来说,这就会造成问题。而分布式锁机制就是为了解决类似这类问题,保证多个服务之间互斥的访问共享资源,如果一个服务抢占了分布式锁,其他服务没获取到锁,就不进行后续操作。
大致意思如下图所示(不一定准确):
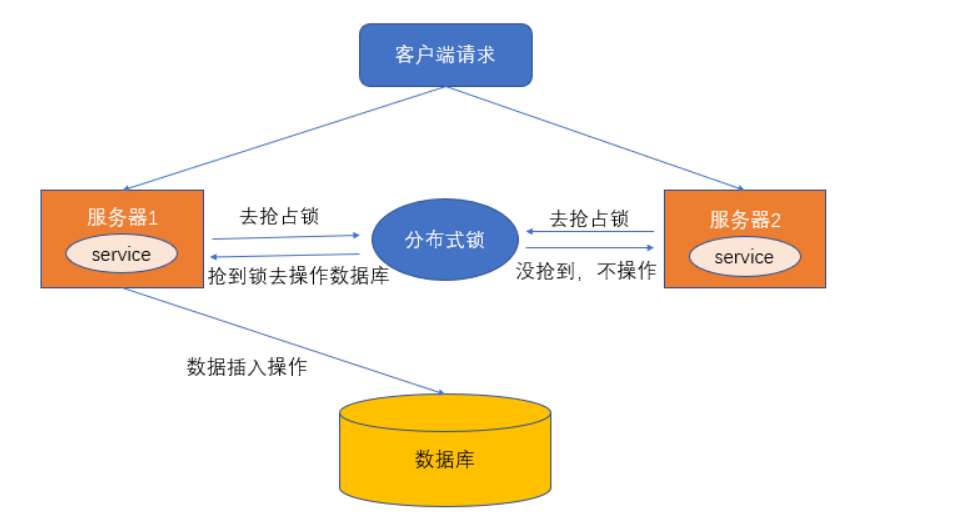
何为分布式锁?
- 当在分布式模型下,数据只有一份(或有限制),此时需要利用锁的技术控制某一时刻修改数据的进程数。
- 用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
分布式锁的条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 具有容错性。只要大部分的 Redis 节点正常运行,客户端就可以加锁和解锁。
- 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
分布式锁的实现:
分布式锁的实现由很多种,文件锁、数据库、redis等等,比较多;分布式锁常见的多种实现方式:
- 数据库悲观锁、
- 数据库乐观锁;
- 基于Redis的分布式锁;
- 基于ZooKeeper的分布式锁。
在实践中,还是redis做分布式锁性能会高一些
数据库悲观锁
所谓悲观锁,悲观锁是对数据被的修改持悲观态度(认为数据在被修改的时候一定会存在并发问题),因此在整个数据处理过程中将数据锁定。
悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在应用层中实现了加锁机制,也无法保证外部系统不会修改数据)。
数据库的行锁、表锁、排他锁等都是悲观锁,这里以行锁为例,进行介绍。以我们常用的MySQL为例,我们通过使用select...for update语句, 执行该语句后,会在表上加持行锁,一直到事务提交,解除行锁。
使用场景举例:
在秒杀案例中,生成订单和扣减库存的操作,可以通过商品记录的行锁,进行保护。们通过使用select...for update语句,在查询商品表库存时将该条记录加锁,待下单减库存完成后,再释放锁。
示例的SQL如下:
//0.开始事务
begin;
//1.查询出商品信息
select stockCount from seckill_good where id=1 for update;
//2.根据商品信息生成订单
insert into seckill_order (id,good_id) values (null,1);
//3.修改商品stockCount减一
update seckill_good set stockCount=stockCount-1 where id=1;
//4.提交事务
commit;
以上,在对id = 1的记录修改前,先通过for update的方式进行加锁,然后再进行修改。这就是比较典型的悲观锁策略。
如果以上修改库存的代码发生并发,同一时间只有一个线程可以开启事务并获得id=1的锁,其它的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改。
我们使用select_for_update,另外一定要写在事务中.
注意:要使用悲观锁,我们必须关闭mysql数据库中自动提交的属性,命令set autocommit=0;即可关闭,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。
悲观锁的实现,往往依靠数据库提供的锁机制。在数据库中,悲观锁的流程如下:
- 在对记录进行修改前,先尝试为该记录加上排他锁(exclusive locking)。
- 如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。具体响应方式由开发者根据实际需要决定。
- 如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
- 其间如果有其他事务对该记录做加锁的操作,都要等待当前事务解锁或直接抛出异常。
数据库乐观锁
使用乐观锁就不需要借助数据库的锁机制了。
乐观锁的概念中其实已经阐述了他的具体实现细节:主要就是两个步骤:冲突检测和数据更新。其实现方式有一种比较典型的就是Compare and Swap(CAS)技术。
CAS是项乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
CAS的实现中,在表中增加一个version字段,操作前先查询version信息,在数据提交时检查version字段是否被修改,如果没有被修改则进行提交,否则认为是过期数据。
比如前面的扣减库存问题,通过乐观锁可以实现如下:
//1.查询出商品信息
select stockCount, version from seckill_good where id=1;
//2.根据商品信息生成订单
insert into seckill_order (id,good_id) values (null,1);
//3.修改商品库存
update seckill_good set stockCount=stockCount-1, version = version+1 where id=1, version=version;
以上,我们在更新之前,先查询一下库存表中当前版本(version),然后在做update的时候,以version 作为一个修改条件。
当我们提交更新的时候,判断数据库表对应记录的当前version与第一次取出来的version进行比对,如果数据库表当前version与第一次取出来的version相等,则予以更新,否则认为是过期数据。
CAS 乐观锁有两个问题:
(1) CAS 存在一个比较重要的问题,即ABA问题. 解决的办法是version字段顺序递增。
(2) 乐观锁的方式,在高并发时,只有一个线程能执行成功,会造成大量的失败,这给用户的体验显然是很不好的。
Redis分布式锁
Redis分布式锁:
(1)基于Jedis手工造轮子分布式锁
(2)Redission 分布式锁
分布式锁一般有如下的特点:
- 互斥性: 同一时刻只能有一个线程持有锁
- 可重入性: 同一节点上的同一个线程如果获取了锁之后能够再次获取锁
- 锁超时:和J.U.C中的锁一样支持锁超时,防止死锁
- 高性能和高可用: 加锁和解锁需要高效,同时也需要保证高可用,防止分布式锁失效
- 具备阻塞和非阻塞性:能够及时从阻塞状态中被唤醒
基于Jedis 的API实现分布式锁
我们首先讲解 Jedis 普通分布式锁实现,并且是纯手工的模式,从最为基础的Redis命令开始。
只有充分了解与分布式锁相关的普通Redis命令,才能更好的了解高级的Redis分布式锁的实现,因为高级的分布式锁的实现完全基于普通Redis命令。
Redis几种架构
Redis发展到现在,几种常见的部署架构有:
- 单机模式;
- 主从模式;
- 哨兵模式;
- 集群模式;
从分布式锁的角度来说, 无论是单机模式、主从模式、哨兵模式、集群模式,其原理都是类同的。 只是主从模式、哨兵模式、集群模式的更加的高可用、或者更加高并发。
所以,接下来先基于单机模式,基于Jedis手工造轮子实现自己的分布式锁。
首先看两个命令:
Redis分布式锁机制,主要借助setnx和expire两个命令完成。
setnx命令:
SETNX 是SET if Not eXists的简写。将 key 的值设为 value,当且仅当 key 不存在; 若给定的 key 已经存在,则 SETNX 不做任何动作。
下面为客户端使用示例:
127.0.0.1:6379> set lock "unlock" OK 127.0.0.1:6379> setnx lock "unlock" (integer) 0 127.0.0.1:6379> setnx lock "lock" (integer) 0 127.0.0.1:6379>
expire命令:
expire命令为 key 设置生存时间,当 key 过期时(生存时间为 0 ),它会被自动删除. 其格式为:
EXPIRE key seconds
下面为客户端使用示例:
127.0.0.1:6379> expire lock 10 (integer) 1 127.0.0.1:6379> ttl lock 8
基于Jedis API的分布式锁的总体流程:
通过Redis的setnx、expire命令可以实现简单的锁机制:
- key不存在时创建,并设置value和过期时间,返回值为1;成功获取到锁;
- 如key存在时直接返回0,抢锁失败;
- 持有锁的线程释放锁时,手动删除key; 或者过期时间到,key自动删除,锁释放。
线程调用setnx方法成功返回1认为加锁成功,其他线程要等到当前线程业务操作完成释放锁后,才能再次调用setnx加锁成功。

以上简单redis分布式锁的问题:
如果出现了这么一个问题:如果setnx是成功的,但是expire设置失败,一旦出现了释放锁失败,或者没有手工释放,那么这个锁永远被占用,其他线程永远也抢不到锁。
所以,需要保障setnx和expire两个操作的原子性,要么全部执行,要么全部不执行,二者不能分开。
解决的办法有两种:
- 使用set的命令时,同时设置过期时间,不再单独使用 expire命令
- 使用lua脚本,将加锁的命令放在lua脚本中原子性的执行
简单加锁:使用set的命令时,同时设置过期时间
使用set的命令时,同时设置过期时间的示例如下:
127.0.0.1:6379> set unlock "234" EX 100 NX (nil) 127.0.0.1:6379> 127.0.0.1:6379> set test "111" EX 100 NX OK
这样就完美的解决了分布式锁的原子性; set 命令的完整格式:
set key value [EX seconds] [PX milliseconds] [NX|XX]
EX seconds:设置失效时长,单位秒 PX milliseconds:设置失效时长,单位毫秒 NX:key不存在时设置value,成功返回OK,失败返回(nil) XX:key存在时设置value,成功返回OK,失败返回(nil)
ZooKeeper分布式锁的原理
公平锁和可重入锁的原理
最经典的分布式锁是可重入的公平锁。什么是可重入的公平锁呢?直接讲解的概念和原理,会比较抽象难懂,还是从具体的实例入手吧!这里用一个简单的故事来类比,估计就简单多了。
故事发生在一个没有自来水的古代,在一个村子有一口井,水质非常的好,村民们都抢着取井里的水。井就那么一口,村里的人很多,村民为争抢取水打架斗殴,甚至头破血流。
问题总是要解决,于是村长绞尽脑汁,最终想出了一个凭号取水的方案。井边安排一个看井人,维护取水的秩序。取水秩序很简单:
(1)取水之前,先取号;
(2)号排在前面的,就可以先取水;
(3)先到的排在前面,那些后到的,一个一个挨着,在井边排成一队。
取水示意图,如图10-3所示。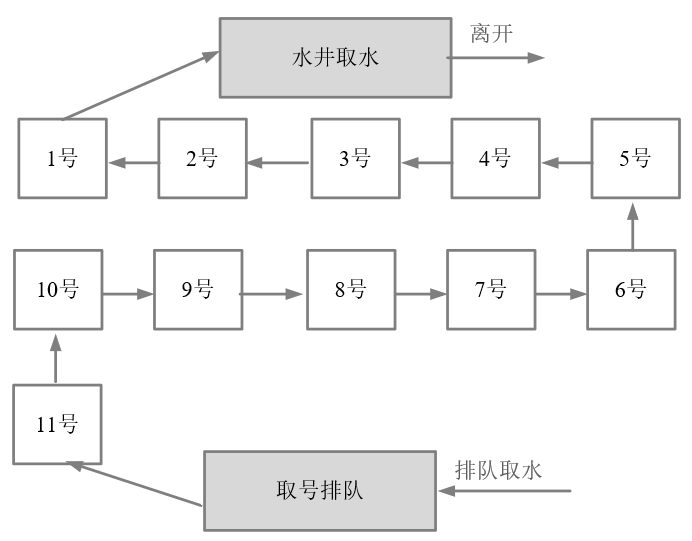
图10-3 排队取水示意图
这种排队取水模型,就是一种锁的模型。排在最前面的号,拥有取水权,就是一种典型的独占锁。另外,先到先得,号排在前面的人先取到水,取水之后就轮到下一个号取水,挺公平的,说明它是一种公平锁。
什么是可重入锁呢?
假定,取水时以家庭为单位,家庭的某人拿到号,其他的家庭成员过来打水,这时候不用再取号,如图10-4所示。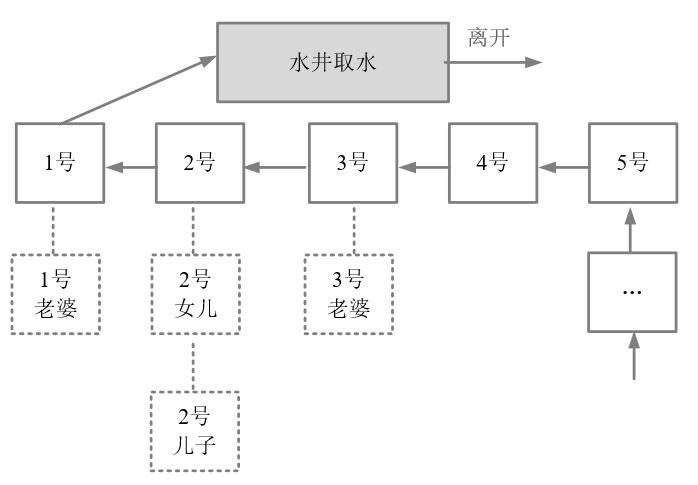
图10-4 同一家庭的人不需要重复排队
图10-4中,排在1号的家庭,老公取号,假设其老婆来了,直接排第一个,正所谓妻凭夫贵。再看上图的2号,父亲正在打水,假设其儿子和女儿也到井边了,直接排第二个,所谓子凭父贵。总之,如果取水时以家庭为单位,则同一个家庭,可以直接复用排号,不用从后面排起重新取号。
以上这个故事模型中,取号一次,可以用来多次取水,其原理为可重入锁的模型。在重入锁模型中,一把独占锁,可以被多次锁定,这就叫做可重入锁。
理解了经典的公平可重入锁的原理后,再来看在分布式场景下的公平可重入锁的原理。通过前面的分析,基本可以判定:ZooKeeper
的临时顺序节点,天生就有一副实现分布式锁的胚子。为什么呢?
(一) ZooKeeper的每一个节点,都是一个天然的顺序发号器。
在每一个节点下面创建临时顺序节点(EPHEMERAL_SEQUENTIAL)类型,新的子节点后面,会加上一个次序编号,而这个生成的次序编号,是上一个生成的次序编号加一。
例如,有一个用于发号的节点“/test/lock”为父亲节点,可以在这个父节点下面创建相同前缀的临时顺序子节点,假定相同的前缀为“/test/lock/seq-”。第一个创建的子节点基本上应该为/test/lock/seq-0000000000,下一个节点则为/test/lock/seq-0000000001,依次类推,如果10-5所示。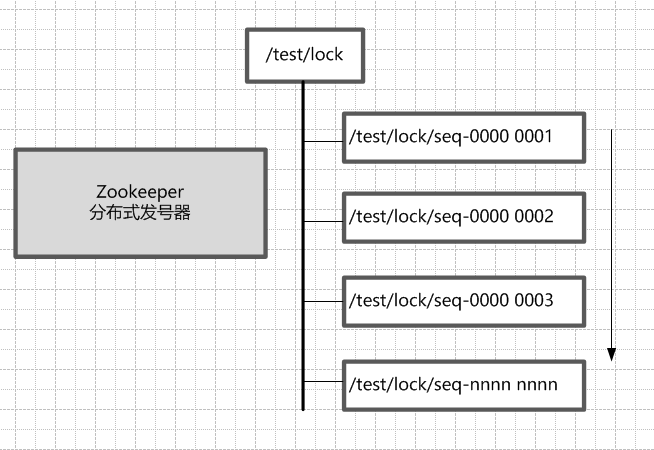
图10-5 Zookeeper临时顺序节点的天然的发号器作用
(二) ZooKeeper节点的递增有序性,可以确保锁的公平
一个ZooKeeper分布式锁,首先需要创建一个父节点,尽量是持久节点(PERSISTENT类型),然后每个要获得锁的线程,都在这个节点下创建个临时顺序节点。由于ZK节点,是按照创建的次序,依次递增的。
为了确保公平,可以简单的规定:编号最小的那个节点,表示获得了锁。所以,每个线程在尝试占用锁之前,首先判断自己是排号是不是当前最小,如果是,则获取锁。
(三)ZooKeeper的节点监听机制,可以保障占有锁的传递有序而且高效
每个线程抢占锁之前,先尝试创建自己的ZNode。同样,释放锁的时候,就需要删除创建的Znode。创建成功后,如果不是排号最小的节点,就处于等待通知的状态。等谁的通知呢?不需要其他人,只需要等前一个Znode
的通知就可以了。前一个Znode删除的时候,会触发Znode事件,当前节点能监听到删除事件,就是轮到了自己占有锁的时候。第一个通知第二个、第二个通知第三个,击鼓传花似的依次向后。
ZooKeeper的节点监听机制,能够非常完美地实现这种击鼓传花似的信息传递。具体的方法是,每一个等通知的Znode节点,只需要监听(linsten)或者监视(watch)排号在自己前面那个,而且紧挨在自己前面的那个节点,就能收到其删除事件了。
只要上一个节点被删除了,就进行再一次判断,看看自己是不是序号最小的那个节点,如果是,自己就获得锁。
另外,ZooKeeper的内部优越的机制,能保证由于网络异常或者其他原因,集群中占用锁的客户端失联时,锁能够被有效释放。一旦占用Znode锁的客户端与ZooKeeper集群服务器失去联系,这个临时Znode也将自动删除。排在它后面的那个节点,也能收到删除事件,从而获得锁。正是由于这个原因,在创建取号节点的时候,尽量创建临时znode
节点,
(四)ZooKeeper的节点监听机制,能避免羊群效应
ZooKeeper这种首尾相接,后面监听前面的方式,可以避免羊群效应。所谓羊群效应就是一个节点挂掉,所有节点都去监听,然后做出反应,这样会给服务器带来巨大压力,所以有了临时顺序节点,当一个节点挂掉,只有它后面的那一个节点才做出反应。
图解:分布式锁的抢占过程
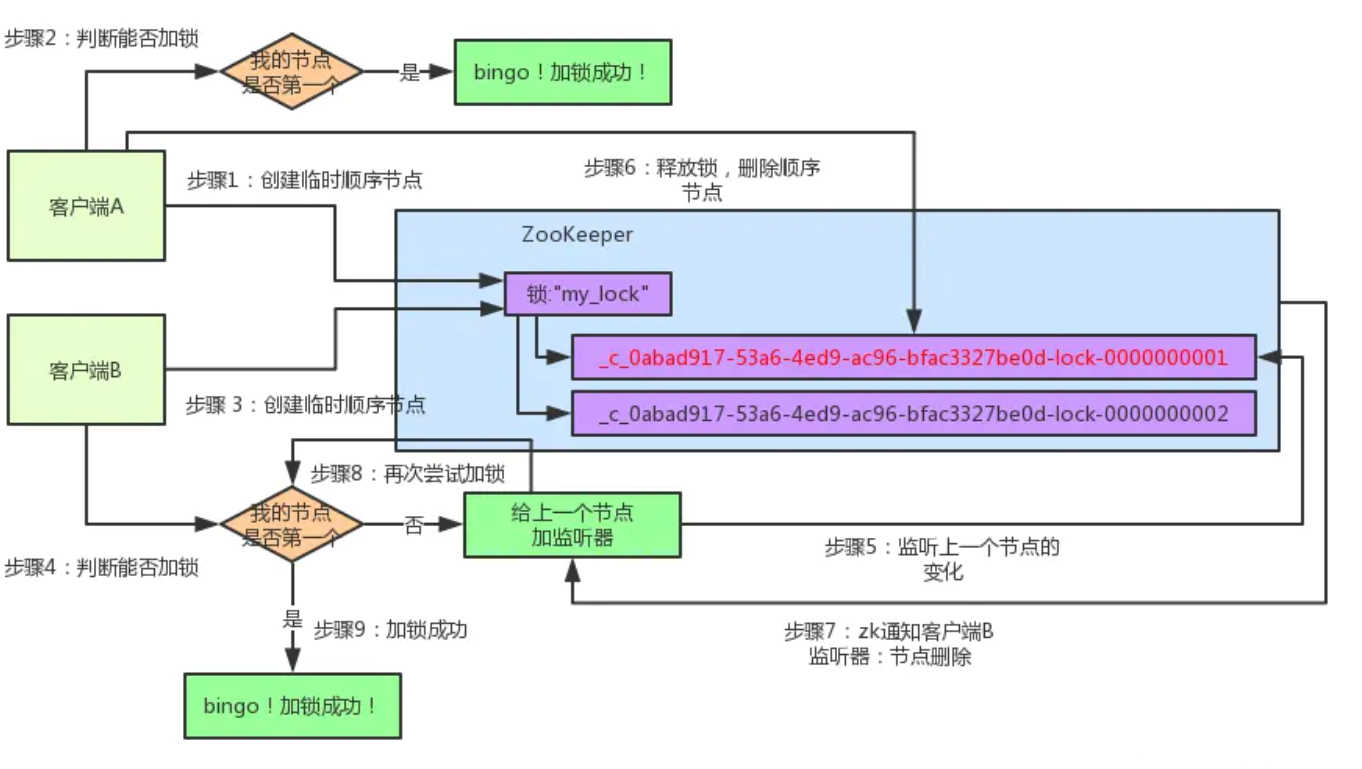
1)、客户端A发起一个加锁请求
客户端A发起一个加锁请求,先会在你要加锁的node下搞一个临时顺序节点,这一大坨长长的名字都是Curator框架自己生成出来的。
然后,那个最后一个数字是"1"。大家注意一下,因为客户端A是第一个发起请求的,所以给他搞出来的顺序节点的序号是"1"。
接着客户端A创建完一个顺序节点。还没完,他会查一下"my_lock"这个锁节点下的所有子节点,并且这些子节点是按照序号排序的,这个时候他大概会拿到这么一个集合:

接着客户端A会走一个关键性的判断,就是说:唉!兄弟,这个集合里,我创建的那个顺序节点,是不是排在第一个啊?
如果是的话,那我就可以加锁了啊!因为明明我就是第一个来创建顺序节点的人,所以我就是第一个尝试加分布式锁的人啊!
bingo!加锁成功!
2)、客户端B过来排队
客户端A都加完锁了,客户端B过来想要加锁了,这个时候他会干一样的事儿:先是在"my_lock"这个锁节点下创建一个临时顺序节点,此时名字会变成类似于:

客户端B因为是第二个来创建顺序节点的,所以zk内部会维护序号为"2"。
接着客户端B会走加锁判断逻辑,查询"my_lock"锁节点下的所有子节点,按序号顺序排列,此时他看到的类似于:
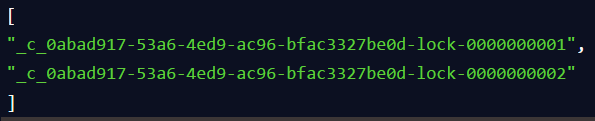
同时检查自己创建的顺序节点,是不是集合中的第一个?
明显不是啊,此时第一个是客户端A创建的那个顺序节点,序号为"01"的那个。所以加锁失败!
3)、客户端B开启监听客户端A
加锁失败了以后,客户端B就会通过ZK的API对他的顺序节点的上一个顺序节点加一个监听器。zk天然就可以实现对某个节点的监听。监听这个节点是否被删除等变化!
接着,客户端A加锁之后,可能处理了一些代码逻辑,然后就会释放锁。那么,释放锁是个什么过程呢?
其实很简单,就是把自己在zk里创建的那个顺序节点,也就是:

这个节点给删除。
删除了那个节点之后,zk会负责通知监听这个节点的监听器,也就是客户端B之前加的那个监听器,说:兄弟,你监听的那个节点被删除了,有人释放了锁。
4)客户端B抢锁成功
此时客户端B的监听器感知到了上一个顺序节点被删除,也就是排在他之前的某个客户端释放了锁。
此时,就会通知客户端B重新尝试去获取锁,也就是获取"my_lock"节点下的子节点集合,此时为:

集合里此时只有客户端B创建的唯一的一个顺序节点了!
然后呢,客户端B判断自己居然是集合中的第一个顺序节点,bingo!可以加锁了!直接完成加锁,运行后续的业务代码即可,运行完了之后再次释放锁。















 2866
2866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









