







shell端执行mapreduce
1.准备数据,这个数据必须存储在hdfs上,并不是linux目录上的数据
2.mapreduce程序
Wordcount---->词频统计
/export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/mr-examples(有很多的jar包)
3.将mapreduce程序提交到yarn上面去运行
提交方式只有一种:

后面跟jar的文件 以及运行的主类
Bin/yarn jar share/hadoop/mapreduce/mr-examples
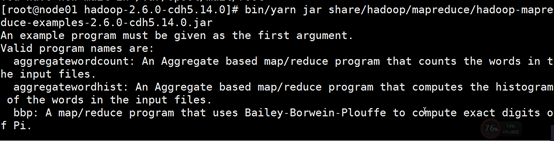

In:表示mapreduce程序要数据所在的位置
Out:mapredecde 程序输出所在位置 该目录必须不存在

Mapreduce 数据处理过程
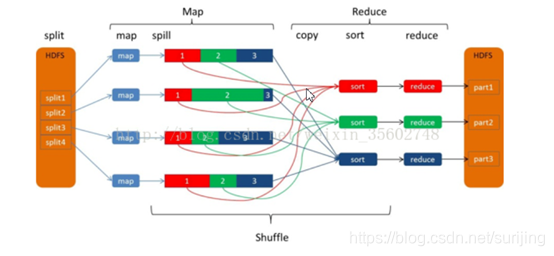
1.Input (确保数据保存在HDFS上,当然你可以选择本地运行)
2.map(数据先缓存在内存中,溢出到磁盘中)
3.shuffle(框架自动执行)
4.reduce(对shuffle的结果进行合并)
5.output(存放结果的目录必须事先不存在)
input 和 output 不需要我们去编写过多的代码,主要是给个路径就可以
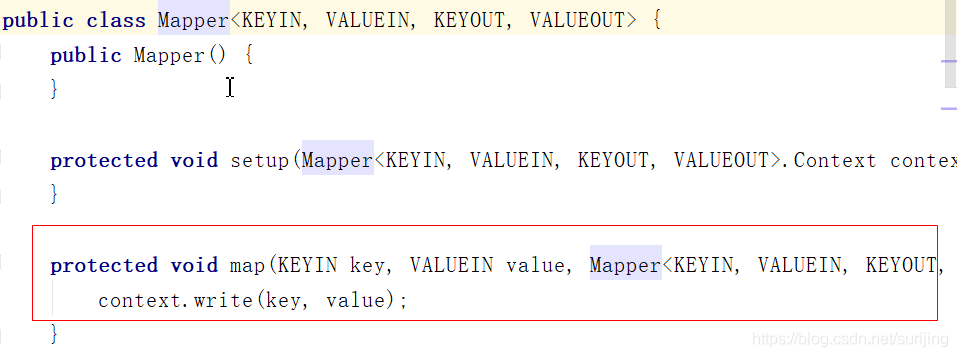
着重关注map 和 reduce,两者都只是一个方法,我们只需要去重写方法。
源码:
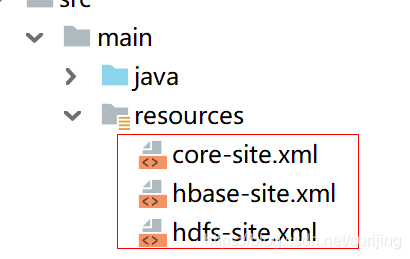
在编写代码之前,把集群的配置文件导入idea
package mapredeuce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Ma 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1069
1069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









