







先来看一个TopK题目: 搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
如何解答?Topk之前已经说过,寻找最小的K个数。
可是我们如何处理Query呢?一千万条记录,每条记录是255Byte,很显然要占据2.375G内存,很明显不能用内部的排序,无论是什么内部排序。这个时候可以用外排序,归并排序可以解决。可是题目也说了除去重复最多300W,300W完全可以放入内存,可是如何把1000W的字符串放入内存呢?这就是我们接下来要说的了,Hsah Table完全可以解决。
不要着急,听我细细道来。
说哈希之前先来说一下直接寻址表,这个类似BloomFilter和位向量。如果关键字域比较小,也就是说关键字不多,而且都在一定范围内。那我们可以完全把关键字当成数组下标,每一个关键字放入哈希表的一个槽。这也即是一一映射,映射结果不变化。
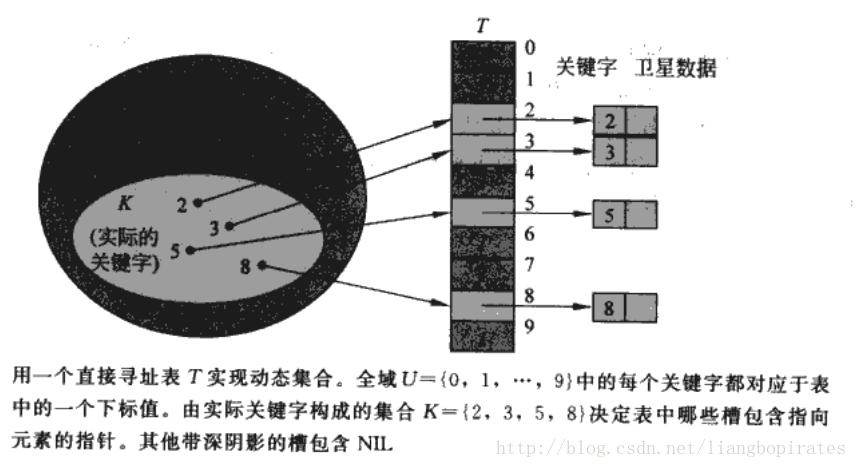
这个看起来蛮不错的,操作也很简单,每个操作时间代价都是O(1).

确实很不错。可是这只是关键字分布较小范围的时候才会有作用,而且还要求关键字都不能相等。。。如果有100个整数,都是64位的,有的很小,有的超大。这个时候你定义的数组的大小岂不是2^64-1,你能忍受吗?你还会用这种方法吗?2个数,1和100000000,你定义的数组大小也必须是100000000,这样才符合刚才的直接寻址法。太浪费内存了吧。。 所以来说,直接寻址固然不错,可是限制太多。关键字不重复,关键字的范围要小。 接下来我正式的介绍一下哈希表。 什么是哈希表?Hash Table也叫散列表。 哈希表是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度,存放记录的数组叫做哈希表。建好的Hash表的查询速度是常数级O(1),这样就比较nice了。 Hash映射就是用一个Hash函数将关键字key映射到Hash表的槽里。这个映射不是一一映射了,即便是一个字符串也能映射成一个整数。对于刚才的直接寻址表来说就是key映射到key槽,而Hash函数将key映射到H(key)槽里。而我们要定义的表的大小只是关键字的数量,不必是关键字范围的大小和关键字的重复,这样就不会浪费内存。而且插入一个需要的时间也是O(1),不过我们用Hash表大部分是为了查
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2106
2106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









