







内部的原理实现:
map:【头文件为#include<map>】map内部是一颗红黑树(非严格平衡二叉树),红黑树有自动排序的功能,所以map内部的所有元素都是有序的,红黑树的每一个节点都代表这map的一个元素。因此对map进行插入、删除、查找等操作都是相当于对红黑树进行操作。最后根据树的中序遍历可以将键值按照大小顺序遍历出来。
unordered_map:【头文件#include<unordered_map>】unordered_map内部是一个哈希表(散列表,把关健值映射到哈希表中的某一个位置,这样查找时间复杂度是O(1)),元素的排列顺序是无序的。
优缺点:
map:
1、优点:
(1)有序性:map结构的红黑树自身是有序的,但是要中序遍历输出
(2)时间复杂度低:内部结构时红黑树,红黑树很多操作都是在logn的时间复杂度下实现的,因此效率高。
2、缺点:
空间占有率高,因为map内部实现是红黑树,虽然它时间复杂度低,运行效率高,但是因为每一个节点都需要额外保存父 节点、孩子节点和红黑树性质,这样使得每一个节点都占用大量的空间。
3、应用场景:
应用于对顺序有要求的问题,用map会更高效。
unordered_map:
1、优点:内部结构是哈希表,查找为O(1),效率高。
2、缺点:哈希表的建立耗费时间。
3、应用场景: 对于频繁查找的问题,用unordered_map更高效。
总结:
1、内存占用率问题转化为 红黑树 VS 哈希表,还是unordered_map内存占用高。
2、但是unordered_map执行效率高。
3、对于unordered_map或unordered_set容器,其遍历顺序与创建该容器时输入的顺序不一定相同,因为遍历是按照哈希表从前往后依次遍历的。
map和unordered_map的使用
unordered_map与map用法一致,里面的元素以pair类型存储。虽然底层实现完全不同,但是外部使用一致。
map:
int main()
{
map<int,string> mymap;
mymap.insert(pair<int,string>(5,"孙"));
mymap.insert(pair<int,string>(2,"安"));
mymap.insert(pair<int,string>(3,"施"));
mymap.insert(pair<int,string>(3,"杨"));//key值唯一,相同的key插不进去
auto iter = mymap.begin();
while(iter != mymap.end())
{
cout<<iter->first<<","<<iter->second<<endl;
++iter;
}
auto iter2 = mymap.find(2);//返回一个指向key = 1的迭代器
if(iter2 != mymap.end())
{
cout<<"true"<<endl;
cout<<iter2->first<<","<<iter2->second<<endl;
}
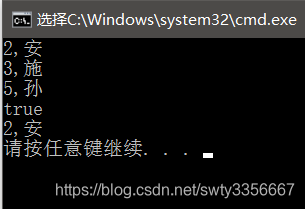
}运行结果:无论怎么插进去数据,都会按照key的大小顺序排列,注意:key值唯一,两个一样的key插入时,第二条数据插不进去。
unordered_map:
int main()
{
unordered_map<int,string> mymap;
mymap.insert(pair<int,string>(5,"孙"));
mymap.insert(pair<int,string>(2,"安"));
mymap.insert(pair<int,string>(3,"施"));
mymap.insert(pair<int,string>(3,"杨"));//key值唯一,相同的key插不进去
auto iter = mymap.begin();
while(iter != mymap.end())
{
cout<<iter->first<<","<<iter->second<<endl;
++iter;
}
auto iter2 = mymap.find(2);//返回一个指向key = 1的迭代器
if(iter2 != mymap.end())
{
cout<<"true"<<endl;
cout<<iter2->first<<","<<iter2->second<<endl;
}
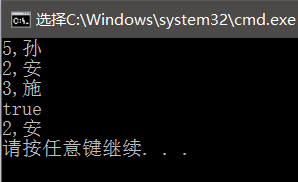
}运行结果:以怎样的顺序插进unordered_map表,以怎样的顺序打印出来,不会进行自动排序,注意:key值唯一,两个一样的key插入时,第二条数据插不进去。
count方法与find方法的区别
mymap.count(key):计算的是下标为key的位置有无数据,有返回1,无返回0
mymap.find(key):得到的对象时一个迭代器,需要对迭代器进行判断是否是mymap.end(),如果是则无数据,如果不是则有数据
参考:https://blog.csdn.net/zjajgyy/article/details/65935473














 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









