






数据文件真正存储的地方是在datanode,当用户需要填充文件中某一个block的实际数据内容时,就需要连接到datanode进行实际的block写入操作,下面我们看一下datanode如何管理block,以及如何存储block。
Datanode是通过文件存储block数据的,datanode中有一个FSDatasetInterface接口,这个接口的主要作用就是对block对应的实际数据文件进行操作。
首先我们看一下这部分涉及的主要类关系:
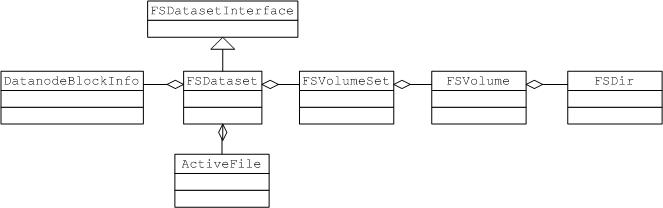
FSDataset实现了接口FSDatasetInterface,主要承载block对应的文件操作。
FSDataset有几个重要的属性:
FSVolumeSet volumes;
private HashMap<Block, ActiveFile> ongoingCreates = new HashMap<Block, ActiveFile>();
private HashMap<Block, DatanodeBlockInfo> volumeMap = null;
Datanode可以配置多个目录来存储block对应的文件,配置的每一个目录就对应一个FSVolume,每一个FSVolume对应的目录中会有一个current目录,这个目录进行实际文件存放,同时系统会在这个目录下自行创建很多子文件夹(每个文件夹存放的文件个数是有限制的)。每个子文件夹就会对应一个FSDir对象。
我么先看一个FSVolume对应目录的文件结构:

/data1/dfs/data/这个目录是我们配置的一个存储block对应的文件的目录,也就是对应一个FSVolume,其中current目录是我们真正存放block数据块文件的地方,其中还有一个tmp目录,这个目录主要临时存放一些正在写入的block数据文件,成功写入完成后这个临时文件就会从tmp目录移动到current目录。
看一下我们的配置文件内容
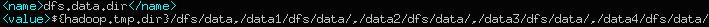
可以看到我们配置了/data1/dfs/data/目录做为我们数据存储目录之一。
下面我们看一下实际的/data1/dfs/data/current目录下会有那些内容:
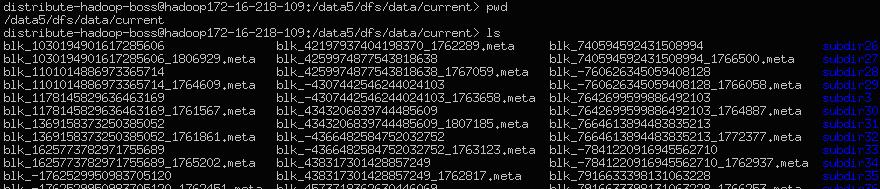
可以看到这个目录主要存放了block数据文件,block数据文件的命名规则是blk_$BLOCKID$,还有就是block文件的元数据文件,元数据文件的命名规则是:blk_$BLOCKID$_$时间戳$,同时大家可以看到很多累似subdir00命名的文件夹,这些文件夹其中存放的也是block数据文件及其元数据文件,hadoop规定每个目录存放的block数据文件个数是有限制的,达到限制之后就会新建sub子目录进行存放,这些sub子目录包括current目录,都会和一个FSDir对象对应。
我们来看一下FSDir对象,这个对象和文件系统中的目录是很相近的概念,他的主要作用就是管理一个目录下的所有与block相关的文件。
我们先看一个这个类的主要属性:
//这个对象对应的文件目录对象。
File dir;
//这个目录下的子文件夹对象
FSDir children[];
这个对象在进行实例化构造的过程就会遍历文件夹下的文件,判断哪些是目录,然后生成相应的FSDir添加到children数组中。
主要方法:
void getVolumeMap(HashMap<Block, DatanodeBlockInfo> volumeMap,
FSVolume volume)
这个方法的主要目的就是遍历整个目录,得到所有block文件列表,并添加所有block的记录到FSDataset的volumeMap属性中,参数中的volumeMap传入的正是FSDataset的volumeMap属性,这个对象保存block与DatanodeBlockInfo的映射关系,便于通过block查询具体的block文件信息。
datanodeBlockInfo对象主要保存了block属于哪一个FSVolume,以及block块实际的存放文件是哪个。
{
if (children != null)
{
for (int i = 0; i < children.length; i++)
{
//遍历子文件夹
children[i].getVolumeMap(volumeMap, volume);
}
}
File blockFiles[] = dir.listFiles();
for (int i = 0; i < blockFiles.length; i++)
{
//判断文件是否是一个block,主要是通过文件名来判断的,block的文件名的命名特征是"blk_$BLOCKID"
if (Block.isBlockFilename(blockFiles[i]))
{
long genStamp = getGenerationStampFromFile(blockFiles,
blockFiles[i]);
volumeMap.put(new Block(blockFiles[i], blockFiles[i]
.length(), genStamp), new DatanodeBlockInfo(volume,blockFiles[i]));
}
}
}
Volumes相对来说比较简单,他就是一个FSVolume集合,并封装了对所有volume的操作,比如:getBlockReport()这个方法,就是得到所有的block列表,上报给namenode。有了volumes这个集合对象,类似这样的操作就可以封装起来,方便后续操作。
ongoingCreates
这个对象主要存储了正在创建的block列表,这个对象中的block表示用户正在进行该block文件数据上传操作,这个对象中包含ActiveFile对象的实例,我们先看一下ActiveFile对象,这个对象中有两个关键属性:1.对象对应的数据文件。2.正在操作这个文件的线程列表。
final File file;
final List<Thread> threads = new ArrayList<Thread>(2);
保存线程列表的主要目的是:
在进行block文件写入操作时,如果datanode收到了对这个block进行recoverblock的请求后,需要先interrupt所有正在写入这个block文件的线程。
我们先看一下文件数据的接受流程。
在接下来的3.2.2章节我们会详细介绍datanode接收数据的协议,下文中会提到Datanode构建一个BlockReceiver实例,进行实际数据的接受操作。
BlockReceiver在构建实例过程中会首先通过如下方法:streams = datanode.data.writeToBlock(block, isRecovery);打开block数据写入datanode本地文件的通道,以便datanode接收到block数据块儿内容以后将数据内容写入磁盘。第一步我们可能需要了解BlockWriteStreams这个对象,因为writeToBlock会返回BlockWriteStreams对象实例。
static class BlockWriteStreams
{
OutputStream dataOut;
OutputStream checksumOut;
BlockWriteStreams(OutputStream dOut, OutputStream cOut) {
dataOut = dOut;
checksumOut = cOut;
}
我们可以看到这个对象包含两个重要的属性:dataOut,checksumOut。从字面意思我们也可以揣测到,这两个outputstream对象,一个用来写入block数据,一个用来写入block数据中的checksum数据。
接下来我们详细分析一下这个方法:
public BlockWriteStreams writeToBlock(Block b, boolean isRecovery)
{
...
//前面主要做一些合法性判断。
...
if (!isRecovery)
{
v = volumes.getNextVolume(blockSize);
//这是很重要的方法,主要是先创建一个临时文件存储上传的数据,等一个完成的block文件写入完成以后,再将这个文件以及元数据文件移动到正式文件目录。
f = createTmpFile(v, b);
volumeMap.put(b, new DatanodeBlockInfo(v));
...
}
...
return createBlockWriteStreams(f, metafile);
}
主要是创建一个临时文件和一个存放元数据信息的临时文件,然后打开两个文件将返回的OutputStream返回给前端。














 6151
6151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









