






笔者喜欢把字节流和字符流放在一起讲解,因为它们的操作方式几乎完全一样,区别只是操作的数据单元不同而已——字节流操作的数据单元是字节,字符流操作的数据单元是字符。
1,InputStream 和 Reader
InputStream 和 Reader 是所有输入流的抽象基类,本身并不能创建实例来执行输入,但它们将成为所有输入流的模板,所以它们的方法是所有输入流都可使用的方法。
在 InputStream 里包含如下 3 个方法。
int read():从输入流中读取单个字节,返回所读取的字节数据(字节数据可直接转换为 int 类型)。
int read(byte[] b):从输入流中最多读取 b.length 个字节的数据,并将其存储在字节数组 b 中,返回实际读取的字节数。
int read(byte[] b, int off, int len):从输入流中最多读取 len 个字节的数据,并将其存储在数组 b 中,放入数组 b 中时,并不是从数组起点开始,而是从 off 位置开始,返回实际读取的字节数。
在 Reader 里包含如下 3 个方法。
int read():从输入流中读取单个字符,返回所读取的字符数据(字符数据可直接转换为 int 类型)。
int read(char[] cbuf):从输入流中最多读取 cbuf.length 个字符的数据,并将其存储在字符数组 cbuf 中,返回实际读取的字符数。
int read(char[] cbuf, int off, int len):从输入流中最多读取 len 个字符的数据,并将其存储在字符数组 cbuf 中,放入数组 cbuf 中时,并不是从数组起点开始,而是以 off 位置开始,返回实际读取的字符数。
对比 InputStream 和 Reader 所提供的方法,就不难发现这两个基类的功能基本是一样的。InputStream 和 Reader 都是将输入数据抽象成水管,所以程序既可以通过 read() 方法每次读取一个“水滴”,也可以通过 read(char[] cbuf) 或 read(byte[] b) 方法来读取多个“水滴”:当使用数组作为 read() 方法的参数时,我们可以理解为使用一个 “竹筒” 到如图 15.5 所示的水管中取水,如图 15.8 所示。read(char[] cbuf) 方法中的数组可理解成一个 “竹筒” 程序每次调用输入流的 read(char[] cbuf) 或 read(byte[] b) 方法,就相当于用 “竹筒” 从输入流中取出一筒 “水滴” ,程序得到 “竹筒” 里的 “水滴” 后,转换成相应的数据即可:程序多次重复这个 “取水” 过程,直到最后。程序如何判断取水取到了最后呢?直到 read(char[] cbuf) 或 read(byte[] b) 方法返回 -1,即表明到了输入流的结束点。
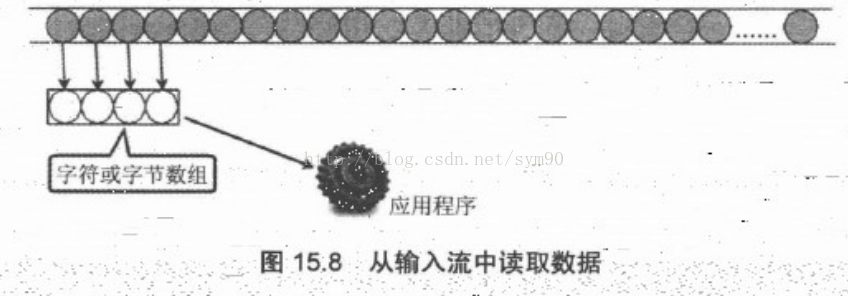
正如前面提到的,InputStream 和 Reader 都是抽象类,本身不能创建实例,但它们分别有一个用于读取文件的输入流:FilelnputStream 和 FileReader,它们都是节点流——会直接和指定文件关联。下面程序示范了使用 FilelnputStream 来读取自身的效果。
public class FileInputStreamTest
{
public static void main(String[] args) throws IOException
{
// 创建字节输入流
FileInputStream fis = new FileInputStream(
"FileInputStreamTest.java");
// 创建一个长度为1024的“竹筒”
byte[] bbuf = new byte[1024];
// 用于保存实际读取的字节数
int hasRead = 0;
// 使用循环来重复“取水”过程
while ((hasRead = fis.read(bbuf)) > 0 )
{
// 取出“竹筒”中水滴(字节),将字节数组转换成字符串输入!
System.out.print(new String(bbuf , 0 , hasRead ));
}
// 关闭文件输入流,放在finally块里更安全
fis.close();
}
}
上面程序中第 13 行代码是使用 FilelnputStream 循环 “取水” 的过程,运行上面程序,将会输出上面程序的源代码。
上面程序创建了一个长度为 1024 的字节数组来读取该文件,实际上该 Java 源文件的 1024 字节,也就是说,程序只需要执行一次 read() 方法即可读取全部内容,创建较小长度的字节数组,程序运行时在输出中文注释时就可能出现乱码——这是因为本文件保存时采用的是 GBK 编码方式,在这种方式下,每个中文字符占 2 字节,如果 read() 方法读取时只读到了半个中文字符,这将导致乱码。
上面程序最后使用了 fis.close() 来关闭该文件输入流,与 JDBC 编程一样,程序里打开的文件 IO 资源不属于内存里的资源,垃圾回收机制无法回收该资源,所以应该显式关闭文件 IO 资源。Java 7 改写了所有的 IO 资源类,它们都实现了 AutoCloseable 接口,因此都可通过自动关闭资源的 try 语句来关闭这些 IO 流。下面程序使用 FileReader 来读取文件本身。
public class FileReaderTest
{
public static void main(String[] args)
{
try(
// 创建字符输入流
FileReader fr = new FileReader("FileReaderTest.java"))
{
// 创建一个长度为32的“竹筒”
char[] cbuf = new char[32];
// 用于保存实际读取的字符数
int hasRead = 0;
// 使用循环来重复“取水”过程
while ((hasRead = fr.read(cbuf)) > 0 )
{
// 取出“竹筒”中水滴(字符),将字符数组转换成字符串输入!
System.out.print(new String(cbuf , 0 , hasRead));
}
}
catch (IOException ex)
{
ex.printStackTrace();
}
}
}上面的 FileReaderTest.java 程序与前面的 FilelnputStreamTest.java 并没有太大的不同,程序只是将字符数组的长度改为 32,这意味着程序需要多次调用 read() 方法才可以完全读取输入流的全部数据。程序最后使用了自动关闭资源的 try 语句来关闭文件输入流,这样可以保证输入流一定会被关闭。
除此之外,InputStream 和 Reader 还支持如下几个方法来移动记录指针。
void mark(int readAheadLimit):在记录指针当前位置记录一个标记(mark)。
boolean markSupported():判断此输入流是否支持 mark() 操作,即是否支持记录标记。
void reset():将此流的记录指针重新定位到上一次记录标记(mark)的位置。
long skip(long n):记录指针向前移动 n 个字节/字符。
2,OutputStream 和 Writer
OutputStream 和 Writer 也非常相似,它们采用如图 15.6 所示的模型来执行输出,两个流都提供了如下 3 个方法。
void write(int c):将指定的字节/字符输出到输出流中,其中 c 既可以代表字节,也可以代表字符。
void write(byte[]/char[] buf):将字节数组/字符数组中的数据输出到指定输出流中。
void write(byte[]/char[] buf, int off, int len):将字节数组/字符数组中从 off 位置开始,长度为 len 的字节/字符输出到输出流中。
因为字符流直接以字符作为操作单位,所以 Write r可以用字符串来代替字符数组,即以 String 对象作为参数。Writer 里还包含如下两个方法。
void write(String str):将 str 字符串里包含的字符输出到指定输出流中。
void write(String str, int off, int len):将 str 字符串里从 off 位置开始,长度为 len 的字符输出到指定输出流中。
下面程序使用 FilelnputStream 来执行输入,并使用 FileOutputStream 来执行输出,用以实现复制 FileOutputStreamTest.java 文件的功能。
public class FileOutputStreamTest
{
public static void main(String[] args)
{
try(
// 创建字节输入流
FileInputStream fis = new FileInputStream(
"FileOutputStreamTest.java");
// 创建字节输出流
FileOutputStream fos = new FileOutputStream("newFile.txt"))
{
byte[] bbuf = new byte[32];
int hasRead = 0;
// 循环从输入流中取出数据
while ((hasRead = fis.read(bbuf)) > 0 )
{
// 每读取一次,即写入文件输出流,读了多少,就写多少。
fos.write(bbuf , 0 , hasRead);
}
}
catch (IOException ioe)
{
ioe.printStackTrace();
}
}
}运行上面程序,将看到系统当前路径下多了一个文件:newFile.txt,该文件的内容和 FileOutputStreamTest.java 文件的内容完全相同。
使用 Java 的 IO 流执行输出时,不要忘记关闭输出流,关闭输出流出了可以保证流的物理资源被回收之外,可能还可以将输出流缓冲区的数据 flush 到物理节点里(因为在执行 close() 方法之前,自动执行输出流的 flush() 方法)。Java 的很多输出流默认都提供了缓冲功能,其实我们没有必要刻意去记忆哪些流有缓冲功能、哪些流没有,只要正常关闭所有的输出流即可保证程序正常。
如果希望直接输出字符串内容,则使用 Writer 会有更好的效果,如下程序所示。
public class FileWriterTest
{
public static void main(String[] args)
{
try(
FileWriter fw = new FileWriter("poem.txt"))
{
fw.write("锦瑟 - 李商隐\r\n");
fw.write("锦瑟无端五十弦,一弦一柱思华年。\r\n");
fw.write("庄生晓梦迷蝴蝶,望帝春心托杜鹃。\r\n");
fw.write("沧海月明珠有泪,蓝田日暖玉生烟。\r\n");
fw.write("此情可待成追忆,只是当时已惘然。\r\n");
}
catch (IOException ioe)
{
ioe.printStackTrace();
}
}
}
运行上面程序,将会在当前日录下输出一个 poem.txt 文件,文件内容就是程序中输出的内容。
上面程序在输出字符串内容时,字符串内容的最后是 \r\n,这是 windows 平台的换行符,通过这种方式就可以让输出内容换行;如果是 UNIX/Linux/BSD 等平台,则使用 \n 就作为换行符。














 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









