






HttpParser遇到table时,解析时,直接抽取th或者td,thead和tbody解析或出现异常。比如
<table>
<thead>
<tr>
相关内容...
</tr>
</thead>
<tbody>
<tr>
相关内容...
</tr>
</tbody>
</table>
如果获取table的element元素,然后getchildren时,获取的子节点,将类似这种形式(暂时忽略可能存在的“\n”):
第1个:<thead>
第2个:<tr>相关内容...</tr>
第3个:</thead>
第4个:<tbody>
第5个:<tr>相关内容...</tr>
第6个:<tbody>
这里直接将<thead>、</thead>、<tbody>和</tbody>分开单独解释了,而不是作为整体。具体原因不清楚。
猜测是不是因为HttpParser只识别W3School规定的标准的tag,因为测试了<b>、<i>、<em>和自定义的tag,都被单独识别,即<b></b>是两个子节点,而不是一个节点,其他类似。不过这个只是简单猜测,没有官方证明。
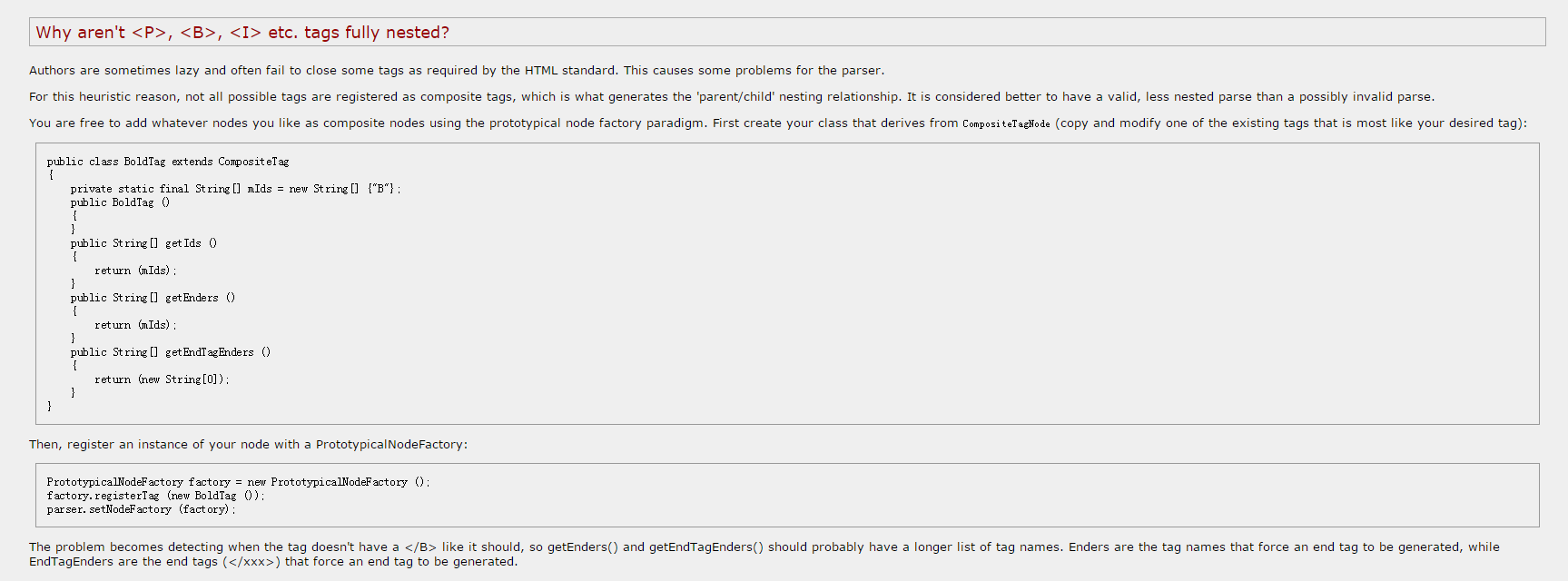
补充:HttpParser可以识别的节点,需要注册。系统预定义注册了一些,凡是没有注册,都不会被识别。官方原话:














 2552
2552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









