








1、python
本课程的机器学习的算法都是基于python语言实现的,所以你需要有一定的python语言基础,可以参考彭亮在麦子学院讲授的“Python语言编程基础”。
2、python机器学习的库:scikit-learn
特性:
1)简单高效的数据挖掘和机器学习分析
2)对所有用户开放,根据不同需求高度可重用性
3)基于Numpy, SciPy和matplotlib
4)开源,商用级别:获得 BSD许可
覆盖问题领域:
分类(classification),,回归(regression), 聚类(clustering),
降维(dimensionality reduction),模型选择(model selection), 预处理(preprocessing)
3、使用scikit-learn
方式一:pip, easy_install(两个都是python安装package的工具,感觉pip更好用)
方式二(推荐): 可使用Anaconda(这是一个科学计算环境 ,包含numpy, scipy,matplotlib等科学计算常用package,当然也包含scikit-learn包)
anaconda下载地址:www.continuum.io/downloads
anaconda安装注意问题:匹配的Python解释器版本(2.7 or 3.5), 系统版本(32位or64位)
4、安装Graphviz(数据可视化软件)
下载地址:www.graphviz.org
安装完成后,将C:\Program Files (x86)\Graphviz2.38\bin(找你的graphviz/bin的路径)加入到系统变量path中
5、决策树算法实现
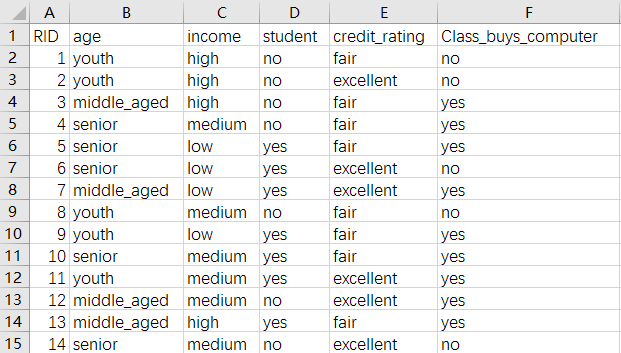
5.1、将原始数据录入csv文件中(如下图)
5.2、引入sk-learn相关的package

5.3、读取csv文件的数据到程序中

5.3、对数据预处理
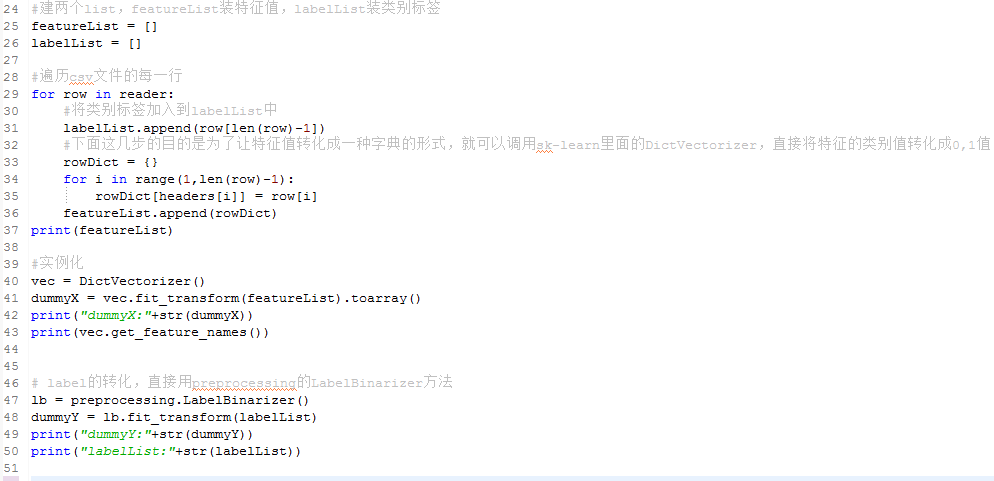
5.4、决策树分类的核心代码

5.5、生成dot文件(结果不够直观)

dot文件:

5.6、将dot文件用graphviz转换为pdf文件
在命令行下,cd到你的dot文件的路径下,输入
dot -Tpdf filename.dot -o output.pdf
(filename以dot文件名为准)
可以看见同路径下生成了一个pdf文件
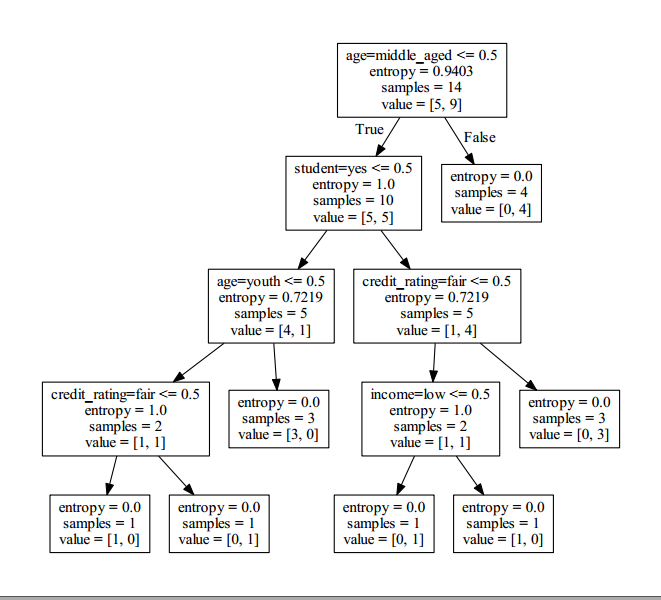
如图:
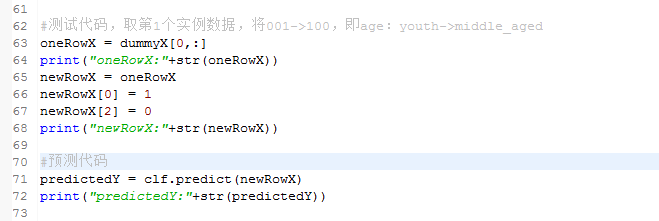
5.7、测试代码
5.8、源程序
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
5.9、sk-learn的决策树文档
地址:scikit-learn.org/stable/modules/tree.html
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









