







当我们设计复杂系统时,生产环境系统的可观察性是必须的,期望通过观察告诉我们什么时候,哪里出现了问题。
- 平时了解服务运行状况。
- 异常时,可发现服务故障,并定位故障原因。
- 事后,对异常点做分析,看是否在高峰期发生,或者持续更久,是否会出事故,如何解决。
运维黄金指标
观察那些指标,按照《SRE:Google运维解密》中描述的, 监控的四个黄金指标如后: 延迟、流量、错误、饱和度。
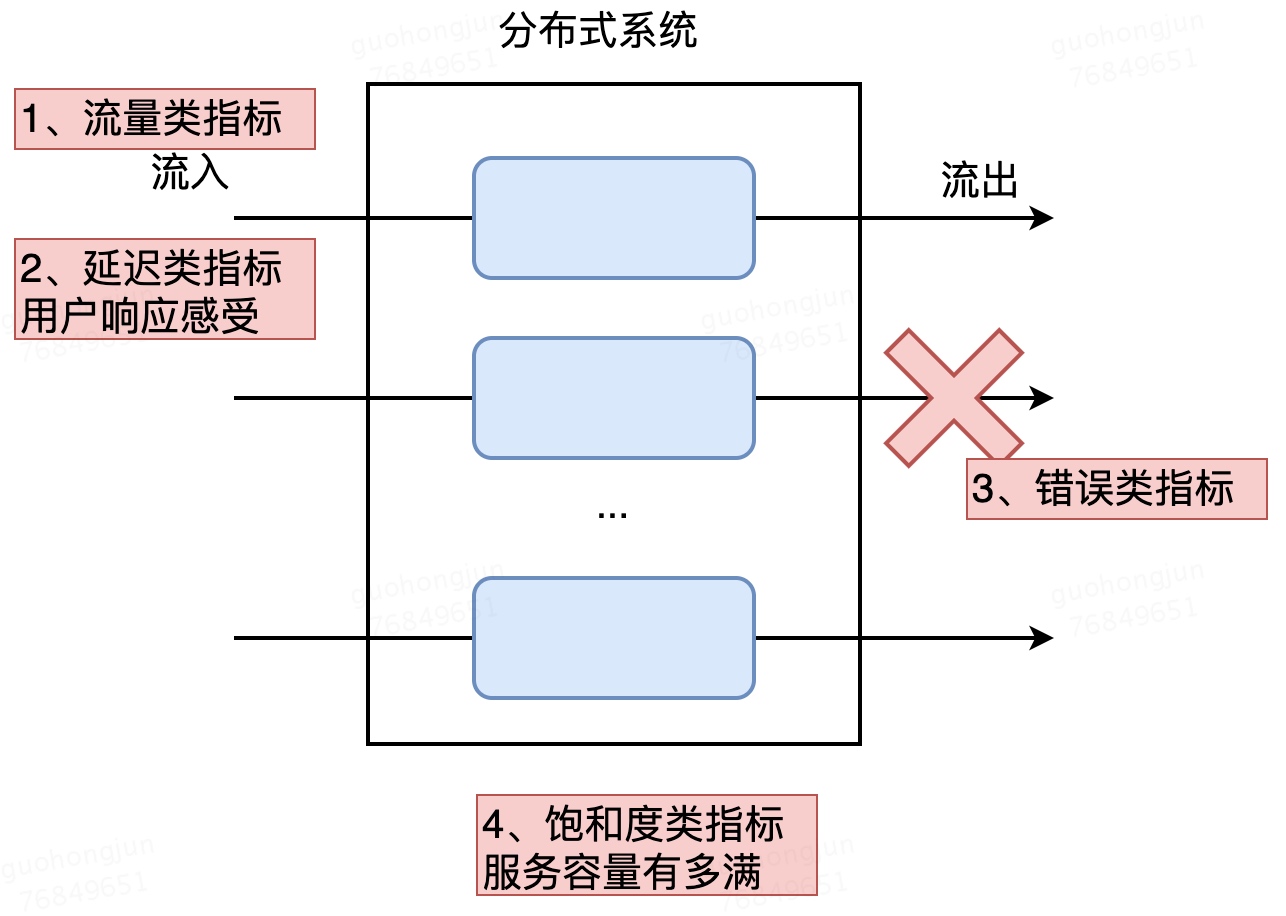
四类运维监控指标的监控项
这四类监控指标,在具体的业务和基础设施、中间件场景,要监控的项各有不同:
| 基础设施 | 业务监控 | |
|---|---|---|
| 错误类 |
|
|
| 延迟类 |
|
|
| 流量类 |
|
|
| 饱和度类 |
|
|
参看: 京东 运维监控的终极秘籍,盘它!
这些项的周同比、日环比、突增、历史峰值等都需要关注。在百度做AIOPS时,还有些相关算法经验。
- 流量类:流入系统的请求数量(百度是如何做智能流量异常检测)、泊松分布。
- 错误类: 还记得概率课本中的二项分布吗?在我们的网络判障中发挥了大作用!、二项分布 。
- 延迟类: 高斯核密度估计
- 饱和度 : Beta分布核密度
参看 百度的经验 3分钟了解黄金指标异常检测, PPT 百度智能异常检测实践 王博、 演讲:百度 AIOps 黄金指标异常检测技术实践
MECE
MECE是 Mutually Exclusive Collectively Exhaustive 的首字母简写。
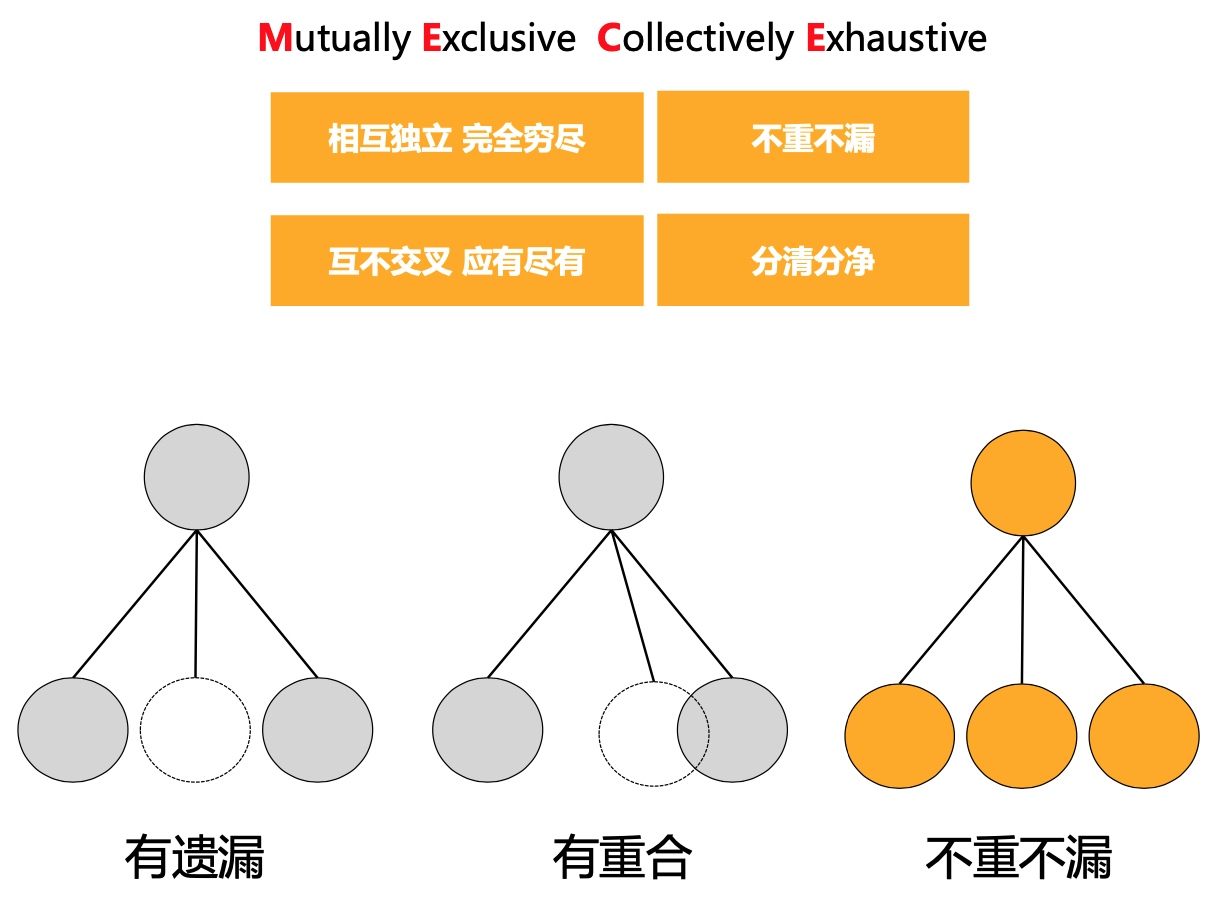
四类黄金指标是否MECE?
这四类指标是否宏观的就完全穷尽了呢?
我们看下面的思维导图:
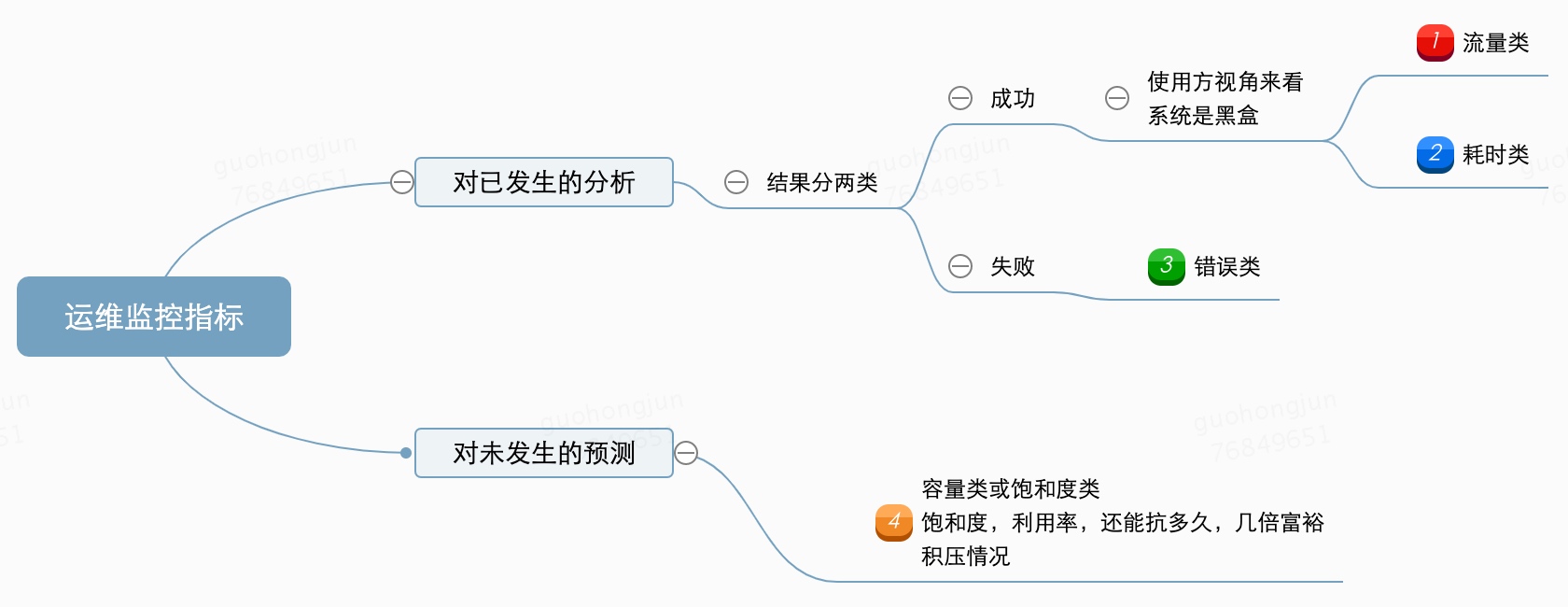
关于监控哪些指标,以及为什么要从系统化的角度出发,我们进行过深入的思考。本文中,我们想与大家分享一些具体的指标和准则,进一步帮助团队衡量并提高运维性能。以下整理了4个关键性运维指标:
告警事件数量
如果团队中的事件数量呈现上升趋势,那么很有可能是哪里出了问题:要么是基础设施有故障,要么是监控工具配置错误需要调整。
随着公司的发展,组织结构会调整,同时业务产品也会不断升级,配套监控也会同步上线,告警事件数量会急剧增加。「我们浪费了大量时间来关闭冗余报警。」--相信很多同学都会有类似的体会。告警事件数量是可控的:
- 告警数量可统计,如这周告警数量是多少,与新发布的产品系统有没有关系,发生哪些问题?
- 告警数量是可操作的,意味着每一个告警都是有意义并且是需要处理和操作的,如果仅仅是瞅一眼的数据,请不要通过告警方式。例如100+机器时,每台机器的「CPU 使用率高」告警是没有啥用的,你知道机器 CPU 使用率高后,你能做什么操作呢?你可能直接忽略掉,当数量大到你把需要处理的告警也忽略掉时,告警就失去了意义。类似指标完全可以通过周报/日报进行数据的性能分析,而不是告警。
平均解决事件( MTTR )
解决时间是衡量业务准备的最佳标准。当事件发生时,你的团队需要多长时间才能解决?
宕机不仅会影响你的收入,还会伤害客户用户体验和忠诚度,所以确保团队对所有事件可以快速响应极为关键。
- 全球500强企业平均每周出现严重故障时间长达1.6小时。
- 平均每小时折合损失$96,000。
当然,跟踪解决时间固然重要,但对其进行规范往往很难,企业可以根据环境的复杂性、团队和基础设施的责任制、行业及其他因素,进一步观测 MTTR 的差异。但是,规范化的操作手册、自动化的基础设施管理、可靠的告警升级策略都有助于减少事件,和提升 MTTR。
优秀的团队减少事件数量,并及时解决( MTTR ),所以平均解决事件需要和上面告警数量一样,需要记录和统计分析,目前大多监控工具往往不具备类似能力,如果没有精力或者资源自行开发的话,我们就建议使用第三方平台OneAlert 。
有关如何减少事件数量,避免告警疲劳的事情,后续将会有独立文章进行发布。
平均响应时间( MTTA )
如果说平均解决时间是结果,那么平均响应时间就是重要的过程指标,这一点往往被大多团队忽略掉。可以理解为告警越快发现,越快有人响应,就能够越快的解决(更好的MTTR)。
提升 MTTA 的核心是找对人、找到人。上图中如果02:01能够及时通知到位就可以节省至少4个小时时间。
说起来简单,实际上找对人有些工作(只1人运维的请忽略),一般是从职责责任制、协调机制、工作进程透明、工作量和时间可衡量等几点进行,后面针对「有序分派」再补充一篇。
除了以上机制,还有一点,就是需要记录谁什么时候确认响应告警,并做了哪些处理,能够持续跟踪,以及统计分析。
响应时间非常重要,因为它能帮助你了解哪些团队和个人处于随叫随到的状态。快速响应时间是一个战备文化的代表,你会发现具备快响应观念和工具的团队往往可以更快地修复事件。
如果使用像 OneAlert 的事件管理系统,[升级超时]有助于推进响应目标。例如,如果你希望所有事件都应该在5分钟内回复,可以将超时设置为5分钟,从而确保下一个接收人会收到提醒。再根据团队的整体表现,来决定是否需要调整目标,然后再跟踪升级事件的数量。
升级
对于大多数使用事件管理工具的组织而言,告警升级是一种异常现象,该迹象表明首次应该响应的时候,无法及时应对事件,或许相关工具和人员技能失效。升级策略是事件管理的必须,各个团队应努力推动升级,实现升级事件数量的下降。
优秀的运维团队需要建立起有效的一线、二线、甚至三线响应机制,告警及时通知到一线,如果一线没有及时处理,可以自动升级至二线运维,保障每一个重要事件能够得到及时响应和处理。
有些情况下,升级是标准作业实践的一部分。例如,你可能有一个 NOC,一线支持团队或者自动修复工具,可根据内容来升级或分诊输入事件。这种情况下,一线更多像一个路由转发器,可以通过人工+工具自动化方式实现。
示例分析
这是某个团队一个月的告警数据剖析:
-
告警数量在11-18前相对稳健,平均在3-5个告警。第3周告警突飞猛进,原因是新的业务上线,引发突增。经过周回顾,优化监控策略,在第4周经过初步优化,告警数量有所降低,运维团队工作初见成效,还需要继续优化。
-
告警响应时间 MTTA ,基本上都能够比较好的响应,基本在5分钟内响应。说明整个团队的响应及时率是不错的。同时也看到在第3、4周六的时候,明显的响应时间延迟较大,说明一个问题,周末的支撑工作有提升空间。
-
恢复时间 MTTR ,基本保持在20分钟左右,说明恢复比较及时,但是也有可能存在事件无需关注,自动恢复。后者需要针对事件的类型、根源进一步分析,后续文章再剖析。
-
升级,目前该团队基本上是5分钟升级,所以会看到在大部分问题能在5分钟内响应完成。
小结
致力减少告警数量、及时响应 MTTA 、如果不能及时响应,能够升级处理,最终提升解决时间 MTTR,4个核心关键指标是运维支撑工作非常关键的指标。
运维是结合管理流程、工具、人员三方面的综合化工作,期望构建一个告警平台,能够帮助运维同学更有效率的完成支撑工作。
转自:https://www.cnblogs.com/ghj1976/p/fen-bu-shi-xi-tong-yun-wei-si-ge-huang-jin-zhi-bia.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









