




目录
引言
其实这部分并不属于ComfyUI的部分,但是你也看到了Flux 下的LORA是非常重要的。你可能想训练一个自己的LORA,其实Lora的原理,在 https://blog.csdn.net/talentyiyy/article/details/154440949?spm=1011.2124.3001.6209 讲的比较清楚了,就是Matrix (M1*N1) * Matrix(N1*M2) 后,适当调小 N1, 可以降低 Matrix(M1M2)的训练量。从数学理解的角度,你要先把他拿下,我在这里就不在过多阐述了。今天主要讲下 训练自己的Lora 的核心概念和知识点。下一节开始实操。
数据集,训练的基石
巧妇难为无米之炊。数据集,作为训练的材料,肯定是最重要的。
数据集规模与训练策略
数据集规模直接影响模型的训练效果和训练时间。大规模数据集需要更长的训练时间和更高的算力支持,但通常能训练出性能更好的模型。例如,使用百万级数据集训练一个深度学习模型,可能需要数天甚至数周的时间,但模型的准确率和鲁棒性会更强,对于小数据集,除了增加循环轮次外,还可以采用数据增强等技术来扩充数据集,提高模型的泛化能力。数据增强通过旋转、裁剪、翻转等操作生成新的训练样本,使模型能够学习到更多的变化情况。
循环轮次与训练效果
在训练集较少的情况下,增加循环轮次(epoch)可以让模型有更多机会学习数据中的特征,从而提高模型的性能。例如,对于一个小型数据集,将循环轮次从10增加到50,模型的准确率可能会显著提升,因为模型有更多次的机会调整权重以更好地拟合数据。
但循环轮次并非越多越好,过高的轮次可能导致过拟合,即模型在训练数据上表现很好,但在新的数据上性能下降。因此,需要根据模型在验证集上的表现来调整循环轮次,找到最佳的平衡点。
图片质量对泛化能力的影响
高质量图片包含更丰富的细节和特征,能够使模型学习到更多元化的信息,从而提高模型对不同场景和风格的适应能力,增强泛化能力。例如,在训练一个图像分类模型时,使用高清且多样化的图片数据集,模型在面对新的、未见过的图片时,也能更准确地进行分类。图片种类的丰富性同样重要,不同种类的图片涵盖了各种场景、风格和对象,有助于模型学习到更广泛的特征分布,避免因数据单一导致的模型偏差,进一步提升模型的泛化性能。
算法与优化器
介绍
Adamw8bi优化器结合了动量优化和权重衰减等技术,能够有效加速模型收敛并提高训练稳定性。它通过自适应调整学习率,根据参数的梯度历史动态调整每个参数的学习率,使模型在训练初期能够快速收敛,同时在训练后期避免过拟合。
Lion优化器则在某些特定场景下表现出色,具有更好的优化性能和收敛速度。它通过引入动量项和自适应学习率调整机制,能够在复杂的优化问题中找到更优的解,尤其适合训练深度神经网络。
优化器的适用场景
Adamw8bi优化器适用于大多数深度学习任务,尤其是需要快速收敛和稳定训练的场景。它在图像分类、目标检测和自然语言处理等领域都有广泛的应用,能够有效提高模型的训练效率和性能。
Lion优化器则更适合于训练大规模的深度神经网络,尤其是在需要处理复杂数据和优化问题时。例如,在训练Transformer模型时,Lion优化器能够更好地处理模型中的高维度参数和复杂的优化问题,提高模明川练效果。
例如,在训练一个图像生成模型时,使用Adamw8bi优化器可能使模型在较短时间内达到较高的生成质量,而使用Lion优化器可能在更复杂的场景下表现更好。
优化器的选择还应根据具体的任务和模型结构进行调整。对于简单的线性模型,SGD(随机梯度下降)优化器可能已经足够:而对于复杂的深度学习模型Adamw8bi或Lion等优化器则更为适用。
参数调优
学习率
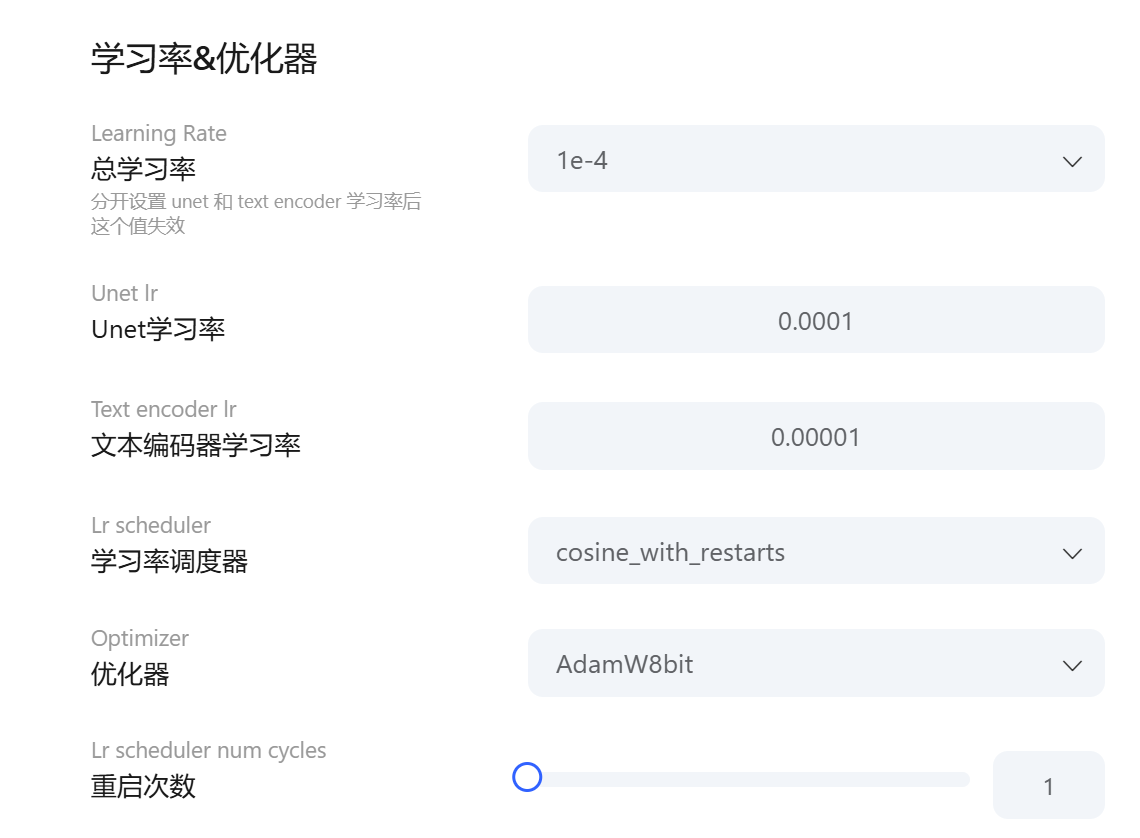
学习率是机器学习算法中的关键参数,用于控制模型在每次迭代更新时对于权重和位置的调整程度。学习率较大时,每一步更新的幅度会比较大,模型可能会更快地收敛得到最优解,但容易错过最优解附近的小波动,甚至发生震荡或无法收敛的情况。相反,如果学习率较小,每一步的变化会比较小,模型的调整过程会相对稳定,但可能需要更多的迭代次数才能收敛到最优解,训练速度可能会变慢。因此,合理设置学习率对于模型的训练效果至关重要。
学习率数值表示与理解
1e-4是一种程序里的数学表达,实际上就是1除以10的4次方,即1e-4=1110000=0.0001;1e-5=1100000=0.00001。这种科学计数法在设置学习率时常用,便于精确表示较小数值,方便调整模型训练过程中的权重更新幅度,以达到理想的训练效果。在实际应用中,学习率的设置需要根据具体的任务和模型结构
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4913
4913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











