







sklearn函数CountVectorizer()和TfidfVectorizer()计算方法介绍
CountVectorizer()函数
CountVectorizer()函数只考虑每个单词出现的频率;然后构成一个特征矩阵,每一行表示一个训练文本的词频统计结果。其思想是,先根据所有训练文本,不考虑其出现顺序,只将训练文本中每个出现过的词汇单独视为一列特征,构成一个词汇表(vocabulary list),该方法又称为词袋法(Bag of Words)。
举一个栗子:
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
texts=["orange banana apple grape","banana apple apple","grape", 'orange apple']
cv = CountVectorizer()
cv_fit=cv.fit_transform(texts)
print(cv.vocabulary_)
print(cv_fit)
print(cv_fit.toarray())
输出如下:
{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
#这里是根据首字母顺序,将texts变量中所有单词进行排序,apple首字母为a所以排第一,banana首字母为b所以排第二
(0, 3) 1
(0, 1) 1
(0, 0) 1
(0, 2) 1 # (0, 2) 1 中0表示第一个字符串"orange banana apple grape",2对应上面的'grape': 2, 1表示出现次数1。
(1, 1) 1
(1, 0) 2
(2, 2) 1
(3, 3) 1
(3, 0) 1
[[1 1 1 1] # 第一个字符串,排名0,1,2,3词汇(apple,banana,grape,orange)出现的频率都为1
[2 1 0 0] #第二个字符串,排名0,1,2,3词汇(apple,banana,grape,orange)出现的频率为2,1,00
[0 0 1 0]
[1 0 0 1]]
TfidfVectorizer()函数
TfidfVectorizer()基于TF-IDF算法。此算法包括两部分TF和IDF,两者相乘得到TF-IDF算法。
TF算法统计某训练文本中,某个词的出现次数,计算公式如下:
![![TF算法]](https://img-blog.csdnimg.cn/20200227003501980.png)
IDF 算法,用于调整词频的权重系数,如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。
注意sklearn中idf的计算公式与一般书中介绍的不一样,当TfidfVectorizer 的参数use_idf(参数默认值为True)为True时就是按照如下算法来计算IDF。
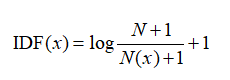
N=训练集文本总数, N(x)=包含词x的文本数
TF-IDF算法=TF算法 * IDF算法
我们依旧采用上面的例子:
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
texts=["orange banana apple grape","banana apple apple","grape", 'orange apple']
cv = TfidfVectorizer(norm=None)
cv_fit=cv.fit_transform(texts)
print('特征向量')
#print(sorted(cv.vocabulary_))
print(cv.vocabulary_)
print('IDF值')
print(cv.idf_)
print('TF文档-词矩阵')
print([[1,1,1,1],
[2,1,0,0],
[0,0,1,0],
[1,0,0,1]])
print('TF-IDF文档-词矩阵')
print(cv_fit.toarray())
print(cv_fit)
输出如下:
特征向量
{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
IDF值
[1.22314355 1.51082562 1.51082562 1.51082562]
IDF(orange)=np.log((4+1)/(2+1))+1=1.5108256237659907
训练集文本总数4, 包含词orange的文本数2
TF文档-词矩阵
[[1, 1, 1, 1],
[2, 1, 0, 0],
[0, 0, 1, 0],
[1, 0, 0, 1]]
TF-IDF文档-词矩阵
[[1.22314355 1.51082562 1.51082562 1.51082562]
[2.4462871 1.51082562 0. 0. ]
[0. 0. 1.51082562 0. ]
[1.22314355 0. 0. 1.51082562]]
(0, 2) 1.5108256237659907
(0, 0) 1.2231435513142097
(0, 1) 1.5108256237659907
(0, 3) 1.5108256237659907
(1, 0) 2.4462871026284194
(1, 1) 1.5108256237659907
(2, 2) 1.5108256237659907
(3, 0) 1.2231435513142097
(3, 3) 1.5108256237659907
norm='l2’范数时,就是对文本向量进行归一化
TfidfVectorizer参数norm默认值为‘L2’范数
cv = TfidfVectorizer()
cv_fit=cv.fit_transform(texts)
print(cv.vocabulary_)
print(cv.idf_)
print(cv_fit.toarray())
print(cv_fit)
输出如下:
{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
[1.22314355 1.51082562 1.51082562 1.51082562]
[[0.42344193 0.52303503 0.52303503 0.52303503]
[0.8508161 0.52546357 0. 0. ]
[0. 0. 1. 0. ]
[0.62922751 0. 0. 0.77722116]]
(0, 2) 0.5230350301866413
(0, 0) 0.423441934145613
(0, 1) 0.5230350301866413
(0, 3) 0.5230350301866413
(1, 0) 0.8508160982744233
(1, 1) 0.5254635733493682
(2, 2) 1.0
(3, 0) 0.6292275146695526
(3, 3) 0.7772211620785797
取 IDF值的L2范数即可得上面的数据:
a=np.array([1.22314355 ,1.51082562, 1.51082562, 1.51082562])
a*(1.0/np.sqrt(math.pow(1.22314355,2)+math.pow(1.51082562,2)*3.0))
输出:
array([0.42344193, 0.52303503, 0.52303503, 0.52303503])














 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









