







前言
车辆保险线上化营销是目前保险公司对老客户的主要营销方式之一,主要是基于老客户的承保信息数据对老客户进行拜访、电话外呼等。但是对于一个分公司级别的老客户源,在做营销方式决策前,必须对老客户进行价值细分,根据不同价值能量的老客户采取不同的营销手段,以使得单位营销成本利益最大化。
本文是利用时下最流行的Python语言,基于RFM模型对客户进行细分,使决策者不用再做更多的分析调研,即可对客户价值一目了然。鉴于商业保密原则,本文采用了某公司较旧的一整年全部车险承保信息数据,关键信息进行了回避。RFM模型价值高低界定也是笔者独自衡量,不代表任何官方观点。
先附上一张分析后的结果图:
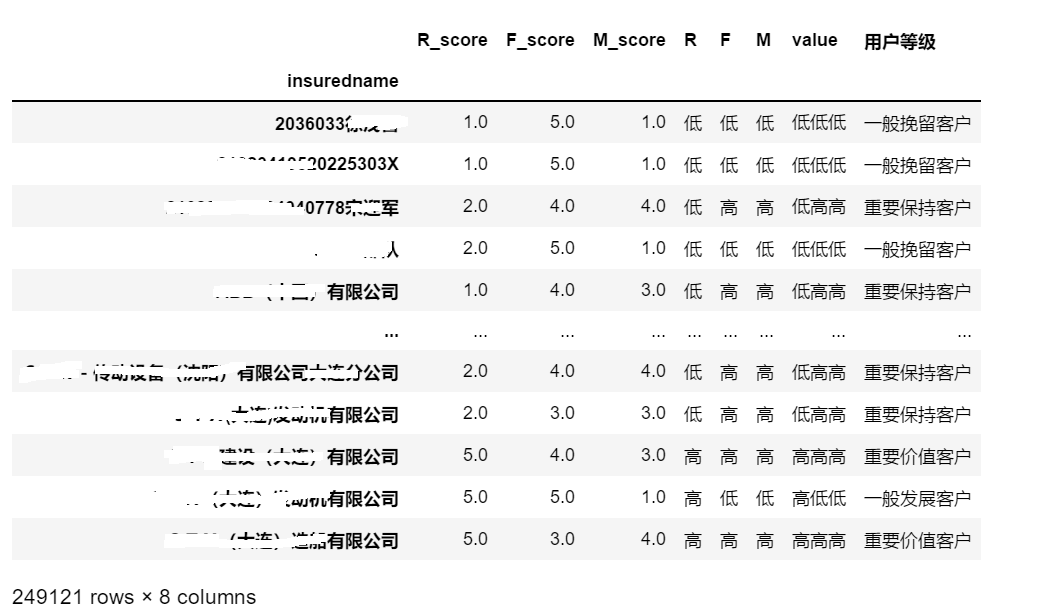
一、引入数据
1、导入python基础库,切换到原始数据目录,查看文件。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly as py
import plotly.graph_objs as go
pyplot=py.offline.iplot
py.offline.init_notebook_mode()
import os
import warnings
warnings.filterwarnings('ignore')
os.getcwd()
file_dir="2017"
all_csv_list=os.listdir(file_dir)
all_csv_list2、运行后,如下图,可看到事先从数据库中提取的2017年1-12月份的车险承保数据

3、合并12个文件的数据到一个数据框中
for single_csv in all_csv_list:
single_data_frame=pd.read_csv(os.path.join(file_dir,single_csv),encoding='utf-8',error_bad_lines=False)
if single_csv == all_csv_list[0]:
all_data_frame = single_data_frame
else:
all_data_frame = pd.concat([all_data_frame, single_data_frame], ignore_index=True)4、查看数据框信息
all_data_frame.info()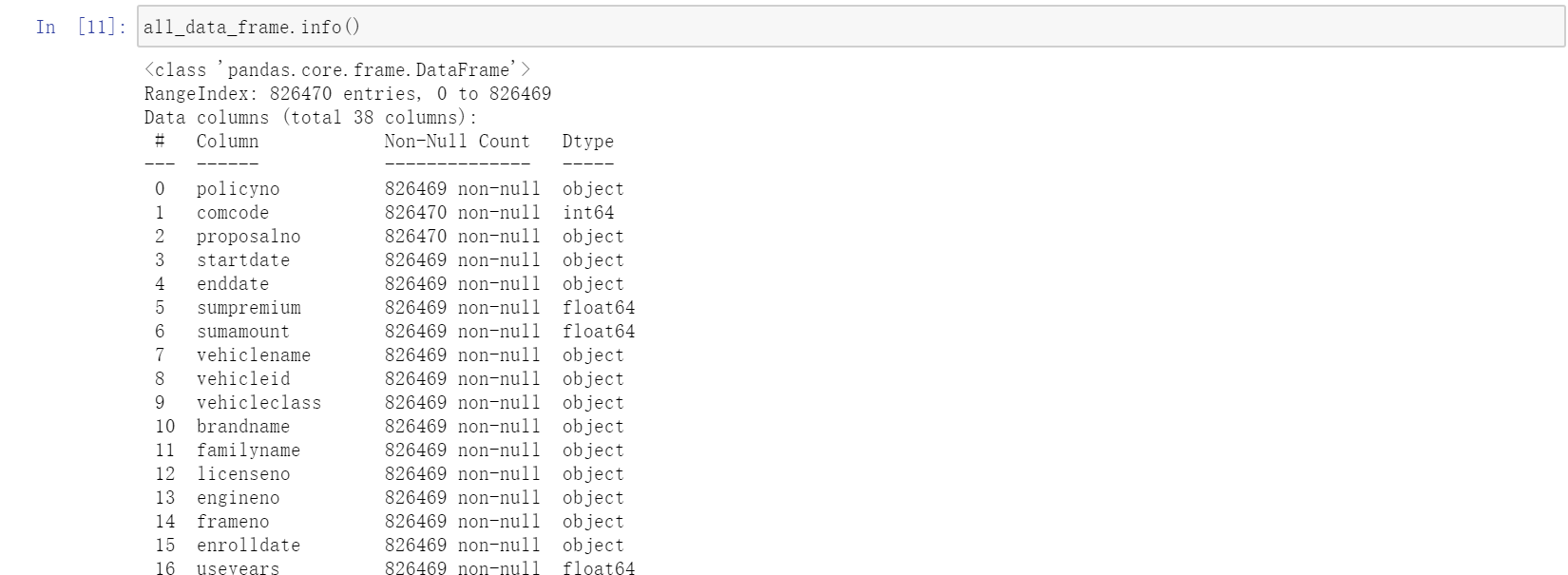
二、数据清洗
数据存在的问题:
1、上一章最后一张图中可以看到,该样本数据共有826470行,policyno保单号共有826469行,说明数据里有空值数据。
2、起保时间startdate的类型是object,应转变为时间类型,因为需要使用RFM模型,需要添加年、月、日列。
3、数据一共有38个字段,即38列,真正用于分析的字段就几列,需要剥离出来。
4、尚不知道是否有重复行,需要做去重处理。
清洗过程如下:
all_data_frame['insuredname']=all_data_frame['insuredname'].fillna('U')#insuredname为空就添加U
all_data_frame.dropna(subset=['policyno'],how='all',axis=0,inplace=True) #policyno为空就删除
all_data_frame['year']=[x.split('-')[0] for x in all_data_frame['startdate']] #增添年月日三列
all_data_frame['month']=[x.split('-')[1] for x in all_data_frame['startdate']]
all_data_frame['day']=[x.split('-')[2] for x in all_data_frame['startdate']]
all_data_frame=all_data_frame.drop_duplicates() #删除重复数据
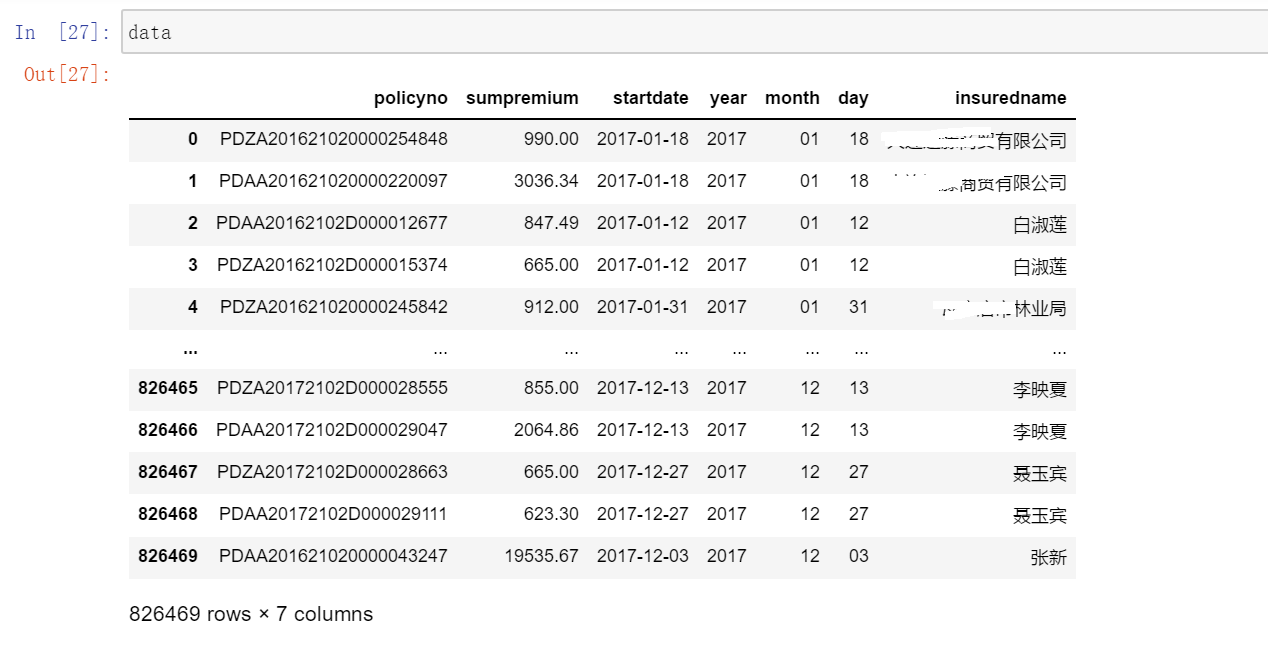
data=all_data_frame[['policyno','sumpremium','startdate','year','month','day','insuredname']] #抽取分析所用的字段清洗后最终数据预览图如下:
三、数据分析
RFM模型:
Recency:最近一次消费时间,简称R,通常最近一次消费时间离现在越小,说明客户价值越高。
Frequency:消费频率,简称F,通常F值越大,说明客户价值越高。
Monetary:消费金额,简称M,通常M值越大,说明客户价值越高。
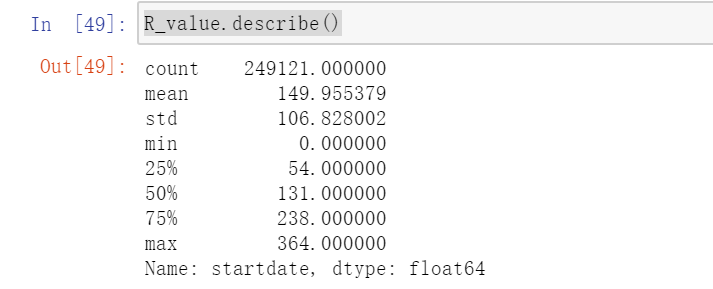
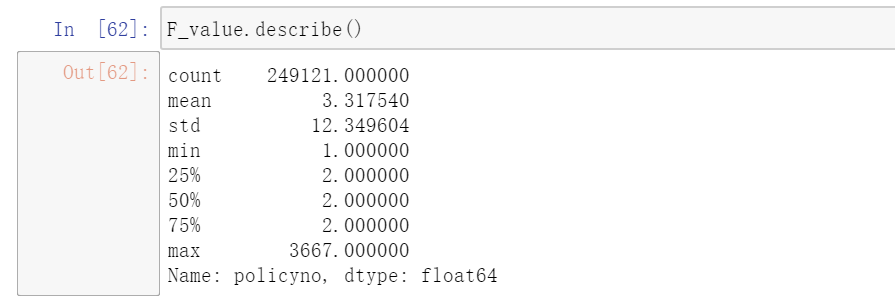
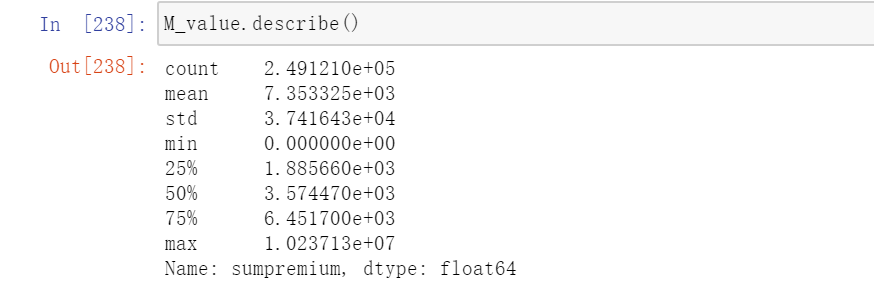
1、计算本文样本数据中R、F、M的value值。
R_value=data['startdate'].max()-R_value
R_value=R_value.dt.days #消费时间与样本最后消费时间之差
F_value=data.groupby('insuredname')['policyno'].nunique() #消费频次
M_value=data.groupby('insuredname')['sumpremium'].sum() #消费总金额2、查看三个value值的总体情况
3、根据上述的均值、最大最小值等情况,跟三个指标进行分段。
R_bins=[0,60,110,190,270,365]
F_bins=[1,2,3,4,5,3668]
M_bins=[0,1800,4000,5800,10000,1100000]4、根据分段结果对数据做打分处理
R_score=pd.cut(R_value,R_bins,labels=[5,4,3,2,1],right=False) #值越大说明间隔时间越小 客户价值越高
F_score=pd.cut(F_value,F_bins,labels=[1,2,3,4,5],right=False) #值越小说明消费频次越高 客户越有价值
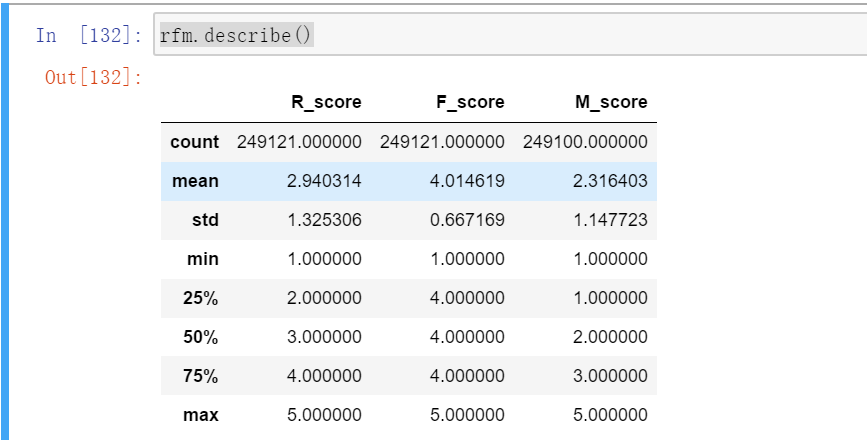
M_score=pd.cut(M_value,M_bins,labels=[1,2,3,4,5],right=False) #值越大说明消费金额越大 客户价值越高5、查看三个指标评分结果
for i in['R_score','F_score','M_score']:
rfm[i]=rfm[i].astype(float)
rfm.describe()可以看到,R、F、M三个指标的平均分分别为2.94、4.01、2.32 。
6、设定分项评价标准
rfm['R']=np.where(rfm['R_score']>2.94,'高','低') #R值高于平均值2.94的为高价值客户
rfm['F']=np.where(rfm['F_score']<4.01,'高','低') #F值小于平均值4.01的为高价值客户
rfm['M']=np.where(rfm['M_score']>2.31,'高','低') #M值高于平均值2.31的为高价值客户7、合并分项评价标准字段
rfm['value']=rfm['R'].str[:]+rfm['F'].str[:]+rfm['M'].str[:] 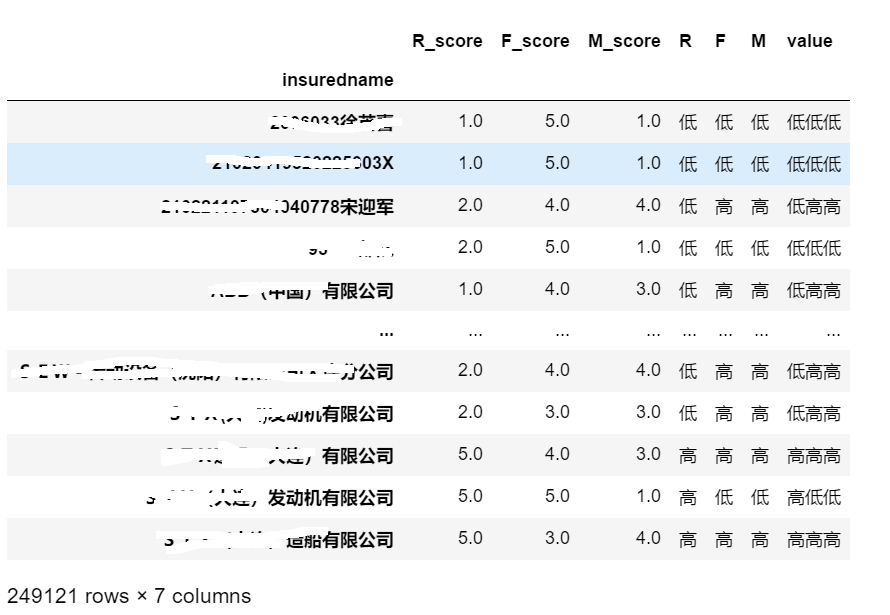
8、定义函数,定义用户等级标准
rfm['value']=rfm['value'].str.strip() #左右两边去空格
def trans_value(x):
if x=='高高高':
return '重要价值客户'
elif x=='高低高':
return '重要发展客户'
elif x=='低高高':
return '重要保持客户'
elif x=='低低高':
return '重要挽留客户'
elif x=='高高低':
return '一般价值客户'
elif x=='高低低':
return '一般发展客户'
elif x=='低高低':
return '一般保持客户'
else:
return '一般挽留客户'9、查看详细表格及文字结果
rfm['用户等级']=rfm['value'].apply(trans_value)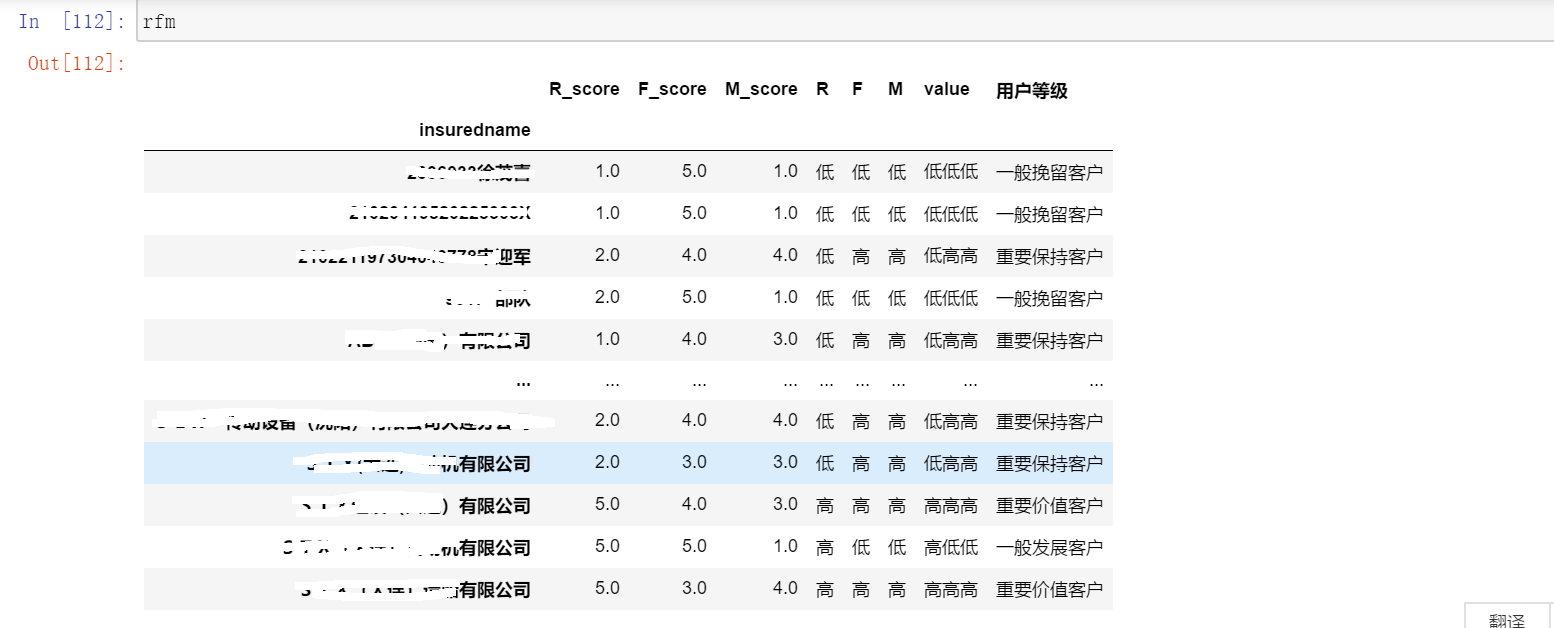
rfm['用户等级'].value_counts()
一般价值客户 83022
一般保持客户 55514
重要价值客户 52309
重要保持客户 33347
重要发展客户 23315
重要挽留客户 1360
一般发展客户 236
一般挽留客户 18
四、数据可视化
1、做柱形图
trace_basic=[go.Bar(x=rfm['用户等级'].value_counts().index,
y=rfm['用户等级'].value_counts().values,
marker=dict(color='orange'),opacity=0.50)]
layout=go.Layout(title='用户等级情况',xaxis=dict(title='用户重要度'))
figure_basic=go.Figure(data=trace_basic,layout=layout)
pyplot(figure_basic)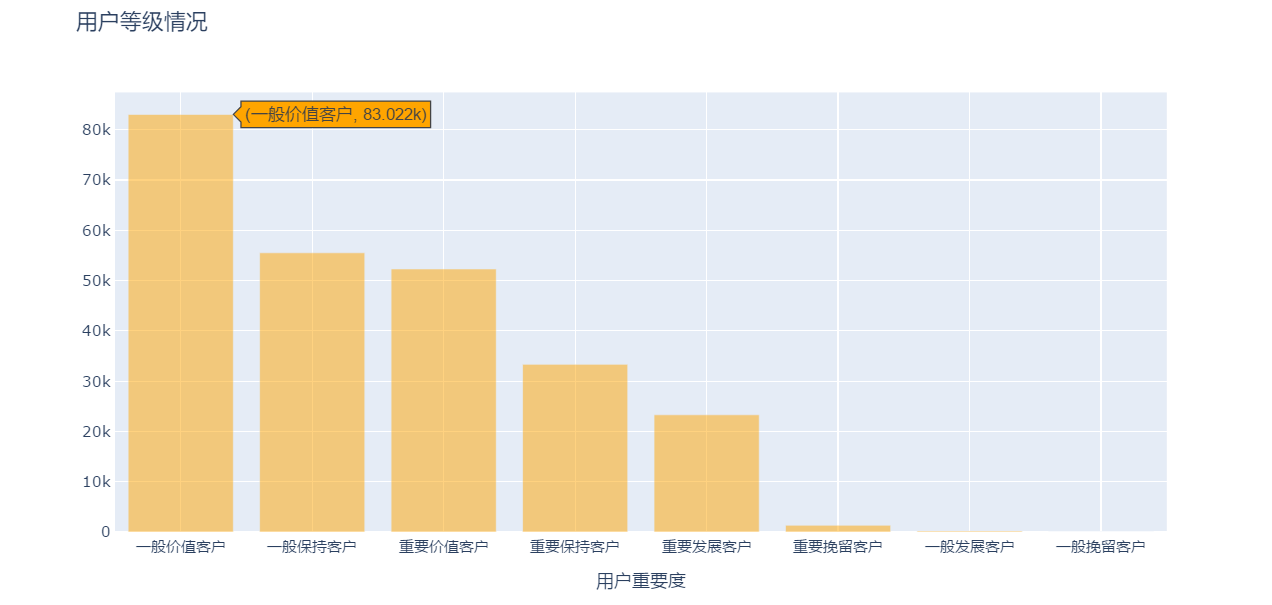
2、饼状图
trace=[go.Pie(labels=rfm['用户等级'].value_counts().index,
values=rfm['用户等级'].value_counts().values,
textfont=dict(size=12,color='white'))]
layout=go.Layout(title='用户等级比例')
figure_basic=go.Figure(data=trace,layout=layout)
pyplot(figure_basic)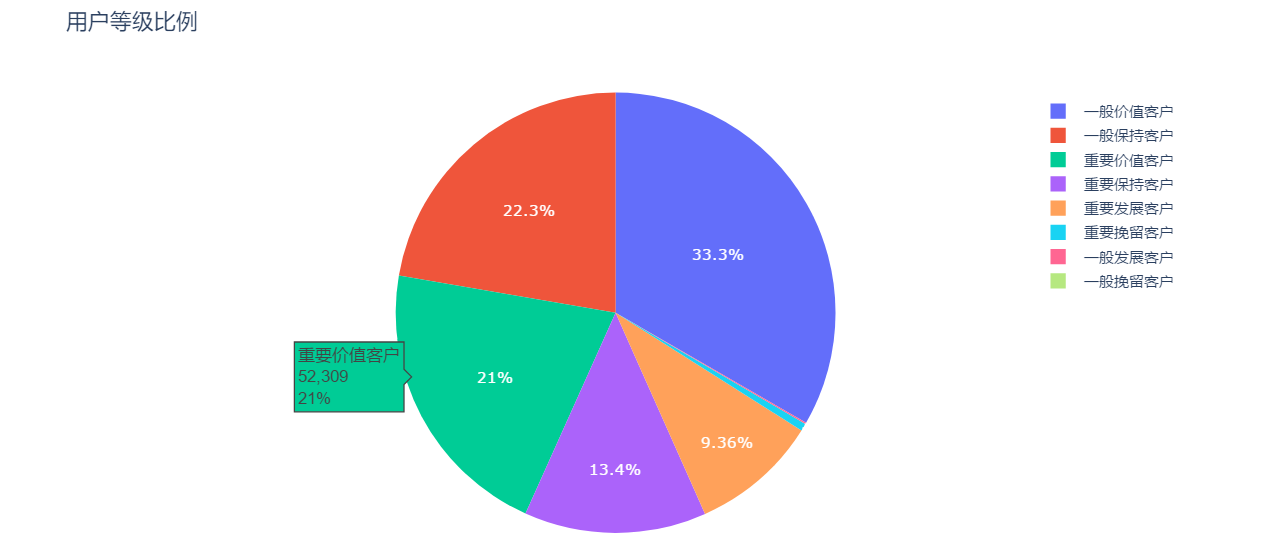
五、结论
根据笔者的价值分类模式的打分标准可得结论如下:
1、该公司重要价值客户+重要保持客户+重要发展客户占比约43%,这些是跟公司创造价值的主力军,公司可考虑提供附加增值服务。
2、该公司一般保持客户+一般价值客户占比约55%,这类客户数量庞大,但创造价值能力一般,可在1中的客户价值挖掘后,对该类客户做进一步的客户画像获取,实施精准营销。
3、该公司还有0.54%共计1360名重要挽留客户,这类客户创造的价值较大,数量较少,可集中销售精英对这类客户进行短时间集中营销。
通过对客户价值细分,我们可以对不同层级的客户采取不同的营销手段,但由于各种客观因素(地区差、决策者喜好、政策变化)的影响,文中价值分类原则和打分标准会千变万化,这里只是做个个性化展示。














 3685
3685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









