










kafka是一个分布式的消息队列由scala编写,不同于传统的一些消息队列,kafka的设计理念与众不同。
1、kafka的特点
。快速
单台kafka的broker实例能够支撑几千台机器每秒几百兆字节的读写,如果组成集群性能会更强进,从很多人的测试情况来看kafka的读写性能表现不输于当前流行的消息队,甚至领先很多。
。扩展性
弹性透明的扩展,不需要停机,kafka的数据是分区的,可以分布在不同的server中,允许消费者并发的访问。
。持久化
集群中的数据被持久化在磁盘上,以防止数据丢失。
。分布式
kafka基于cluster-centric理念设计,有很好的容错性。
2、kafka集群架构
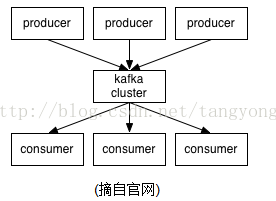
要熟悉kafka首先要了解一下kafka中的几个角色
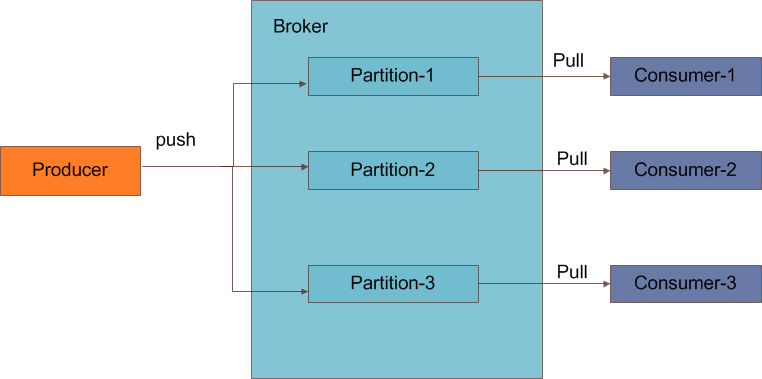
Broker——上图中间kafka cluster的部分便是由多个Broker组成,每个Broker代表kafka的一个实例。
Producer——producer作为整个消息系统的输入部分,直接通过socket和Broker连接发布消息。
Consumer——consumer作为消息的消费者负责处理消息
无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性,zookeeper集群保存一些meta信息。
毋庸置疑何处理消息是一个消息系统核心的功能,比如生产者如何生产消息、消息怎么存储、消费者如何消费消息、消息的可靠性、重复性等等。
3、Topic
topic是kafka抽象出来的一个概念,一个Topic可以被认为是一类消息,每个topic被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它唯一标记一条消息。同一个partition中的消息是有序的,但是针对整个topic中的所有消息kafka不保证有序,这是因为每个partition只允许一个group中的一个consumer消费。
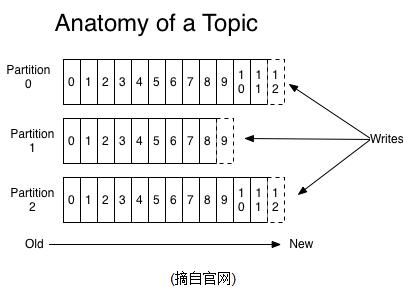
4、kafka设计理念
本小结主要涉及到一些kafka的设计理念,试图从容错性、吞吐量等方面呈现一个比较清晰的kafka视图。
Partition——
kafka中partition的概念非常的巧妙,在某种程度上消费者能够并发的消费消息就是因为partition的存在。一个Topic可以被想象成一个queue,生产者将消息放入topic中,不同的是topic会被分成若干个partition(个数可配置),每个partition在物理上对应一个commit-log日志文件,每次发布消息都会以append的方式新增log,这是一个顺序写磁盘的过程性能上不会有太大的问题,同时在写日志前可以做buffer批量写磁盘。同一个topic的不同partition会分布在不同的server上从而将访问压力分散开发,同时一个partitioin只允许同一个group中的某个消费者消费,group的概念后面会提到。关于哪个partition存放在哪个server上等一些meta信息全部存储在zookeeper上。
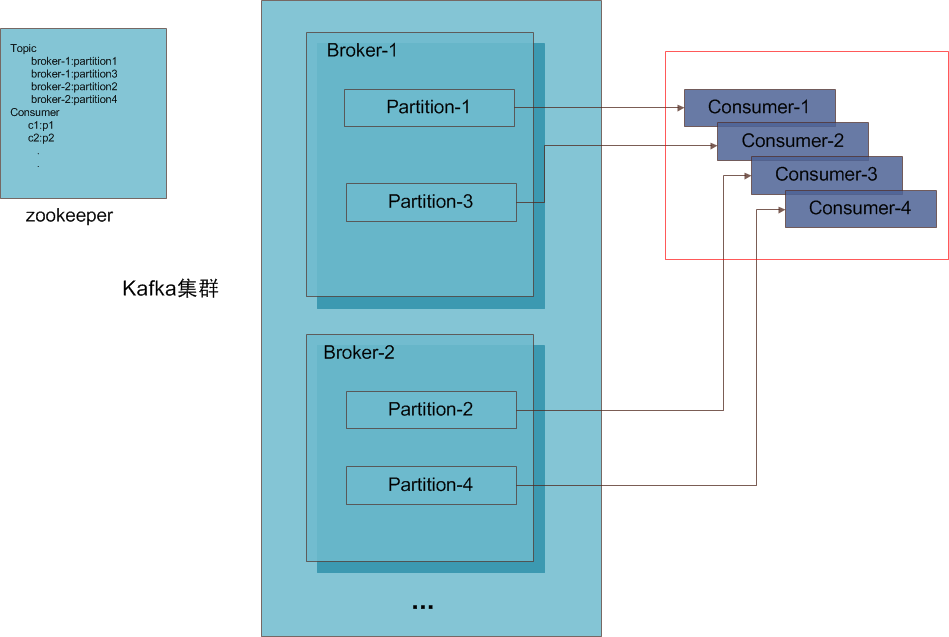
消息存储——
kafka集群会保留所有已经发布过的消息,保存的时间可以通过配置文件指定,比如指定两天,则两天前发布的消息不管是否被消费都将被删除。从另一个角度看kafka允许消费者重复消费两天前的消息,这一点可能和很多消息系统不同,同时由于这个特性使得kafka也适合做离线的大数据分析。详细的存储格式可以去官网了解。
分布式——
为了提高kafka的容错性,kafka支持partition的复制策略,可以通过配置文件配置partition的副本个数,类似zookeeper的复制机制,kafka针对partition的复制同样需要选出一个leader,同时由该leader负责partition的读写操作,其他的副本节点只是负责数据的同步。如果leader失效,那么将会有其他follower来接管(成为新的leader),如果flower数据落后leader太多leader会把该flower剔除。由于leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个leader,kafka会将leader均横的分散在每个实例上,来确保整体的性能稳定。一个kafka集群各个节点间可能互为leader和flower。
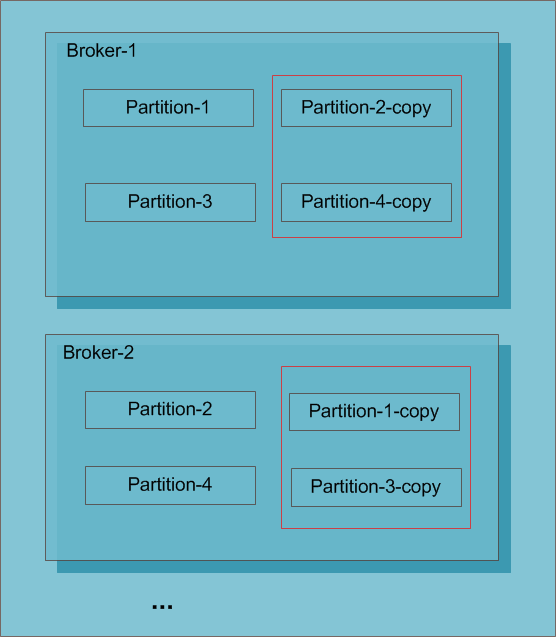
上图中针对partition-2、partition-4,Broker-1是Broker-2的flower,同理针对partition-1、partition-3,Broker-2是Broker-1的flower,这种设计能够最大化的降低节点宕机带来的风险,同时采用选取leader的方式能够降低代码实现的负责度,如果没有leader则需要考虑N*N的复制路径,一方面实现起来复杂另一方面效率也不一定会好。
Push和Pull——
kafka在获取消息方面采用了比较传统的模式,生产者负责push消息,消费者采用pull的方式拉取消息。push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。而在scribe和flume系统中则完全使用的是另外一种模式。
zero-copy——
从kafka设计的特点可以看出网络操作和文件操作非常频繁,为了提高效率,kafka在push或者poll消息的时候通常会分成组也就是先buffer一下再批量的进行操作。与此同时为了更好地效率kafka使用了linux系统提供的senfile系统。在理解sendfile之前有必要了解一下传统的文件操作或者socket是怎么处理的,假设需要把本地磁盘的文件通过socket发送给远端,首先需要read到内存然后通过socket发送,整个过程可以用下面一张图表示:

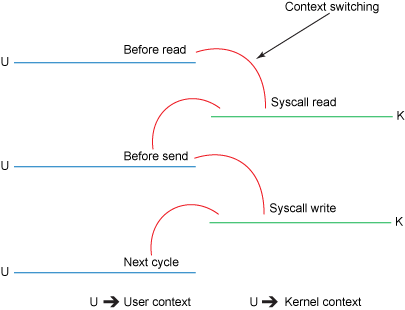
linux系统分为内核态和用户态分别对应上图的kernel context和appliaction context,在这两种形态之间发生切换是很消耗资源的,但是一个发送文件的过程确发生了四次这样的切换,用户态对应应用程序的空间,首先由应用程序发出read请求,切换到内核态,由内核完成数据的读取,然后返回给应用,此时发生两次切换和数据的两次拷贝DMA copy和CPU copy。但这仅仅是发送数据准备的过程,发送的过程同样发生上下文的两次切换和数据的两次拷贝,来来回回发生了很多次的拷贝,zero-copy的出现就是消除不必要的copy动作。java已经提供了类似的api比如FileChannel的transferTo(),类似的api在高性能的通讯框架中应用的很广泛比如Netty。下面两张图描述了早期zero-copy的流程:
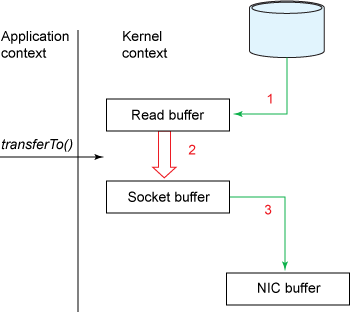
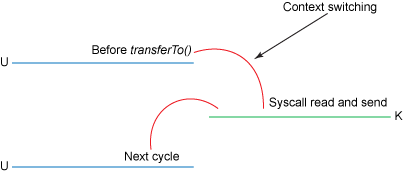
transferTo()方法免去了内核到用户态数据的copy,从而直接将读取到的buffer传输到socket buffer,拷贝过程省去了一次,上下文切换少了两次。但是事情到此还没有结束,后面经过代码的优化数据复制的次数还能减少,只是2.4版本以上的linux才支持,优化后的流程类似下面:

上图内核的操作少了一步,原先需要内核将read buffer的数据传输到socket buffer然后由DMA拷贝到NIC buffer由网卡发送,现在是在read buffer加上一些描述符,从而由DMA直接拷贝read buffer对应的发送数据到NIC buffer,整个拷贝过程减少到了两次,性能大大的提高了。
Producer——
producer负责生产消息,producer会和topic中所有的partition leader保持socket,然后直接将消息发送到对应的broker上,因此消息的负载均衡完全由producer测来负责,默认kafka提供了轮询的方式。kafka中的producer和consumer都是非常轻量级的,因为producer不需要保存客户端消费消息的记录,这些数据由consumer维护,实际上consumer也仅仅维护一个叫做offset的东西。
Consumer——
针对消息系统通常都会有两种模式一种类似Queue,就是消息队列中的消息只会由一个消费者消费,另一种是订阅——发布模式,只要订阅该消息的消费者都会收到广播的消息。Kafka才用了consumer group的概念来支持这两种方式,一个consumer group包含若干个consumer,topic中的消息只会被订阅该topic的group中的一个consumer消费。如果所有的消费者拥有相同的group则类似Queue的方式,topic中的消息将在consumer中达到负载均衡。如果每个consumer都属于不同的group则很类似订阅——发布,消息会广播给所有的消费者。consumer消费消息的方式是通过改变offset来实现的,offset和partition一一对应并且保存在zookeeper上,consumer会定期的更新offset的值到zookeeper上。consumer默认支持reblance,该特性很好的达到了consumer的容错和扩展功能,举例来说:
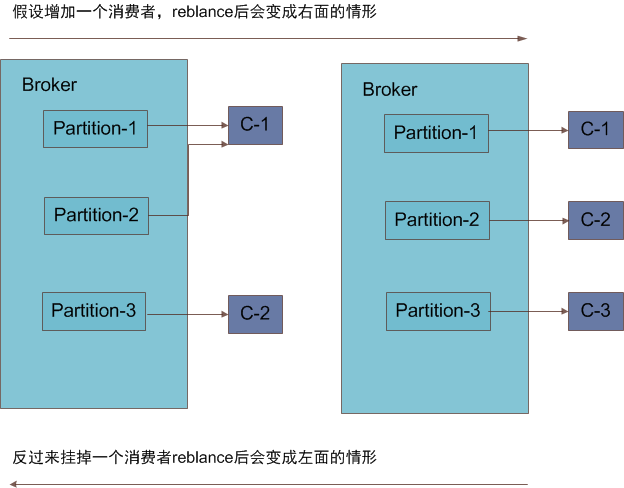
上面就是reblance的过程,但是它有一个明显的缺点是消费者可能负载会不均衡,同时kafka建议partition的个数不能少于consumer的个数,如果不满足会出现有的consumer永远不会消费到消息。如果reblance算法不能满足使用需求,可以使用simple level api自己定义均衡算法,这种方式更灵活,同时应用的可能也更广泛。
消息传输机制——
1) at most once:最多一次,消息只发送一次,不管是否成功处理都不会重发。
考虑消费者从broker获取到消息后然后触发commit动作,该动作会将offset的值写入到zk,下一次获取消息的时候会根据此偏移量获取,如果在commit后消费者处理消息失败则消费者永远不会再处理到该消息(offset以持久到zk)。
2) at least once::消息至少发送一次,如果消息未能成功处理,可能会重发直到成功。
考虑消费者从broker获取消息后先进行处理,等处理完在commit,但是在commit之前系统崩溃,这会导致系统下次还会再一次处理该消息,因此如果对消息的重复处理有严格的要求,比如扣费,则需要慎重使用该项,可以从接口设计方面改善,比如将扣费接口设计成幂等性的操作,从而避免消息重复发送造成的重复扣费。
3) exactly once:消息只会发送一次。
kafka中并没有严格的去实现(基于2阶段提交,事务),如果一定要做到exactly once ,就需要协调offset和实际操作的输出。精典的做法是引入两阶段提交,但是如果能让offset和操作输入存在同一个地方,会更简洁和通用。这种方式可能更好,因为许多输出系统可能不支持两阶段提交。比如,consumer拿到数据后可能把数据放到HDFS,如果把最新的offset和数据本身一起写到HDFS,那就可以保证数据的输出和offset的更新要么都完成,要么都不完成,间接实现exactly once。offset的处理可以使用simple level api自定义去完成。
两阶段提交的实现比较麻烦,它需要事务的协调者和事务的所有参与者之间经过多次消息的确认才能完成一个完成的事务提交动作,
中间任何一步出错,所有参与者的事务都需要回滚。














 7704
7704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









