






原文链接 http://www.acodersjourney.com/2018/08/database-sharding/
1. 什么是分片或者数据分区
数据分片(也称为数据分区)就是把一个巨大的数据集分为多个小分区的过程,这些小分区位于不同的机器上。每个分区都被称为“分片”。
每个分片都有和原来的数据库相同的schema。原来的数据库的大部分数据都分布在各个分片上,原来的数据库的表的每行数据都只存放于一个分片上。把全部分片的数据合并起来就得到了与原来的数据库相同的数据库。
下面两张图片展示了一个没有分片的数据库和一个有简单分片的数据库。
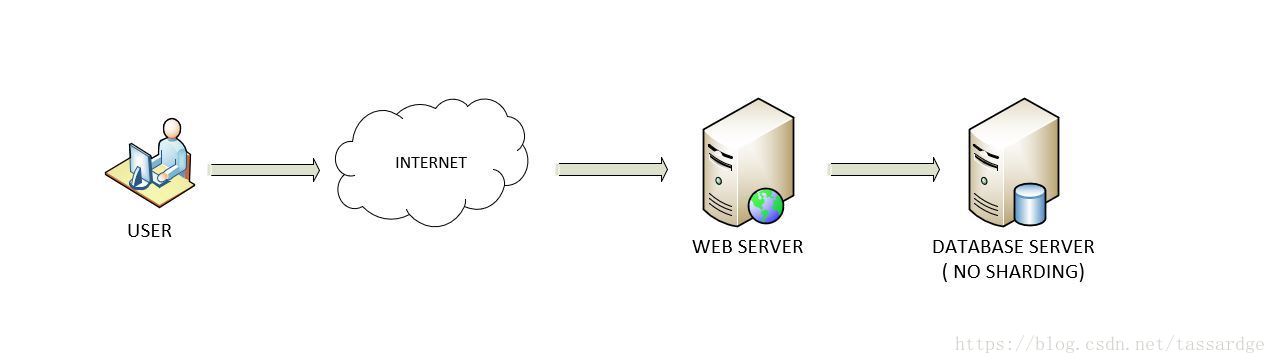
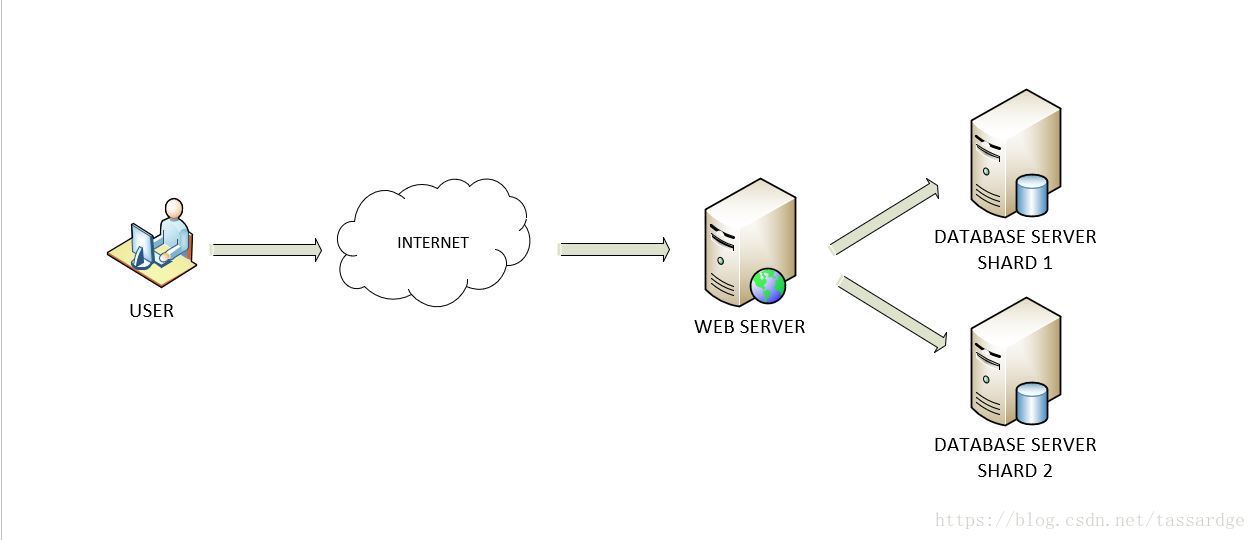
注意:分片架构对于应用程序是透明的。应用程序访问数据库分片(分区)就如同它访问一个未分片的数据库一样。
2.分片解决了哪些扩展性问题
当有更多的用户注册到你的系统的时候,如果你使用未分片的数据库架构的话就可能有性能降级的问题。你的查询和修改操作可能会变慢,你的网络带宽可能会变得饱和。你的数据库服务器的磁盘空间可能会被用完。
分片技术可以通过把数据库分布到机器集群上解决以上问题。理论上,你可以通过大量的分片为你的数据库提供虚拟的无限水平扩展。
3.每个分片都位于一个不同的机器上么?
不同的分片可能位于同一台机器上(共存),也可能位于不同的机器上(远程)。
共存分区的动机是减少独立索引的大小并且减少更新记录需要的IO的数量。
远程分区的动机是通过把更多的数据存放于内存从而避免磁盘访问或者通过拥有更多的网络接口和磁盘IO通道来增加访问数据的带宽。
(译者注:共存分片的动机完全不能说服我:既然两个分片在同一台机器上,那么这两个分片就差不多等于一个分片了,那还要分片做啥?)
4.数据分片或者分区的一般scheme是什么?
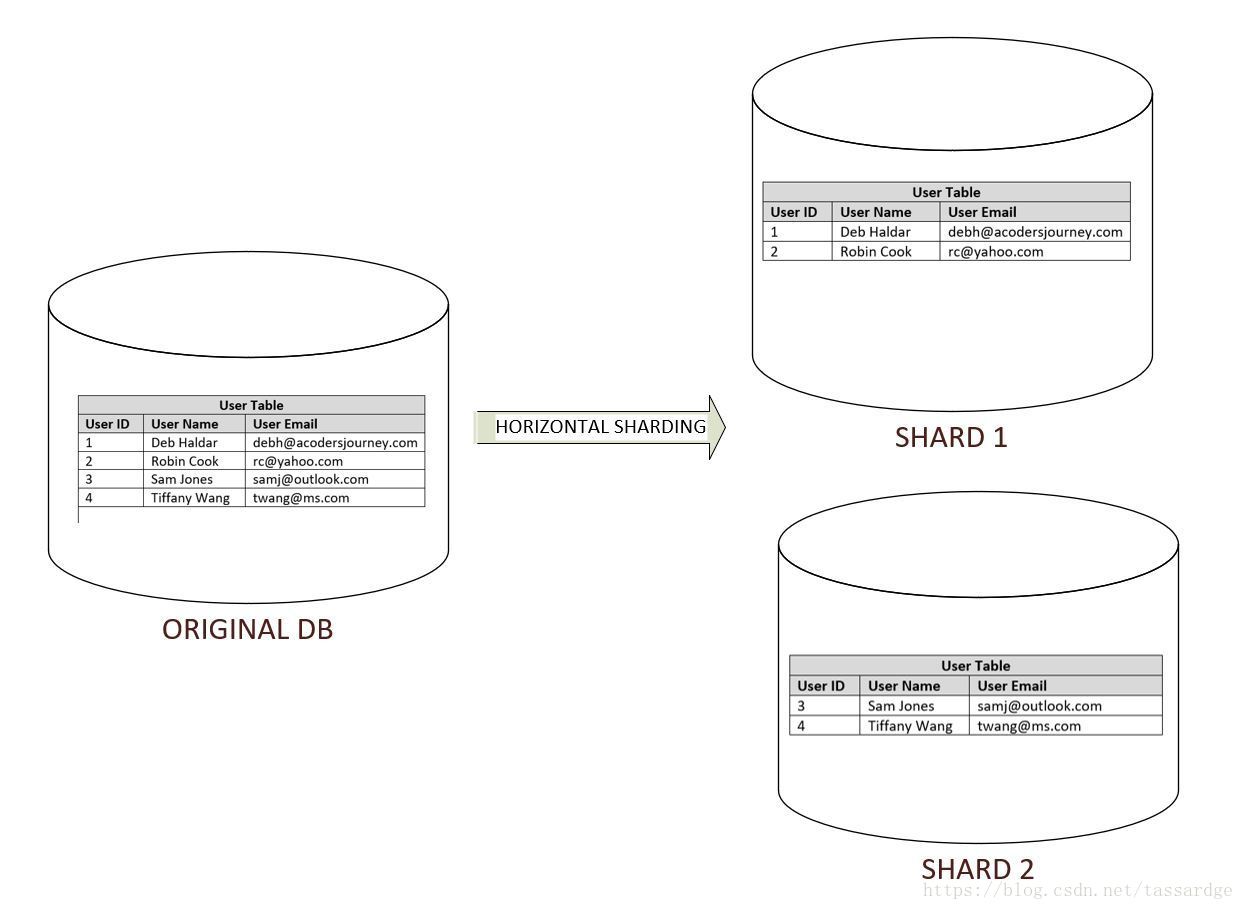
1)基于水平或者范围的分区
我们可以基于每个实体的共有键值的值域来分区。例如,如果你想保存你的在线客户的联系信息,你可以选择把姓名起始字母为A-H的用户保存在一个分片上,而把其他的用户保存于另一个分片上。
这种方法的缺点是用户的姓名未必是均匀分布的。例如,可能大部分用户的姓名都位于A-H区间,该区间以外的用户数量可能会很少。这样的话,第一个分片的负载可能会远远大于第二个分片。
无论如何该方法的优势在于它很简单。每个分片都和原来的数据库有相同的scheme。在大多数情况下你的应用层会相对简单,因为你不必从多个分片合并数据以响应任何查询请求。
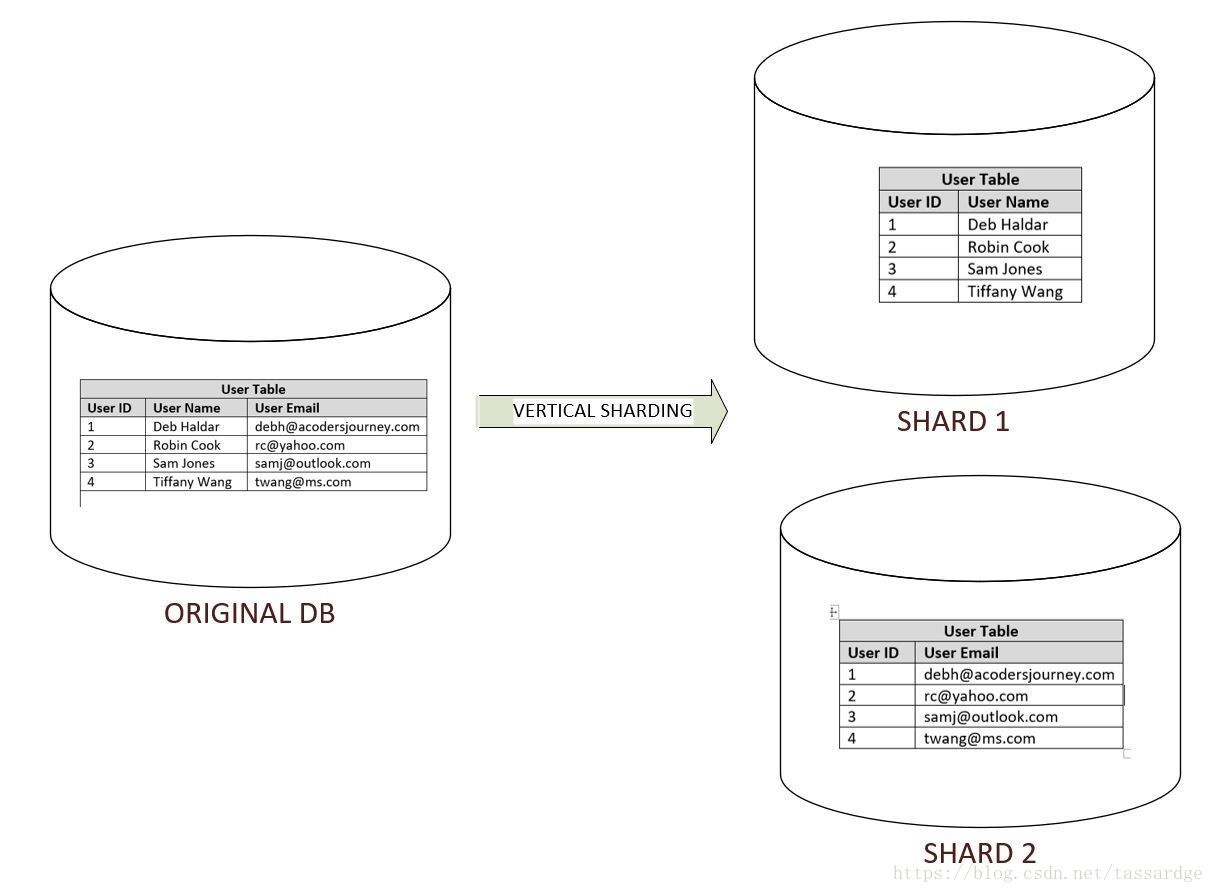
2)垂直分片
同一实体的不同属性会被存放于位于不同机器上的不同分片上。例如,在一个类似linked的应用中,一个用户可能有配置文件、一个人际关系连接列表和该用户发布的文章列表。在垂直分片方法中,我们可能会把用户的配置文件保存于第一个分片上,把人际关系列表保存于第二个分片上,把文章列表保存于第三个分片上。
该方法的主要优势在于你可以把关键数据(例如用户配置文件)和非关键数据(例如文章列表)分开处理,并且围绕它们建立不同的一致性模型或者replication模型。
垂直分片的缺点在于:
a.你的应用层可能需要合并多个分片的数据以响应查询。例如,为了响应一个查询用户记录的请求,应用层可能需要合并配置文件分片、人际关系分片和文件列表分片的数据。这会增加系统的研发和运营的复杂性。
b.如果你的系统不断增长那么你可能需要对一个分片进一步分片。
3.基于键值或者哈希值的分片
我们可以基于实体的键值(某个属性)来生成哈希值。这个哈希值可以决定数据保存于哪个分片上。
例如,假设我们基于用户ID分片并且我们有4台数据库服务器分别存放4个分片。而实体的键值为“application id”,该值为递增为1的整数。
那么我们可以简单地用取余函数对“application id”取余来决定实体存放于哪个数据库分片中。

该方法的缺陷是负载的弹性扩展(动态添加删除数据库服务器)很困难并且昂贵。
例如,如果我们想添加6台数据库服务器的话,那么大部分键值需要被重新映射并且迁移到新的数据库服务器上。另外,哈希函数也要被修改为对10取余。
在数据迁移的过程中,新旧哈希函数都不能使用。所以在数据迁移的过程中,我们的系统会无法提供服务。
这个问题可以由一致性哈希解决。http://www.acodersjourney.com/2017/10/system-design-interview-consistent-hashing/
4)基于目录的分片
该方法需要在数据库分片集群的前端放置一个查询服务。这个查询服务了解当前的分区scheme,并且有一个map保存了每一个条目到数据库分片的映射。这个查询服务通常实现为一个web服务。
应用层需要先向查询服务查询分片的存放位置,然后再查询/更新返回的分片。
那么这个松耦合的优势何在?
我们可以用这个方法解决上文提到的“弹性扩展问题”,而且没必要使用一致性哈希。
以下为具体步骤:
a.在查询服务中保留对4取余的哈希函数;
b.基于新的对10取余的哈希函数决定数据的存放位置;
c.写一个脚本基于第二步中的算法把数据从原有的4个分片中复制到新添加的6台服务器上。
d.一旦复制操作完成,就在查询服务中切换到对10取余的哈希函数;
e.运行一个清理脚本以清除第二步中的4台服务器上的冗余数据。因为这些数据已经保存在其他分片上了。
我们可能会遇到以下两个问题:
a.迁移的过程中用户可能要再更新数据。我们可以让数据库只读,或者把更新的数据存放于另一台服务器上;
b.在迁移过程中,复制和清理脚本可能会对系统性能有影响。It can be circumvented by using system cloning and elastic load balancing,但是这两个方法都很昂贵。(译者注,英文部分没看明白)
5.分片有哪些一般问题?
以上的讨论可能让我们觉得分片是解决数据库扩展问题的银弹。然而事实却并非如此,下面我们将讨论分片技术可能有的问题。
a.在某些情况下,数据库连接会变得更加昂贵、不灵活。
如果所有数据都在一个单一的数据库服务器上的话,连接操作可以简单地实现。但是当我们对数据库分片的时候,跨越多台服务器的连接操作会带来额外的延迟。
还有,应用层可能需要额外的异步和异常处理代码,而这会增加研发和维护的成本。
在某些情况下,当你需要为你的服务维护高可用性的SLA的时候,跨机器的连接并非合适的选择。
那么剩下的唯一选择就是“反范式”我们的数据库以避免连接操作。但这在提高系统的可用性的同时,也带来了一致性的问题。我们的应用层逻辑需要巨大的改变以处理来自不同分片的不一致的数据。
2)分片会影响到外键引用
大多数数据库不支持跨越数据库的外键引用。这意味着如果应用层需要外键引用的话,它就要在代码中检查外键;并且一旦采用分片技术后我们要运行sql jobs以清除分片中的无效外键引用。
如果你已经采用了nosql技术的话,那么上述影响对你可能不大,因为采用nosql技术意味着你的应用层代码已经在处理外部引用和一致性问题了。
As a mitigation for consistency and referential integrity issues , you should minimize operations that affect data in multiple shards.(译者注:不明白什么意思,貌似这句话可有可无)
If an application must modify data across shards, evaluate whether complete data consistency is actually required. Instead, a common approach in the cloud is to implement eventual consistency. The data in each partition is updated separately, and the application logic must take responsibility for ensuring that the updates all complete successfully, as well as handling the inconsistencies that can arise from querying data while an eventually consistent operation is running.
(译者注:最后一段没看明白,可能要先看了http://www.acodersjourney.com/2018/08/eventual-consistency/才能明白)
3)修改数据库scheme的成本会极其昂贵
在有些情况下当我们的用户基数增长的时候,数据库的scheme可能需要修改。例如,我们可能已经把用户的图片和邮箱存放在了某个分片上,现在我们需要把他们存放于不同的分片上。这意味着我们的全部数据都要被迁移到新的分片上。而这会导致系统五福提供服务。(译者注:而且所有的分片都要修改数据库scheme,这个成本也很高)
一个解决方法是使用基于目录的分片技术来解决这个问题:http://www.acodersjourney.com/2017/10/system-design-interview-consistent-hashing/
6.何时在系统设计面试中使用分片?
当单一的数据库无法满足性能要求的时候,或者to improve performance by reducing contention in a data store.(译者注:后半句没看明白)
例如,如果我们需要设计一个netflix的话,那么我们需要对大量的视频文件做低延时的读操作。在这种情况下,你可能需要基于电影的类型做分片。你可能还想要为某个分片创建多个replica以提供高可用性。
虽然分片的主要目的是提高系统的性能和扩展性,但是作为一种“具体问题具体分析”的技术它还能依据数据如何分片来提高可用性。一个分片的数据无法读取并不影响应用层从其他分片读取数据,并且运营人员可以在对一个分片做维护或者恢复操作的同时不影响其他分片数据的访问。














 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









