







本篇记录如何使用多张GPU 显示卡,加速TensorFlow Object Detection API 模型训练的过程。
虽然TensorFlow Object Detection API 已经有支援多张GPU 卡平行计算的功能,但是缺乏说明文件,所以我自己也不是非常确定该怎么用,以下只是我目前尝试出来的方式,仅供参考。
这里我们接续之前的TensorFlow Object Detection API自行训练模型教学,将Oxford-IIIT Pet Dataset的范例改成多GPU的版本。
使用多GPU卡时,会把每个batch的资料分散至每张GPU卡,也就是可以让batch size变大,所以在train_config的batch_size要自己修改一下,要让资料可以平均分散至每张GPU卡,最简单的修改方式就是看自己有多少张GPU卡,就乘以多少。
在预设的设定值中,batch_size的值是1,现在我打算用3张GPU卡,所以就改成3:
-
train_config: { -
batch_size: 3 -
optimizer { -
# [略] -
} -
# [略] -
}
由于batch size变大了,收敛的速度应该也会变快,所以optimizer内的参数应该也是要改的,不过要怎么改就要看实际情况而定,这个部分就自己看着办。
改好设定档之后,接着就可以使用多张GPU 卡平行运算,使用的指令几乎没有变,只是加上两个参数:
--num_clones:指定GPU 卡的数量。--ps_tasks:指定参数伺服器的数量。
另外再以CUDA_VISIBLE_DEVICES指定要使用哪几张GPU卡,完整的指令搞如下:
-
#设定档路径 -
PIPELINE_CONFIG = " object_detection/data/faster_rcnn_resnet101_pets.config " -
#训练结果放置路径 -
MY_MODEL_DIR = " my_model " -
#使用前三张GPU卡进行训练 -
CUDA_VISIBLE_DEVICES = 0 , 1 , 2 python object_detection/train.py \ -
--logtostderr \ -
--pipeline_config_path= ${ PIPELINE_CONFIG } \ -
--train_dir= ${ MY_MODEL_DIR } /train \ -
--num_clones =3 --ps_tasks=1 -
#使用第四张GPU卡进行验证 -
CUDA_VISIBLE_DEVICES = 3 python object_detection/ eval .py \ -
--logtostderr \ -
--pipeline_config_path= ${ PIPELINE_CONFIG } \ -
--checkpoint_dir= ${ MY_MODEL_DIR } /train \ -
--eval_dir= ${ MY_MODEL_DIR } / eval
指令执行之后,我们可以使用nvidia-smi来查看每一张GPU卡的使用情况,看看是不是真的有同时用到三张GPU卡训练:
nvidia-smi<span style="color:#111111">Tue Dec 26 15:35:34 2017
+------------------------------------------------- ----------------------------+
| NVIDIA-SMI 384.81 Driver Version: 384.81 |
|-------------------------------+----------------- -----+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+================= =====+======================|
| 0 TITAN Xp Off | 00000000:02:00.0 Off | N/A |
| 44% 72C P2 186W / 250W | 11763MiB / 12189MiB | 84% Default |
+-------------------------------+----------------- -----+----------------------+
| 1 TITAN Xp Off | 00000000:03:00.0 Off | N/A |
| 47% 76C P2 124W / 250W | 11763MiB / 12189MiB | 76% Default |
+-------------------------------+----------------- -----+----------------------+
| 2 TITAN Xp Off | 00000000:83:00.0 Off | N/A |
| 42% 70C P2 131W / 250W | 11763MiB / 12189MiB | 72% Default |
+-------------------------------+----------------- -----+----------------------+
| 3 TITAN Xp Off | 00000000:84:00.0 Off | N/A |
| 23% 41C P2 72W / 250W | 11761MiB / 12189MiB | 51% Default |
+-------------------------------+----------------- -----+----------------------+
+------------------------------------------------- ----------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|================================================= ============================|
| 0 22192 C python 11751MiB |
| 1 22192 C python 11751MiB |
| 2 22192 C python 11751MiB |
| 3 29266 C python 11751MiB |
+------------------------------------------------- ----------------------------+</span>在训练的过程中,如果仔细观察每步的计算速度,应该会发现使用一张GPU 卡的速度会跟使用多张GPU 卡差不多。这是单张GPU 卡的速度:
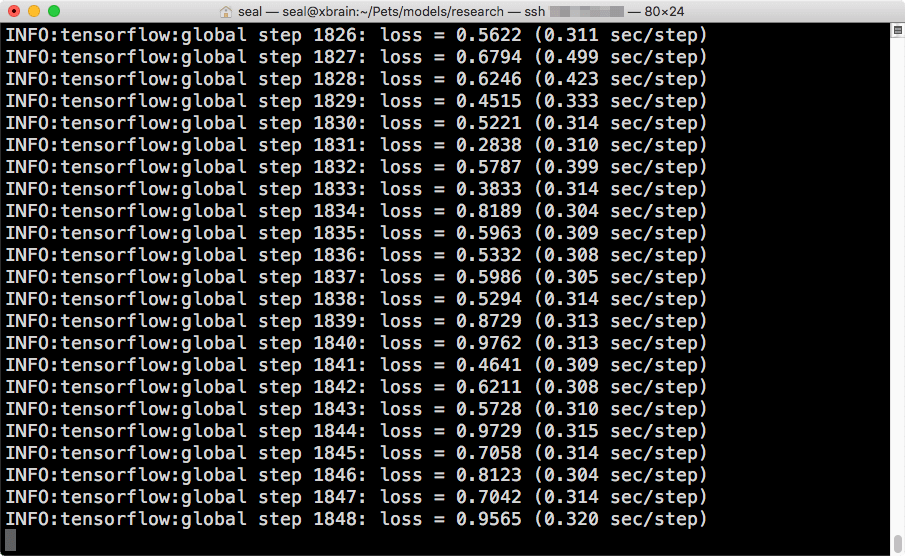
单张GPU 卡计算速度
这是同时使用三张GPU 卡的计算速度:
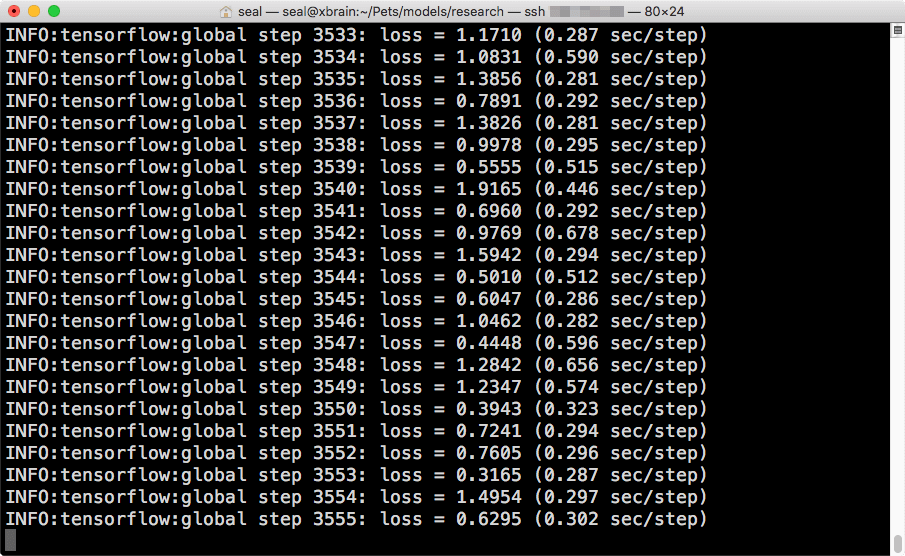
三张GPU 卡计算速度
速度会差不多是正常的(理论上多张GPU 卡运算的速度会变慢一点点),因为两边的batch size 不同,若每步的计算时间差不多,就表示实际的计算速度有增加。
原文:https://blog.gtwang.org/programming/tensorflow-object-detection-api-multiple-gpu-parallel-training/














 5575
5575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









