







宝存科技数据库方案架构师
本文来自于本周四云和恩墨大讲堂戴明明(Dave)的分享内容:基于 PCIE 闪存卡的Oracle 数据库使用场景。课程通过对 PCIE 闪存卡的说明,让大家了解了如何使用 PCIE 闪存卡来提升 Oracle 数据库的性能。
PCIE 闪存卡概述
对于闪存卡的概念,大家应该是有一定的了解,即使没有听过,那么也应该了解固态硬盘,他们是同一种存储方式,即使用Nand Flash。
先看一组对比数据:

通过这组数据可以非常明显的看出来,PCIe 闪存卡的性能是最好的。
对于运维人员,尤其是 DBA,也非常的明白,对于数据库,最大的性能瓶颈也就是 IO。所以 PCIe 闪存加 数据库就是一个完美的组合,可以极大的提升数据库的性能。
上面的是不同存储介质的性能对比,我们在看一组 PCIe 闪存卡的性能数据,从而来颠覆一下对传统存储介质的速度观。
| 容量 | 800GB | 1.2TB | 1.6TB | 3.2TB | 6.4TB |
| 闪存类型 | MLC | MLC | MLC | MLC | MLC |
| 读带宽 | 1.4GB/s | 2.0GB/s | 2.6GB/s | 2.6GB/s | 2.6GB/s |
| 写带宽 | 1.2GB/s | 1.8GB/s | 1.8GB/s | 1.9GB/s | 1.9GB/s |
| 随机读延迟(4KB) | 67us | 67us | 67us | 67us | 67us |
| 随机写延迟(4KB) | 9us | 9us | 9us | 9us | 9us |
| 随机读IOPS(4KB) | 300,000 | 450,000 | 590,000 | 590,000 | 590,000 |
| 随机写IOPS(4KB) | 310,000 | 460,000 | 480,000 | 480,000 | 480,000 |
| 写入寿命 | 每天5次全盘写(5DWPD), 持续3年 |
在这个表格里,我们需要重点关注几组数值:
1. 读写带宽,以6.4TB 的为例,读带宽是2.6GB/s,写带宽是1.9GB/s.
2. 读写延迟分别是67us和 9us。 这里可能有人可能会有疑问。
为什么写延迟比读延迟还低很多,还不是一个数量级。
这个问题与闪存卡的设计有关,闪存卡的FPGA里有个缓存,写数据,只要写入到缓存就认为写成功了。但读数据是正的要从Nand Flash 中读取。所以写延迟比读延迟低很多。
3. IOPS,分别是59w和48w。这个指标对于数据库非常重要。
除了这些性能指标之外,做完运维人员更关注的是稳定性。否则即使闪存卡的性能再好,我们也不敢用,因为数据对于企业来说是无价的,不能因为性能,而丢失了数据。
讲到闪存卡的寿命,需要引入另一个知识点:闪存卡的分类,见下图:

另外因为闪存卡使用的Nand Flash作为存储介质,那么具有如下特性:

其中有一个就是擦除寿命,闪存卡读不坏,但会写坏,就是 page 擦除次数达到寿命后,这个 page 就不能使用了,就是闪存卡容量的降低。
所以闪存卡厂商在设计的是,都会留足够多的 Over-Provision (OP) 空间。
总之,Nand Flash 的类型决定其page的擦除次数。 OP 值影响的是闪存卡的性能和安全性。
民用级的 SSD 采用的是 MLC 和 TLC,并且 OP 值一般也控制在10%以内,这样可以控制成本,但 OP 值低,会导致写放大系数高,也会影响整体闪存卡的性能。
企业级的 PCIE Flash 闪存卡采用的是 MLC,OP 值可以做到 20% 以上,OP 值高,写放大系数可以控制的更低,大的 OP 值也可以给闪存卡提供更好的性能。
根据上面的说明,我们举个例子,假设我们买了一张6.4T 的闪存卡。
它的寿命是:6.4T * 5 * 365 * 3 = 34P。
就是每天全盘写5遍,能连续写3年。实际上很少有人的数据库能每天写30T的数据。所以闪存卡的寿命决绝可以满足我们的需求。
当然闪存卡也分很多厂家,对于闪存卡的性能,在存储行业有通用的测试工具。就是 FIO。
FIO 是 linux 下的测试工具,如果是 Windows 的系统,那么对应的工具是 IOMETER。
关于这2个工具的使用,这里不在说明,有兴趣的可以参考我的Blog:
IO压力测试工具 -- FIO 使用说明
IO压力测试工具 -- IOMETER 使用说明
PCIE 闪存卡的使用场景
1
基于闪存卡的 Oracle 能跑出什么样的性能
前面说闪存卡+ 数据库是完美的搭配,我们这里看一组测试数据,看到底能碰撞出多大的火花。
测试环境:
服务器: 八路X86 服务器
操作系统: RedHat6.5
CPU: Intel E7-8870v2 * 8
内存:1T
数据库:11.2.0.4
测试工具:HammerDB

使用 Hammer DB 压了5000个 warehouses,然后使用 200 个 Virtual User 来进行压力测试,然后得到了上图的数据:
TPM:4044739(400w)
NOPM:1344006(134w)
Redo size:340M/s
执行SQL: 139w/s
事务:6.7w/s
这个还是一张卡和一台八路的X86服务器。这个性能跑我们绝大部分业务都没啥问题了。
这里提到了 HammerDB 的工具。实际上我们测试数据库性能压力的方法很多。
关于数据库性能测试这块的内容,可以参考我的Blog:
数据库基准测试(Database Benchmarking)说明
数据库压力测试工具 -- Hammerdb 使用说明
数据库压力测试工具 -- Swingbench 使用说明
数据库压力测试工具 -- BenchmarkSQL 使用说明
2
基于闪存卡的 Data Guard 解决方案
单卡的性能再好,还是会存在单点故障的可能性。所以我们需要结合具体的解决方案来使用。
这里最简单也是最方便的,就是 Data Guard方案。
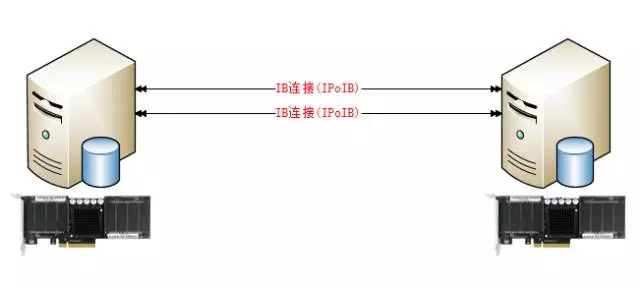
我们的这种架构和传统的Data Guard一样,只不过我们替换了2种硬件。
1. 底层的存储,我们直接使用 PCIE 闪存卡,能大幅的提升数据库的性能。
2. 主备库之间的数据传输。我们使用的是 Infiniband 网络。
因为闪存卡的性能很高,传统的千兆网络已经不能满足我们的性能性能需求,带宽不够,延迟也高。
替换这两种硬件之后,可以直接将 Data Guard 的保护模式切换成最大可用,做到实时的数据传输,在也不用担心单点故障带来的数据丢失。
当然这种方案里还是有弊端,就是发生故障的时候,系统还是中断一会。
如果想方案在好一点,那么就是上一体机。
3
基于闪存卡的RAC 解决方案

这种架构是一种分布式的存储。 采用2+3的架构。 上面2层是2个计算节点,底下3层是存储节点,采用 ASM 的 Normal 或者 High 容易来保证数据安全。
整个一体机的通讯都走 Infiniband 的 RDMA 协议,性能很高。
基于 PCIE 闪存卡的 Online Redo log 优化
在使用闪存卡的情况下,还有进一步的优化就是,数据库的 Online redo log。
1
Oracle 官方的建议
在 MOS 的文档(ID 857576.1)中提到如下一句话:
Also putting theSLOG on an SSD (Solid State Disk) will reduce redo log latency further. This will help improve the performance of synchronous writes.
在另一篇MOS文档(ID 1376916.1)中提到:
If the proportion of the 'log filesync' time spent on 'log file parallel write' times is high, then most ofthe wait time is due to IO (waiting for the redo to be written). Theperformance of LGWR in terms of IO should be examined. As a rule of thumb,an average time for 'log file parallel write' over 20 milliseconds suggests aproblem with IO subsystem.
Recommendations
-
Work with the system administrator to examine the filesystems where the redologs are located with a view to improving the performance of IO.
-
Do not place redo logfiles on a RAID configuration which requires the calculation of parity, such as RAID-5 or RAID-6.
-
Do not put redo logs on Solid State Disk (SSD)
Although generally, Solid State Disks writeperformance is good on average, they may endure write peaks which will highlyincrease waits on 'log file sync'.
(Exception to this would be for Engineered Systems(Exadata, SuperCluster and Oracle Database Appliance) which have been optimizedto use SSDs for REDO)
-
Look for other processes that may be writing to that same location and ensure that the disks have sufficient bandwidth to cope with the required capacity. If they don't then move the activity or the redo.
-
Ensure that the log_buffer is not too big. A very large log_buffer can have an adverse affect as waits will be longer when flushes occur. When the buffer fills up, it has to write all the data into the redo log file and the LGWR will wait until the last I/O is completed.
Oracle 不建议把 redo log 放在 SSD上,但 Exadata 系统中 redo 是存放在 SSD 上的。 不建议的理由是:
Although generally,Solid State Disks write performance is good on average, they may endure writepeaks which will highly increase waits on 'log file sync'.
Oracle 担心的是可能存在的 writepeaks 导致 log file sync 等待的增加。
Flasn 闪存卡使用的 Flash 介质分三种:SLC,MLC,TLC。
民用级的 SSD 采用的是 MLC 和 TLC,并且 OP 值一般也控制在10%以内,这样可以控制成本,但 OP 值低,会导致写放大系数高,也会影响整体闪存卡的性能。所以在这种情况下,确实可能出现 oracle 担心的 write peaks 带来的性能下降问题。
但企业级的 PCIE Flash 闪存卡采用的是 MLC,OP 值可以做到20%以上,OP 值高,写放大系数可以控制的更低,大的 OP 值也可以给闪存卡提供更好的性能。所以在这种情况下,不会出现 Oracle 担心的 write peaks 带来的性能问题。
2
4K Online Redo Log
上一代存储多采用 512 bytes 的扇区,现在的存储则采用 4k 的扇区,扇区即每次最小 IO 的大小。
4k 扇区有两种工作模式:nativemode 和 emulation mode。
Native mode:即 4k 模式,物理和逻辑的 block 大小一样,都是 4096bytes。 Native mode 的缺点是需要操作系统和软件(如 DB)的支持。Oracle 从 11gR2 开始支持 4k IO 操作。 Linux 内核在 2.6.32 之后也开始支持 4k IO 操作。
emulation mode:物理块是 4k,但逻辑块是 512bytes。在该模式下,IO 操作时底层物理还是 4k 进行操作,所以就会导致 Partial I/O 和 4k 对齐的问题。
在 emulation mode下,每次 IO 操作大小是 512bytes,但存储底层的 IO 操作大小必须是 4k,如果要读 512 bytes 的数据,实际需要读 4k,是原来的8倍,就是 partial IO。而在写时,也是先读 4k 的物理 block,然后更新其中的 512 bytes 的数据,再把 4k 写回去。所以在 emulation mode 下,增加的工作会增加延时,降低性能。
在 Oracle 数据库的文件中,默认情况下,datafile 的 block 是 8KB,控制文件是 16KB,所以都没有 partial IO 的问题,唯有 online redo log,默认是 512 bytes,存在 partial IO 的问题。
从 Oracle 11gR2 开始,在存储支持 4k 扇区的情况下,可以创建 Blocksize 为 512,1024,4096 的 redo log。
如:alter database add logfilegroup 5 size 100m blocksize 4096;
如果是 emulation mode 的 4k 扇区,创建 4k 的 redo log 时可能会触发如下错误:
ORA-01378: Thelogical block size (4096) of file +DATA is not compatible with the disk sectorsize (media sector size is 512 and host sector size is 512)
只要确认存储物理是 4k 的扇区,可以设置_disk_sector_size_override 参数为 true,来覆盖扇区的设置。该参数支持动态修改,如:
ALTERSYSTEM SET “_DISK_SECTOR_SIZE_OVERRIDE”=”TRUE”;
3
实际测试
--内存:
[root@dave ~]# free -g
total used free shared buffers cached
Mem: 15 15 0 0 0 8
-/+ buffers/cache: 6 9
Swap: 31 0 30
[root@dave ~]#
--CPU:
processor :3
vendor_id :GenuineIntel
cpu family :6
model :60
model name :Intel(R) Core(TM) i5-4570 CPU @ 3.20GHz
stepping :3
cpu MHz :800.000
cache size :6144 KB
--磁盘:/dev/dfa 是 3.2T 的 PCIE 闪存卡。
[root@dave ~]# df -lh
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/lvm-root 886G 35G 806G 5% /
tmpfs 7.8G 2.0M 7.8G 1% /dev/shm
/dev/sda1 1007M 47M 910M 5% /boot
/root/rhel-server-6.5-x86_64-dvd.iso 3.6G 3.6G 0 100% /mnt
/dev/dfa 3.1T 700G 2.3T 24% /u01
[root@dave ~]#
测试工具: HAMMER DB
测试数据量: 5000个 warehouse
--数据库: 12.1.0.2
SQL> select * from v$version;
BANNER CON_ID
------------------------------------------------------------------------------------------
Oracle Database 12c Enterprise EditionRelease 12.1.0.2.0 - 64bit Production 0
PL/SQL Release 12.1.0.2.0 - Production 0
CORE 12.1.0.2.0 Production 0
TNS for Linux: Version 12.1.0.2.0 -Production 0
NLSRTL Version 12.1.0.2.0 - Production 0
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ---------------------------------------- ----------
2 PDB$SEED READ ONLY NO
3 DAVE READ WRITE NO
4 ANQINGREAD WRITE NO
测试用的 PDB 是 ANIQNG。
② Online redo log 存放在 PCIE 闪存卡? 查看 online redo log
SQL> selectgroup#,bytes/1024/1024||'M' from v$log;
GROUP# BYTES/1024/1024||'M'
---------------------------------------------------
4 2000M
5 2000M
6 2000M
7 2000M
SQL> select group# ,memberfrom v$logfile;
GROUP# MEMBER
----------------------------------------------------------------------------------------------------
4 /u01/app/oracle/oradata/DAVE/onlinelog/dave01.log
5/u01/app/oracle/oradata/DAVE/onlinelog/dave02.log
6 /u01/app/oracle/oradata/DAVE/onlinelog/dave03.log
7/u01/app/oracle/oradata/DAVE/onlinelog/dave04.log
? 先创建一个快照:
SQL>executedbms_workload_repository.create_snapshot();
? TPCC 测试
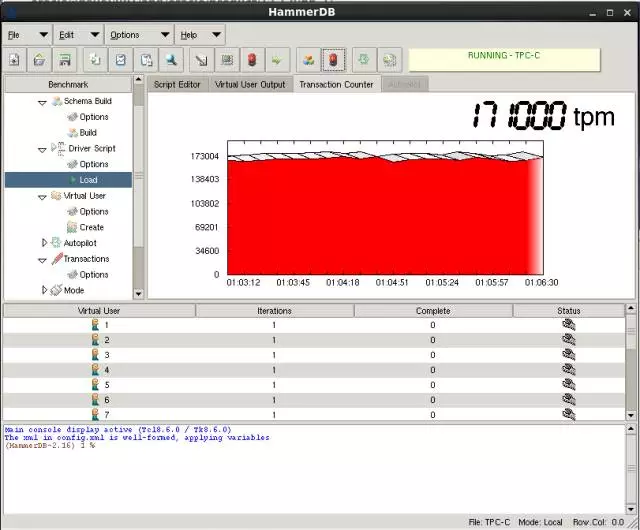
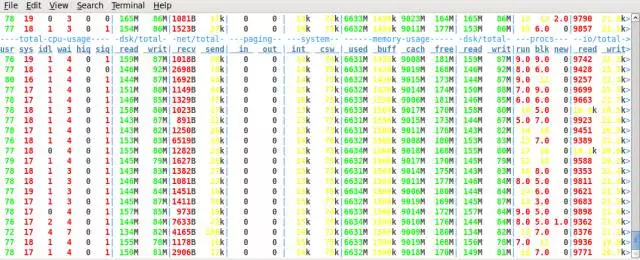
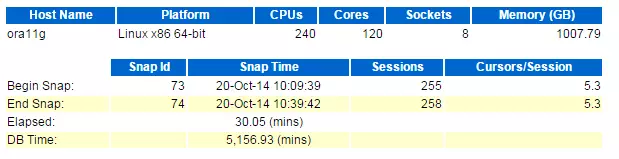
在创建一个 AWR 快照:
SQL> executedbms_workload_repository.create_snapshot();
PL/SQL procedure successfullycompleted.
生成AWR 报告:
SQL>@?/rdbms/admin/awrrpt.sql
? AWR 数据
我们这里只看2个部分:Load Profile 和 Top 10 Foreground Events by Total Wait Time


③ Online redo log 存放在 SAS 硬盘
? 移动 online redo log 到 SAS盘
[oracle@dave ~]$ mkdir /home/oracle/onlinelog
SQL> set lin 130
SQL> select group# ,memberfrom v$logfile;
GROUP# MEMBER
----------------------------------------------------------------------------------------------------
1 /home/oracle/onlinelog/dave01.log
2 /home/oracle/onlinelog/dave02.log
3 /home/oracle/onlinelog/dave03.log
4 /home/oracle/onlinelog/dave04.log
SQL> select group#,bytes/1024/1024||'M'from v$log;
GROUP# BYTES/1024/1024||'M'
---------------------------------------------------
1 2000M
2 2000M
3 2000M
4 2000M
SQL> alter system flush buffer_cache;
System altered.
SQL> alter system flush shared_pool;
System altered.
SQL>executedbms_workload_repository.create_snapshot();
? TPCC 测试
在之前同等的20个virtual 用户下,根本无法压到最大值:

修改成120个virtual user:

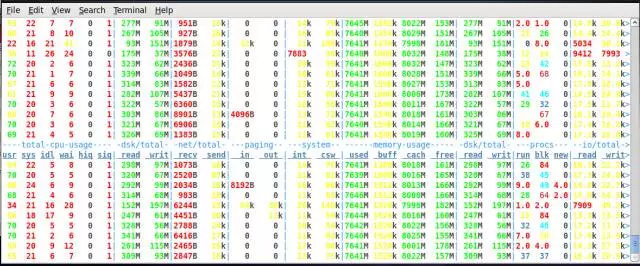
再创建一个AWR 快照:
SQL> executedbms_workload_repository.create_snapshot();
PL/SQL procedure successfully completed.
SQL> @?/rdbms/admin/awrrpt.sql
? AWR 数据
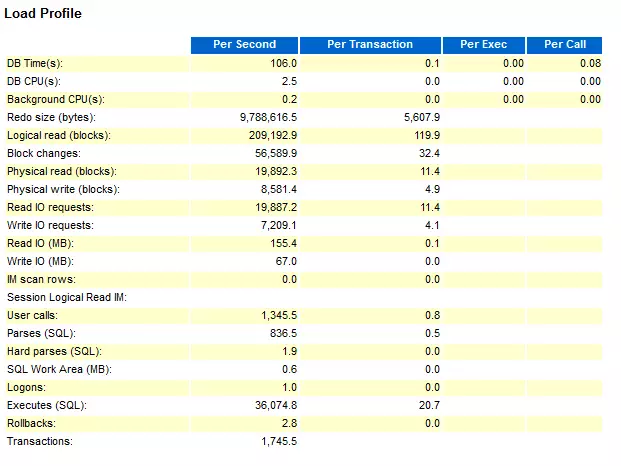
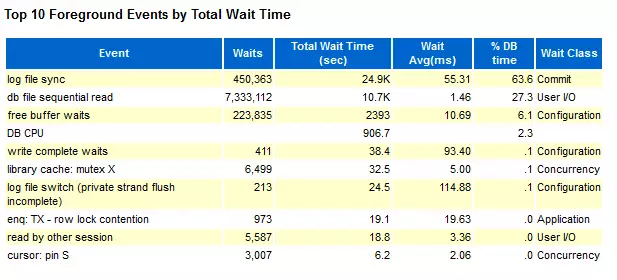














 993
993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









