






ovCompose(online-video-compose)是腾讯大前端领域Oteam中,腾讯视频团队基于 Compose Multiplatform 生态推出的跨平台开发框架,旨在弥补JetBrains Compose Multiplatform不支持鸿蒙平台的遗憾与解决iOS平台混排受限的问题,便于业务构建全跨端App。同时腾讯视频深度参与Oteam并推出了KuiklyBase,涵盖Kotlin/Native的鸿蒙适配、组件生态、鸿蒙编译、堆栈还原、工具链相关建设,助力业界KMP开发者提高鸿蒙适配效率。ovCompose & KuiklyBase 现已在GitHub开源,让我们一起深入实现细节。

1.背景
随着纯血鸿蒙的推出,客户端跨平台需求被推到了前所未有的高度,单纯的 UI 跨端已无法满足业务诉求,构建Android/iOS/鸿蒙平台的全跨端APP能够最大幅度的降低业务开发成本,提升人效。并且行业内研发模式的逐步改进,单周发版已经成为常态,对于常规APP,动态化的诉求并不是很强。开发者普遍希望在保持原生优良性能的同时,使用行业通用的UI开发语言,从而最大程度降低学习成本。
Kotlin 与 Compose 是 Google 官方推荐的 Android 开发语言与 UI 框架,也是深受开发者喜爱应用开发方案。与其他跨端方案相比,Kotlin Multiplatform 还具备高性能,与原生交互更灵活等优点。因此腾讯视频选择了 Compose Multiplatform 作为全跨端APP的基础。当然,这套方案也存在不支持纯血鸿蒙、iOS平台混排能力受限、GC性能表现一般等一系列问题,使得落地的过程充满了挑战。经过不懈努力,上述问题均已得到妥善解决,现在我们希望将这些解决方案开源,期待与全行业一同推动Compose跨端生态走向成熟。

2.特性优势
ovCompose已经在腾讯视频鸿蒙平台全面落地,成为鸿蒙平台首个全跨端APP。同时 KuiklyBase 基础能力已在腾讯视频、QQ 浏览器、腾讯体育等10+款APP广泛落地。Android、iOS、鸿蒙三端一码的开发方式,使得业务的开发效率得到大幅度的提升。随着鸿蒙系统的发展,ovCompose 和 KuiklyBase 也会在未来进一步扩展到TV和PC端。
2.1 鸿蒙高性能
Kotlin鸿蒙适配有JS与Native两种技术方案可供选择,KuiklyBase最终选择了Native方案。因为KN相比JS有更快的执行速度,更好的三端一致性。
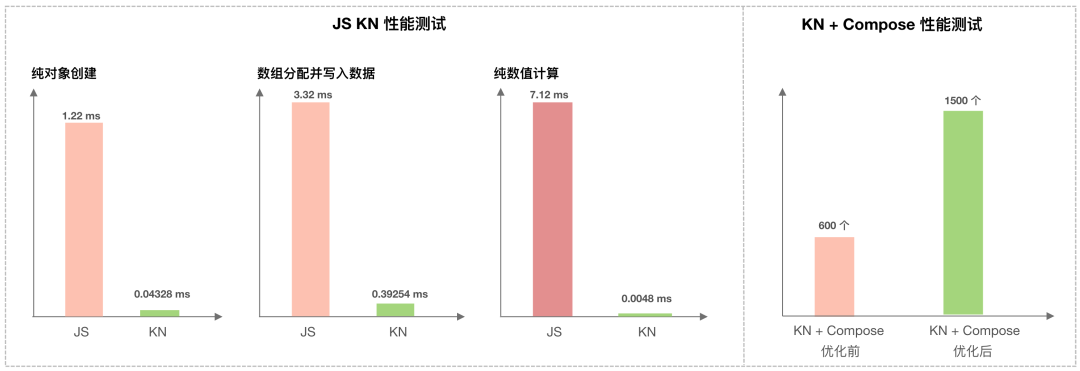
关于 JS 和 KN 的性能测试的数据如上图所示。我们对 KN 和 Compose 两者都进行了性能优化,在Compose "小球碰撞" Demo 中。以 30 FPS 为最低极限,经优化小球数量由600提升到1500(Android 1600球),绘制性能提升150%。后续将开放更多优化策略。
相关资料如下:
1. JS 和 KN 性能测试详细数据:
https://docs.qq.com/sheet/DQXB4YmxQaENSdkpD
2. ovCompose 小球碰撞 Demo:
https://github.com/Tencent-TDS/ovCompose-sample
3. Kotlin 官方的 Benchmark:
https://github.com/JetBrains/kotlin/tree/master/kotlin-native/performance/ring
2.2 鸿蒙三明治架构支持混排
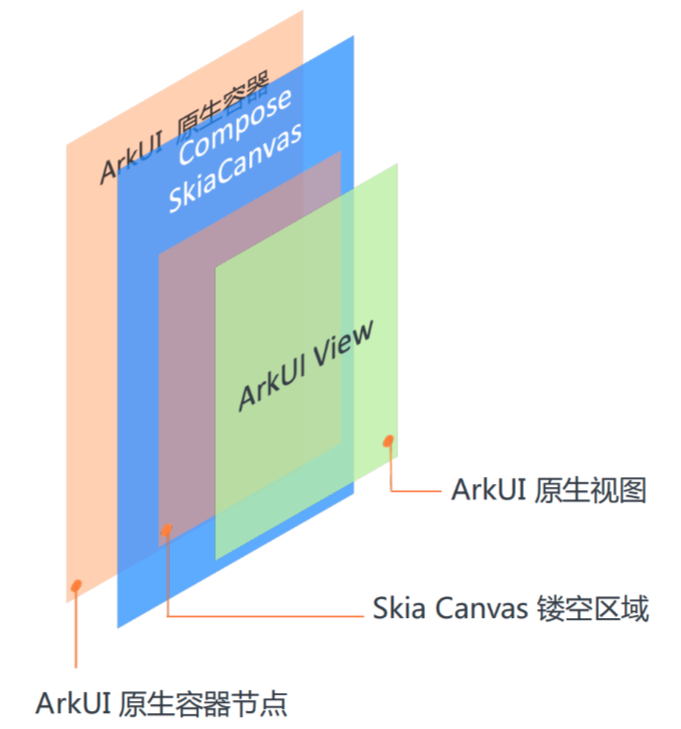
鸿蒙平台采用了 Skia 的渲染方案,能够100%支持 Compose 语法和渲染能力。Skia 渲染使用 XComponent 组件作为画布,通过三明治镂空结构,很好的解决了与原生组件的混排问题,原生UI可以展示在 Compose 上层或下层,满足了绝大部分的业务需求。同时支持了 粘贴按钮 等安全组件的混排,使得 Compose 无需申请权限也能使用系统能力。
2.3 三端高一致性
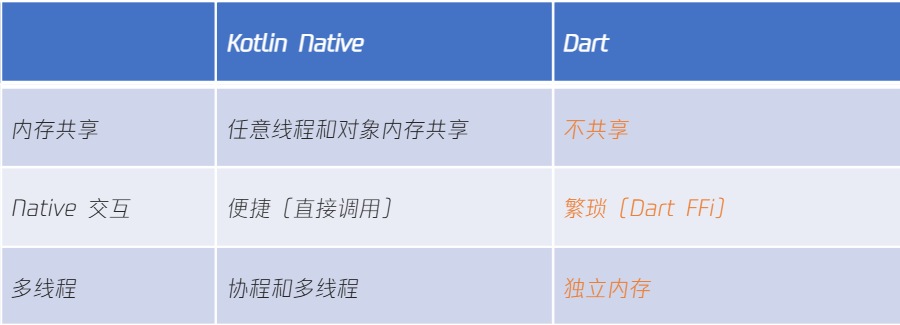
对于逻辑运行:由于在鸿蒙平台采取 Kotlin-Native 方案,解决了 Kotlin-JS 使用 TaskPool 时,Kotlin 语法无法约束跨线程访问的问题,保持了高度的三端一致性。
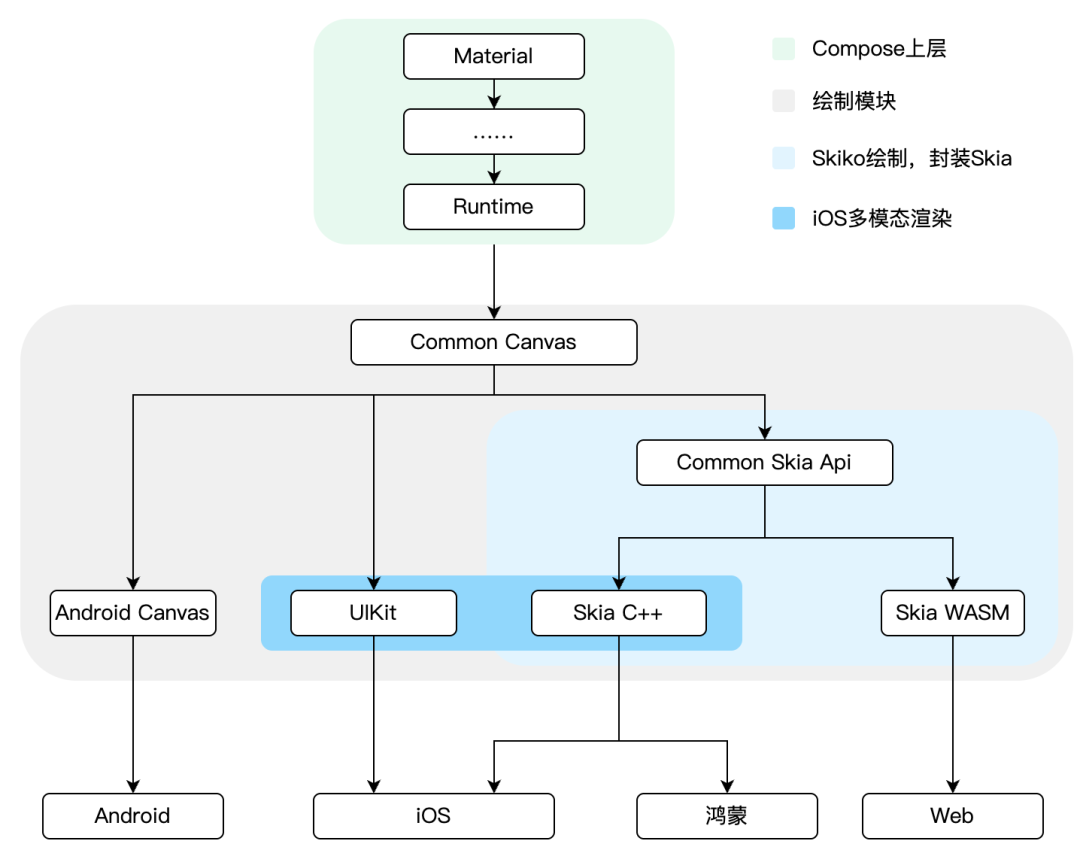
对于UI绘制:iOS、鸿蒙平台均采用Skia渲染,Android底层使用Skia渲染,应用层暴露了Paragraph/Canvas的绘制接口。所以基于Skia封装后的Skiko可以完美还原Android绘制效果,达到三端一致的效果。三平台均可以100%使用Compose的控件与绘制能力。
2.4 iOS多模态渲染解放混排能力
iOS端大量存量业务模块高度依赖Compose与原生UI的混合编排能力,其灵活混排的技术实现及与原生UI性能标准的精准对齐,是业务Compose化改造成功推进的核心前提。
Compose Multiplatform 官方在 iOS 端上使用 Skia + CAMetaLayer 实现 UI 的渲染能力,这种方案的好处是与其他端表现完全一致,缺点就是与原生 UI 的混排能力较弱,且内存占用较高,不适合多个 Compose 实例并存。因此我们必须考虑以下两种方案:
1. 指令映射,即使用 UIKit 实现Compose Canvas 。
2. 组件映射:即将Compose组件映射为Native组件。
组件映射方案在组件层进行映射实现,是业内最常见的跨端 UI 框架设计方案,实现难度相对较低,但存在后期维护成本高,多端不一致等问题。指令映射在画布层进行映射实现,实现的逻辑层级更低也更加抽象,虽然开发难度相对较高,但却可以充分利用 UIKit 丰富的渲染能力对Compose的绘制效果实现较高的还原度。
因此我们最终采用了指令映射的自研实现方案解决了 Compose 在 iOS 上面临的诸多难题。这套方案也成功地在腾讯视频 iOS 端核心业务场景落地。事实上,业务团队甚至可以根据实际应用场景在基于 UIKit 实现的自研指令映射方案或官方的Skia渲染方案之间进行自由切换,并且可以在 Runtime 期共存。
关于 UI 的多端一致性,文本渲染较为复杂,我们采取 Skia 将文本渲染成图片,利用 CALayer 进行展示的方案,保持了高度的一致性。
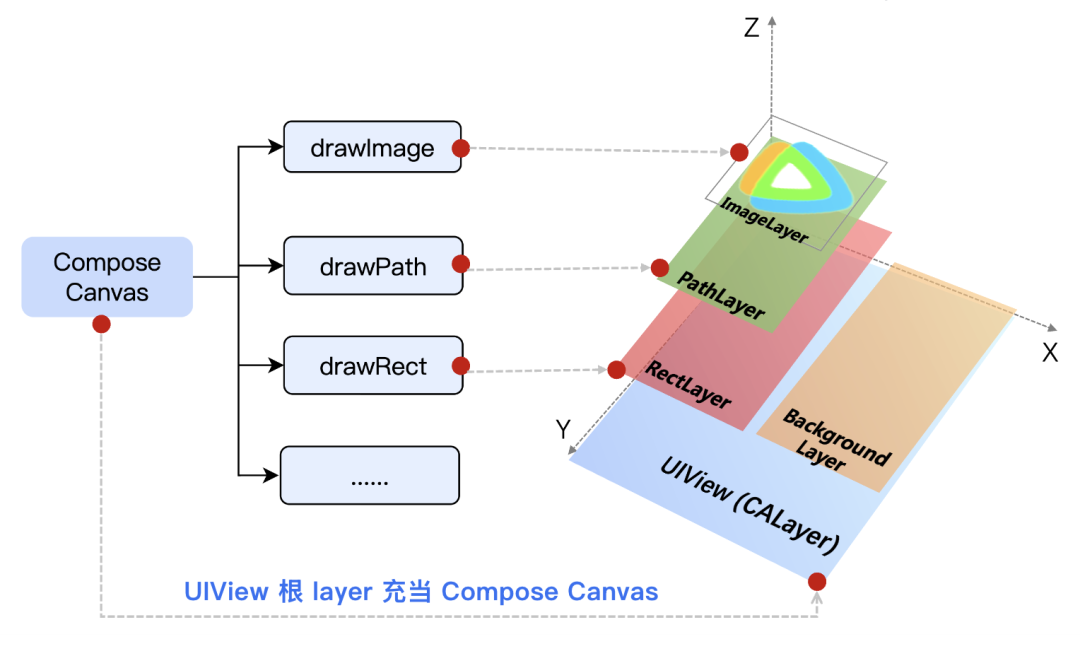
2.5 Kotlin Native 内存优化
2.5.1 GC优化
GC抑制
当APP处于滑动等对帧率要求较高的场景,我们会短暂抑制GC,来换取更好的流畅度。
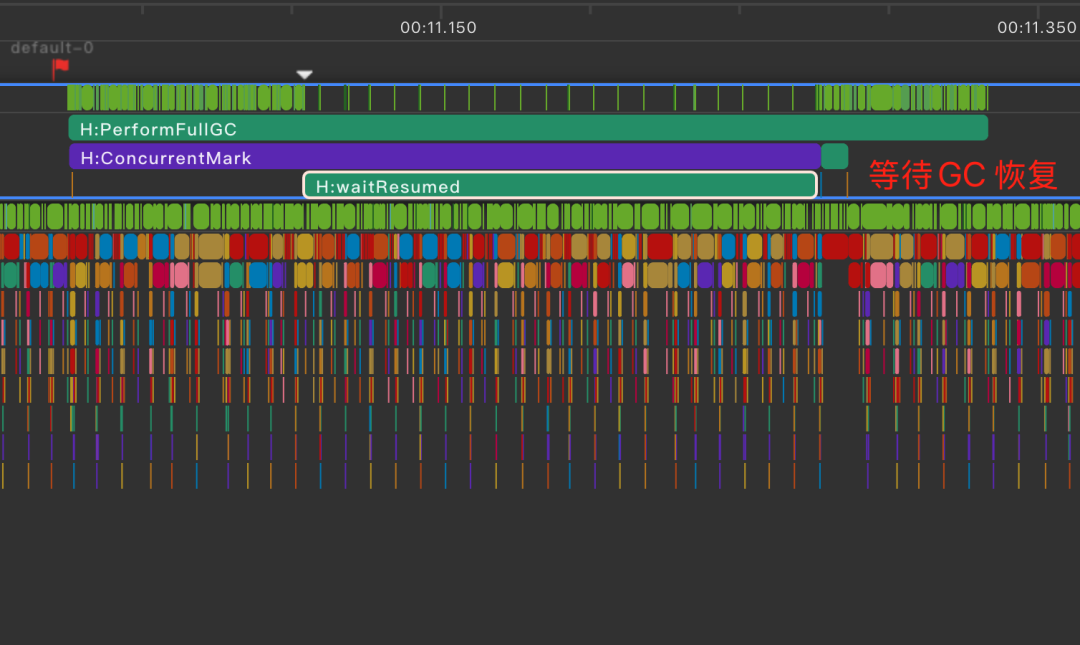
GC分段
不影响帧率情况下,进行更高频次的 GC,降低 PSS 水位。通过分析 CMS(Concurrent Mark-Sweep)垃圾回收算法,发现其存在两次 Stop-The-World(STW)暂停,并且第一次 STW 时间较短,第二次 Sweep 期间的 STW 较长。利用 GC 挂起的能力,我们在 Vsync 时进行 GC挂起,在 idle时进行 GC恢复。具体效果如下图:
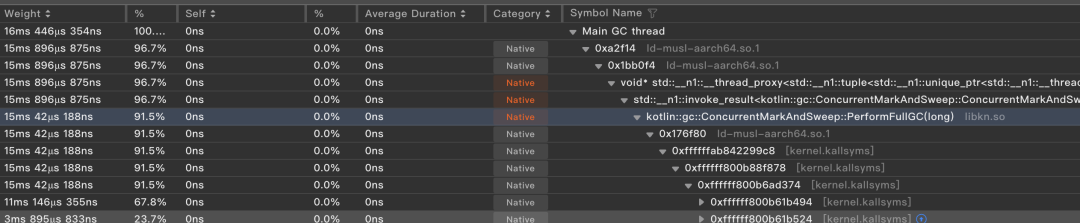
Sweep 优化
Kotlin Native GC 在Sweep 阶段,会有大量的munmap系统调用,导致STW时间过长,从而影响主线程。为此,我们将munmap移出STW阶段,在STW阶段仅做Page收集。在Resume后再进行集中 munmap。将第二次 STW时间降低到 1ms以内。
2.5.2 KN堆Dump优化
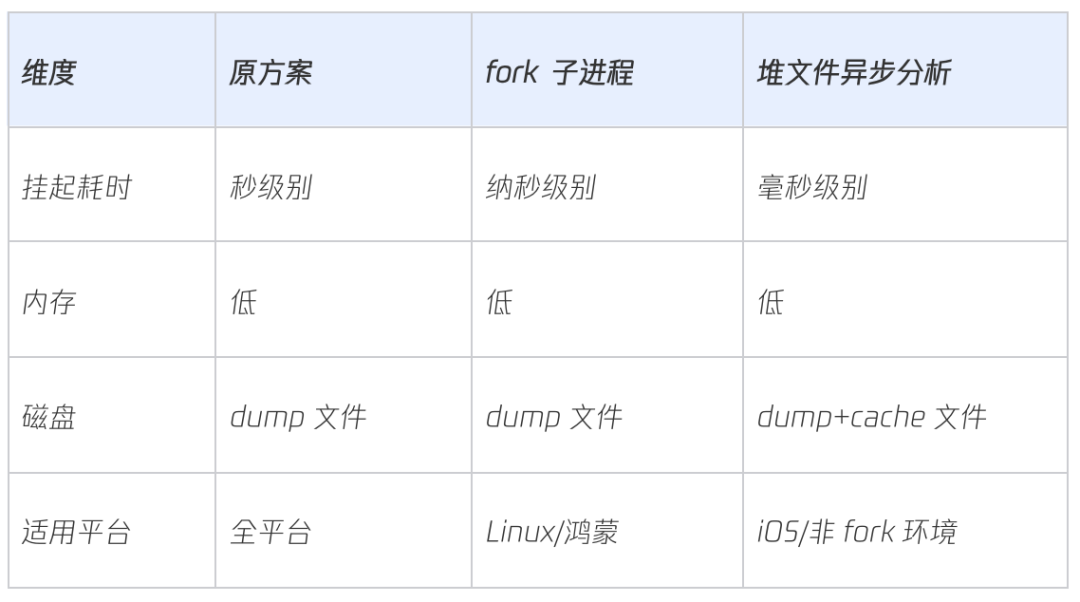
Kotlin Native(KN)支持生成堆内存转储文件,用于内存泄漏排查(类似 Android Profiler),但Dump过程需暂停所有KN线程,导致秒级界面冻结。针对不同平台特性我们采用了不同优化方案,从而达成线上可用的目标。
鸿蒙系统
基于 Linux 内核的 fork() 系统调用特性,采用「父进程无感知-子进程异步转储」方案实现零延迟内存快照。
iOS系统
针对iOS系统无法支持fork的限制,我们重新设计了堆内存分析流程,在保持性能的同时显著降低主线程阻塞时间。
堆冻结阶段:将堆内存数据保存到缓存文件,这里的堆内存是指 KN 堆用来分配对象内存的几种 Page 类,粒度很大,一种 Page 可能会有上千个对象,写文件时无需解析 Page 内容,所以耗时很少且不会因为对象数量的增加而显著增加耗时。
线程恢复后:异步地从缓存文件中读取对象内容并写到 Dump 文件,由于每次从文件读取的只是对象大小数据,所以内存消耗很低。
优化后450MB 堆内存转储耗时从 2.8 秒降低到 410 毫秒达到线上可用水平。该功能预计 6 月份上线。
方案对比
2.6 KuiklyBase组件生态
● Kotlin Native 堆栈还原组件
提供 Kotlin 异常堆栈还原,方便定义 Kotlin异常对应的Kotlin 代码行号、方法名等。
● Kotlin Native/ ArkTS 互调用组件
提供 ArkTS 与 Kotlin Native 跨语言访问场景的解决方案,支持基础类型、闭包、ArrayBuffer等类型互转,统一的生命周期管理,支持跨线程同步调用,支持跨Runtime的服务发现,为开发者提供简便的跨语言互调用能力。
● 资源管理组件
本项目基于Kotlin Multiplatform技术,构建了一套跨平台原生资源管理解决方案,支持Android、iOS及HarmonyOS三大移动端平台。通过构建时同步生成类型安全的资源访问类(Resource Class),结合Kotlin/Native(klib)/ Kotlin/Jvm(aar)的标准化资源封装机制,实现了多平台资源统一管理与编译期强校验,为开发者提供与Android R类相仿的资源调用体验。
● 原子操作组件
基于Kotlin 官方提供的多平台原子操作库,旨在以高效且符合 Kotlin 惯用语法的方式实现线程安全的并发编程,提供轻量级的原子类型(如 AtomicInt、AtomicReference),支持原子读写、CAS(Compare-And-Swap)等操作,无需显式锁即可实现线程安全。
● 协程组件
基于Kotlin 官方提供的协程库,旨在简化异步和并发编程,通过轻量级协程替代传统线程和回调机制。支持协程构建器、调度器、挂起函数、结构化并发、流处理、通信与同步、异常处理、超时控制等能力。
● 序列化组件
基于Kotlin 官方提供的多平台序列化库。专为 Kotlin 语言设计,支持高效、类型安全的对象序列化与反序列化。多格式支持、编译器插件集成、兼容Kotlin类型安全与空安全。支持嵌套对象、泛型类、密封类(sealed class)等复杂类型。
● 日期时间处理库
基于 Kotlin 官方提供的多平台日期时间处理库,简化跨平台的日期和时间操作。支持时区处理、时间运算。
● IO库
基于 Square 提供的高效 I/O 库,旨在简化输入输出操作。提供高效缓冲区管理、同一流抽象、智能数据移动。
● 不可变集合库
基于 Kotlin 官方提供的不可变集合库,专注于为开发提供线程安全、高效且符合函数式编程范式的数据结构。提供不可变的集合接口,确保集合创建后不可修改,避免意外数据变更。
● 并发集合库
基于StatelyConcurrency提供的并发集合库,简化跨平台开发中的状态管理和并发控制设计。支持线程安全集合、并发控制、同步机制。针对针对 Kotlin/Native 的严格内存模型优化,减少线程切换开销。简化状态管理。
● Lottie动画库
基于 Airbnb 开源的跨平台动画渲染库,能够将 Adobe After Effects 设计的动画转换为轻量级 JSON 文件,并在多平台上高效渲染。提供丰富的动画控制、动态属性修改、轻量高效。
● PAG 动画流解决方案
腾讯开源的一套跨平台动画工作流解决方案,专注于将 Adobe After Effects (AE) 动画高效转换为轻量级文件,并在多终端渲染。支持AE动画无缝导出、运行时编辑、高性能渲染、配套工具链完善。
● 数据库
基于 SQLite 封装的轻量级、嵌入式的关系型数据库,嵌入式设计、标准SQL支持、事务与ACID合规。轻量高效、弱类型系统、并且支持高级功能扩展(索引、触发器、视图等)
● 工具库
屏蔽Android/iOS/Harmony系统平台差异,对外部统一提供常用的工具api集合作为业务开发的强力支撑。包括不限于 App信息管理(名称、版本号、安装时间、更新时间、包名等)、设备信息管理(设备类型、品牌、制造商、系统版本、电池状态、亮度、内存信息等)、屏幕信息管理(宽度、高度、分辨率、是否亮屏、锁屏、屏幕旋转、状态栏、安全区域获取、全屏模式等)、传感器管理(重力、震动、陀螺仪、加速度)、前后台状态管理、音频及音频焦点管理、加解密管理(3DES、RSA、AES)、字符编码(UTF-8、UTF-16、BASE64)、存储空间管理、网络状态监听、沙盒目录获取、监听分屏/浮窗等状态、图片保存相册能力。
● 网络库
提供基于HTTP协议的POST、GET请求能力以及关键信息采集。

3. 实现原理
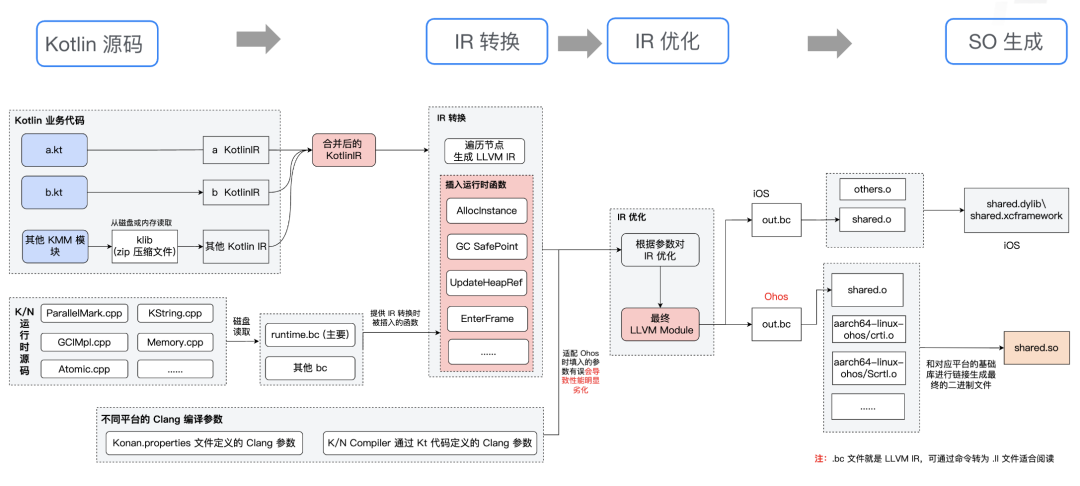
3.1 KN鸿蒙平台适配
kotlin 1.9 使用的LLVM 11,kotlin 2.1升级到LLVM 16,但是鸿蒙平台能够支持的版本在LLVM 12 ~ 15,苹果和鸿蒙都是基于公共版本的LLVM进行修改,增加了自己的特性优化,苹果相对好的点在于公共版本的LLVM中包含有苹果的target,所以鸿蒙版本的LLVM既可以支持iOS,又可以支持鸿蒙平台。(KukilyBase-Kotlin当前基于2.0.21进行鸿蒙适配)
● 常规方案:常规的Kotlin适配思路是分别使用鸿蒙和苹果的LLVM进行编译,这种方案的好处是修改简单,且不存在兼容性问题。缺点是由于Kotlin本身不支持多llvm架构,导致鸿蒙平台的kotlin和iOS平台要进行分别编译,需要依赖不同的Kotlin版本。
● KuiklyBase方案:在第一步Kotlin IR转LLVM IR时采用苹果的LLVM 11,在LLVM IR生成可执行文件时使用鸿蒙的LLVM 12,这样既可以满足诉求,Kotlin本身也无需进行架构调整。
3.2 KN性能优化
完成适配后,我们发现卡顿情况非常严重,从而进一步对Kotlin-Native性能进行评估,我们采用了官方Benchmark进行对比,测试发现鸿蒙耗时是iOS相同性能机器的2.48倍。
我们需要针对鸿蒙平台进行一系列的优化,经过初步分析,我们也规划了性能优化的初步优化思路。
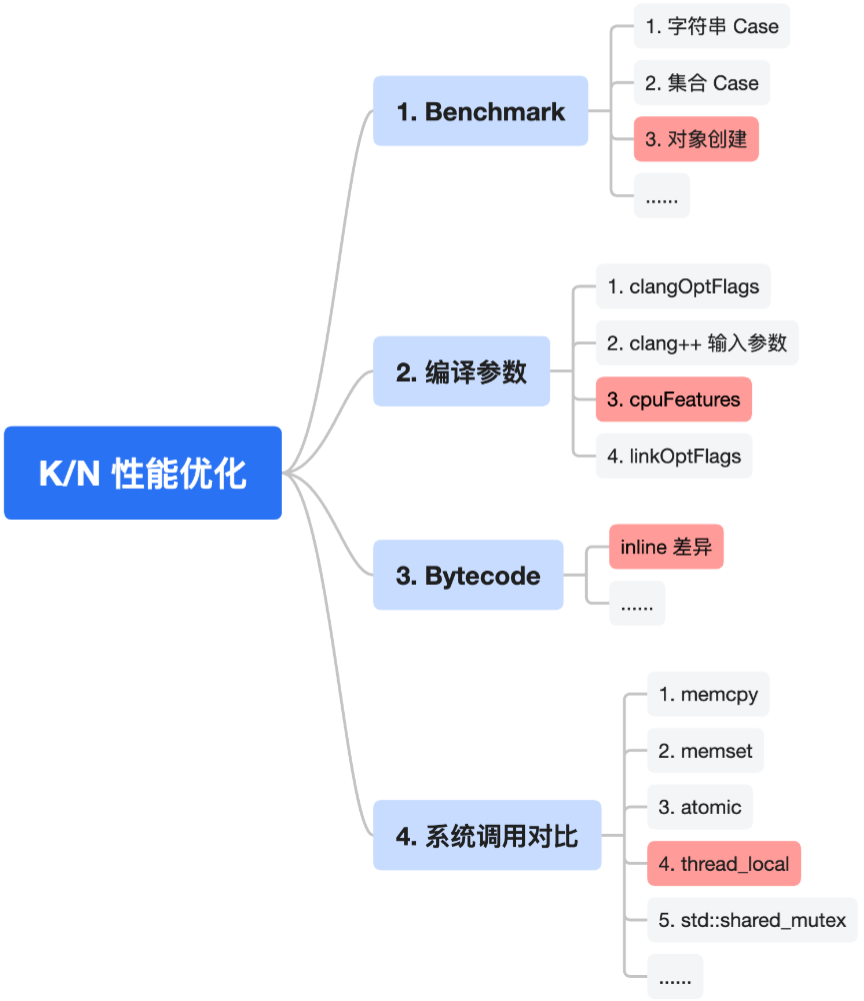
3.2.1 内联优化
我们分别对比了相同benchmark生成的Kotlin IR、LLVM IR文件。发现LLVM IR在内敛上更加充分,特别是对于关键函数,例如EnterFrame等,反观鸿蒙平台此类优化更少有。
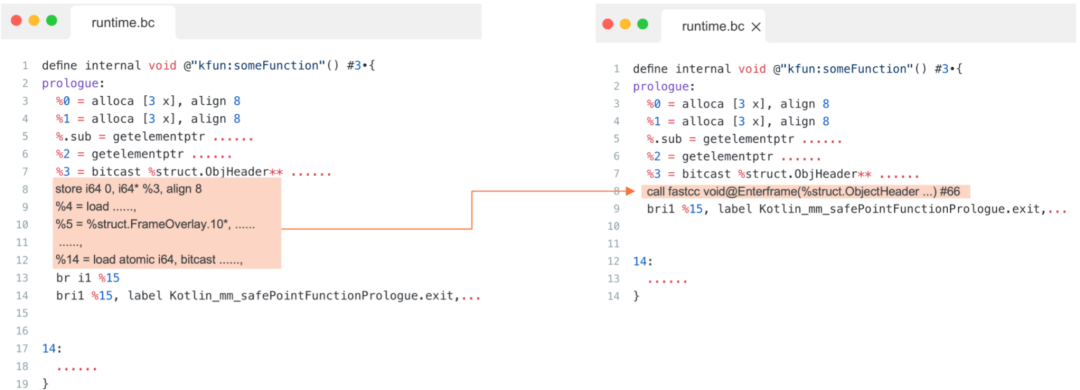
尝试添加always inline后,发现程序性能得到了较为显著的影响。但相对iOS仍然有一定差距。通过分析LLVM的内联 pass 发现,在处理 EnterFame等函数时,会对比cpu feature的兼容性,Kotlin和框架内部C++代码在生成LLVM的函数时,他们各自携带的cpu feature不一致,导致无法进行内联。配置正确的属性后,此问题得到修复。
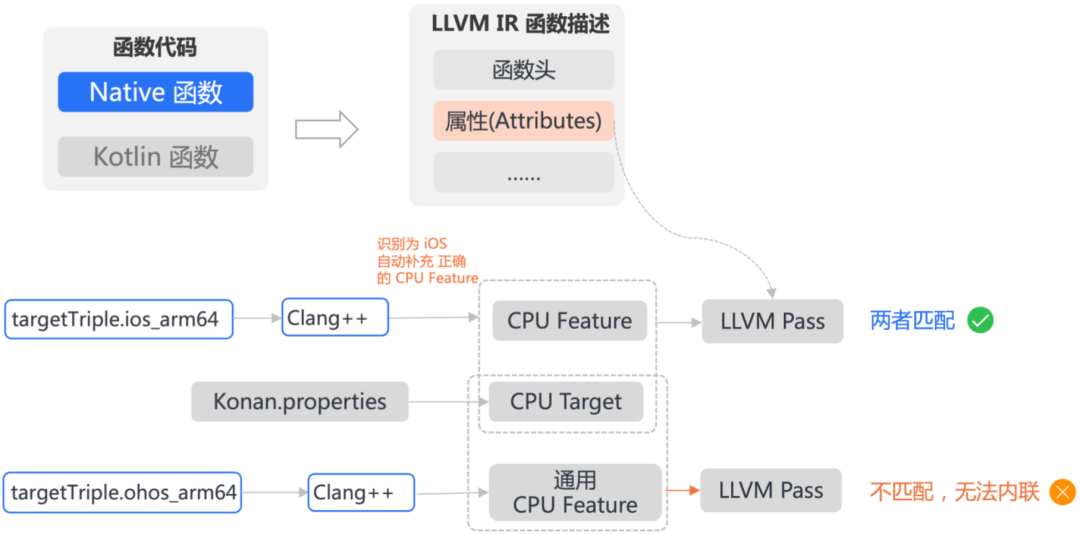
3.2.2 ThreadLocal引发的性能低
通过对 Benchmark 中耗时超 iOS 的 case 进行深度分析,最终发现如下高频堆栈。线程私有数据的性能测试结果表明 Ohos 耗时波动较大。Ohos 耗时是 iOS 的 2-3 倍。(展示0ns是由于初期鸿蒙trace工具不完善导致,现已修复)
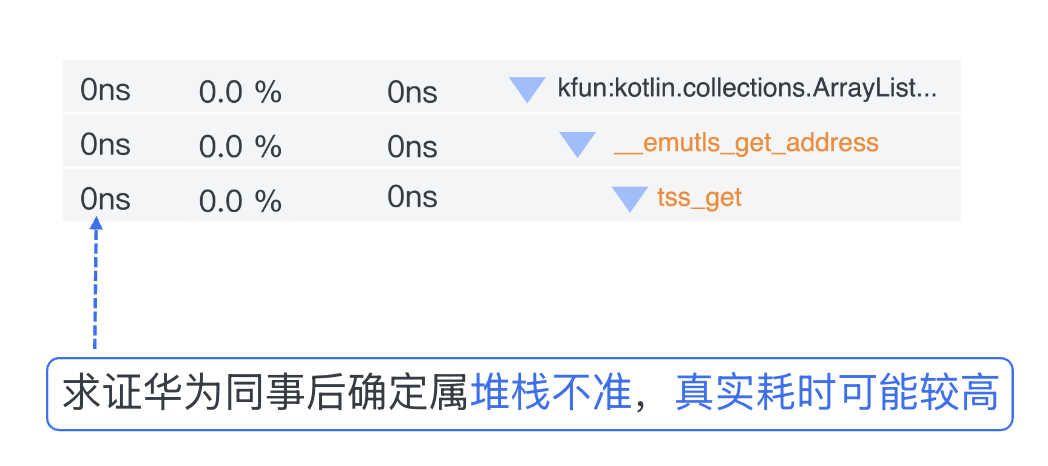
由于Kotlin-Native在内存分配时都依赖ThreadLocal来访问线程独立的Page,固访问频率极高,导致性能低下。分析发现鸿蒙平台默认采用了软件模拟的thread_local。所以我们在编译时通过参数强制使用硬件thread_local,整体性能提升了30%。
3.2.3 协程性能优化
将 JetBrains 的 Compose 成功适配到 Ohos 后,长列表的滑动过程中频繁出现卡顿现象。trace分析发现异常的处理花费了大量的时间。
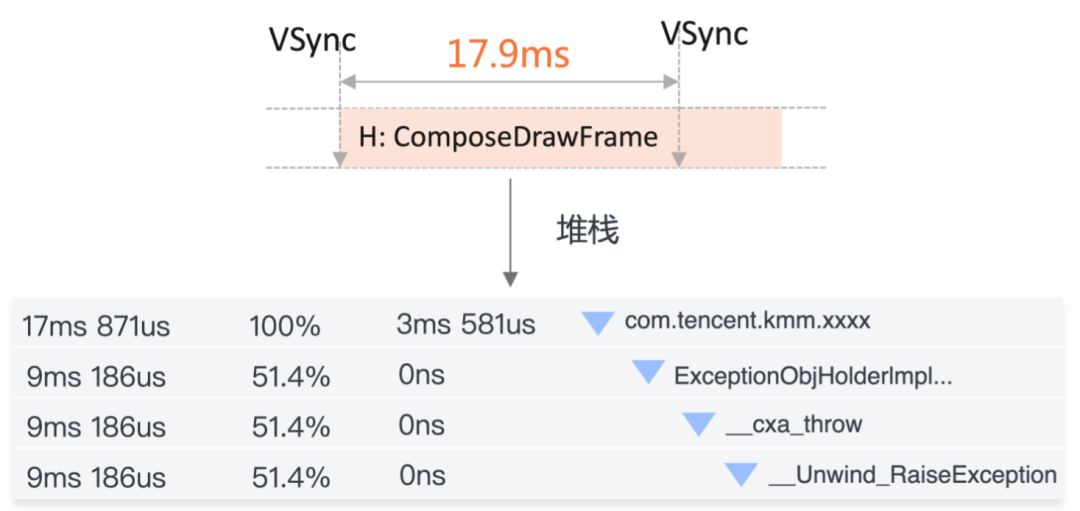
经技术架构分析,Compose Multiplatform 框架的协程调度机制深度依赖异常处理模型实现任务恢复与取消控制。其底层实现中,KN运行时将异常处理桥接至C++异常体系,该设计在运行时会产生显著性能损耗:当异常触发时,系统需沿调用栈进行逐级回溯以定位匹配的异常捕获点,其时间复杂度与调用栈深度呈正相关。更值得注意的是,该过程伴随大量C++异常对象的动态构建与析构操作,频繁的内存分配与释放行为进一步加剧了执行时延,导致关键路径上的协程调度效率受限于异常处理机制的性能瓶颈。
同时鸿蒙系统libhilog.so捕获了抛出的异常进行处理,造成了大量延迟,与鸿蒙专家沟通后得到妥善优化。最终长列表在滑动场景能够稳定在120Hz,处理方式如下:
● 缓存或放弃部分关键位置的异常,降低异常处理的耗时与频率。
● 解决libhilog.so系统库对于异常的非法捕获。
3.2.4 调试性能优化
使用 JetBrains 的 Kotlin Native debuging 脚本后,调试断点及打印变量耗时远超 Native 。通过trace分析发现其 KDS 与 LLDB 交互极为原始和简单。
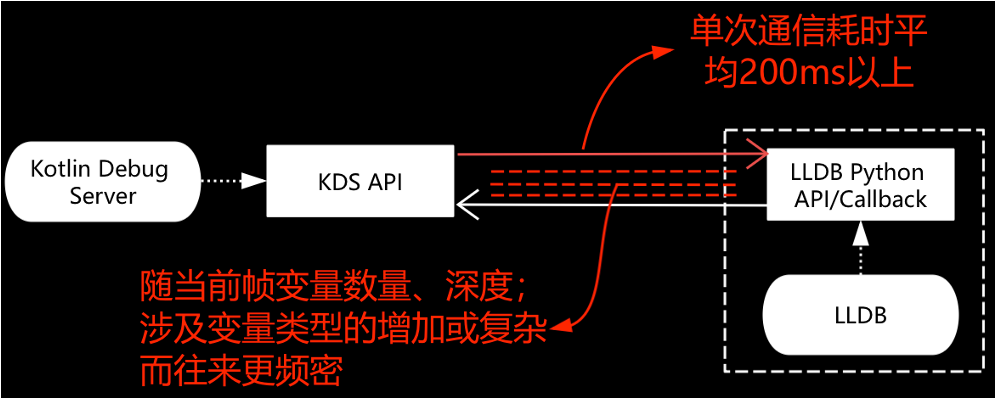
经技术架构分析与处理,在 KDS 与 LLDB 上运用流程合并、复用、缓存、预加载潜在下一跳、局部调试的可容错优化等手段提高其通信和处理效率。整体性能视实际情况提升数倍至几十倍(提升幅度随调试栈的变量加密加深等因素影响),近似 Native。
3.3 鸿蒙绘制不同步问题解决
由于两种组件属于独立的绘制层,在鸿蒙系统中存在不同步的问题。整体效果如图,Compose的列表混排ArkUI的元素进行滚动,两个同步向上进行运动,由于不同步,UI衔接处会展现出空白区域,出现割裂的现象。
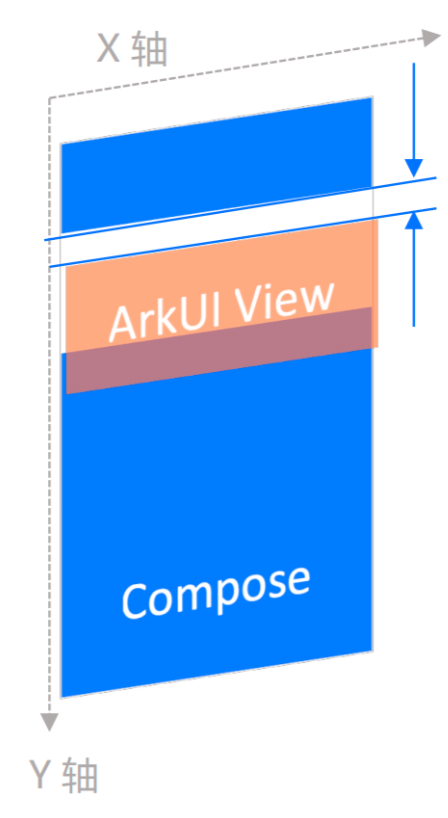
核心问题时鸿蒙采用的是集中渲染架构,XComponent的独立绘制模式与ArkUI的绘制发生在不同的进程,无法保证完全不同。所以我们采用XComponent的Texture模式,将内容绘制到FBO中,由FBO参与原有的ArkUI的绘制节奏,来保证完全的同步。
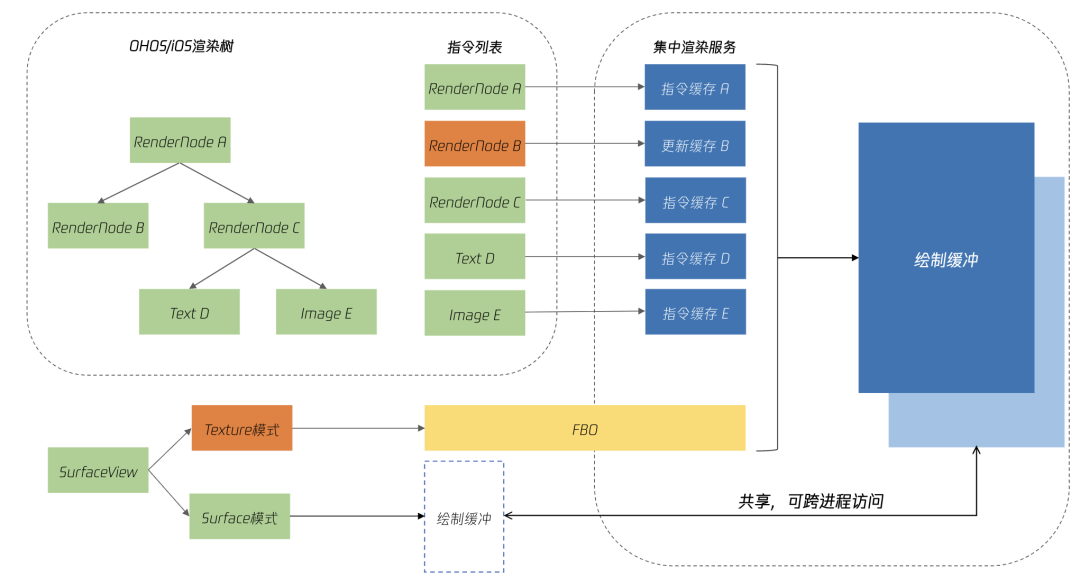
3.4 iOS多模态渲染
在基于 UIKit 进行渲染的基础思路上,我们也发现了如 CALayer 重叠、未正确放置、无法复用等问题。对于Android来说,其是独立绘制架构,每个进程自己完成内容的绘制,所以画布是一整块,内容都绘制在其中,通过Skia的PictureRecorder命令录制功能进行命令的快速回放。但这种模式在iOS集中渲染架构上就不太适用了,需要有一个工具来进行差量处理绘制命令。所以我们设计了基于iOS的PictureRecorder局部更新架构。
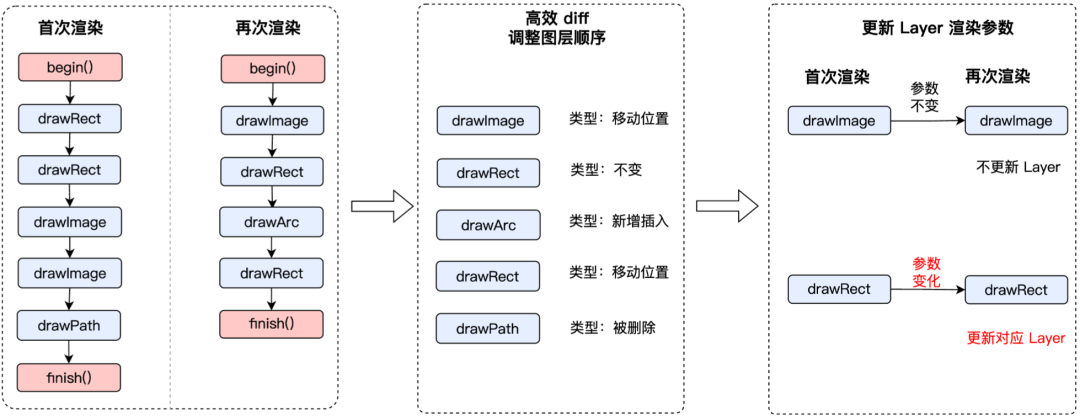
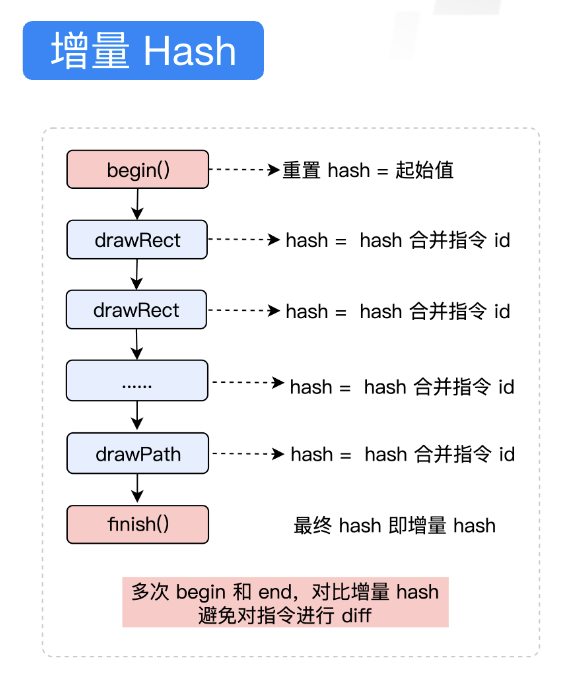
在PictureRecorder中,我们对绘制命令进行差量,只更新变化的部分,从而提升绘制效率。PictureRecorder核心就是我们通过hash来判断绘制指令是否发生变化,常规的这种方式能够提升绘制效率,但当页面无比复杂时,hash计算偶尔也会变成一种负担。
PictureRecorder进行了进一步升级
我们优化的核心思路是,通过增量hash来减少hash的计算量。每一个 draw 函数执行的时候,都会对将当前的 hash 和 指令id 进行一次合并。并计算出最终的 hash。这个 hash 记录了一次完整的使用。增量 hash 的目的是减少 diff操作,这种方式可以有效地减少,两次指令相同的比较。在压力测试中还发现 OC 对象的创建和释放耗时也会被放大。这种情况在腾讯视频复杂页面回迁的过程中尤其明显,因此,这里还将原先由 OC 对象代表的指令,改为了非常简单的 C 结构体。之前的OC 闭包也去掉了。
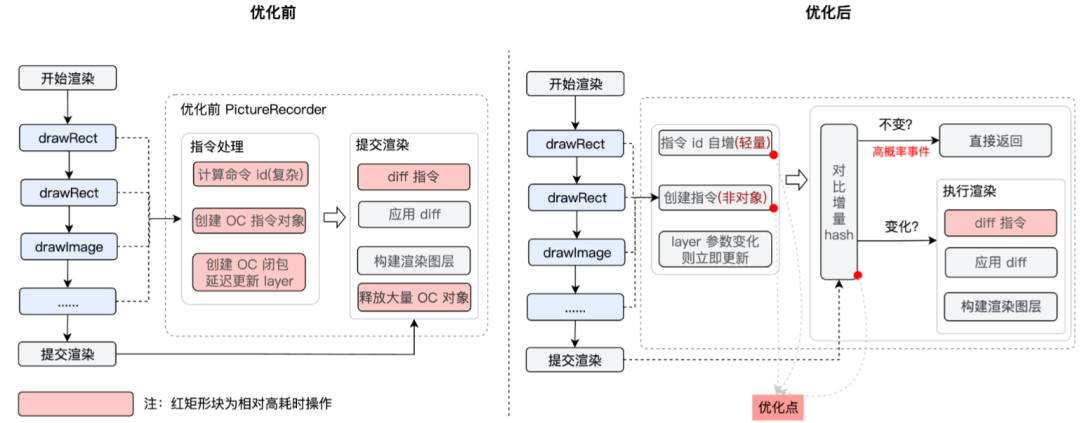
优化效果:以腾讯视频的视频播放页面为例,首次渲染耗时降低13%,再次渲染耗时降低56%。
3.5 与KuiklyUI的差异
跨端框架自渲染与原生渲染在性能表现与多端适配层面各具优势。为满足业务场景的差异化需求,腾讯大前端Oteam同时进行两个方案探索。
● 原生渲染方案 KuiklyUI:侧重于静态化+动态化双运行模式,采用轻量原生渲染保持原生UI体验并具备高度一致性,并基于原生组件映射的方式支持Compose API(本次已同步推出),支持H5和小程序(6月底推出)。
● 自渲染方案 ovCompose:专注于全面对齐 Compose Multiplatform 标准API,采用自渲染方式实现鸿蒙平台的适配,确保三端高度一致性。针对 iOS 上较多的存量业务,提出了多模态渲染方案解决低端iPhone内存紧张、混排原生视图、手势等问题。

4. 开源说明
此次开源共包含5个仓库,包含了ovCompose和KuiklyBase。仓库Group地址为:https://github.com/Tencent-TDS


5. 计划
随着这几年的快速发展,KMM生态得到了长足的发展,Kotlin-Native的执行性能在很多方面已经超越了Kotlin-JVM,但目前 Compose Multiplatform 跨平台技术还没有达到成熟的状态(特别是GC),ovCompose & KuiklyBase将持续优化,为开发者带来体验更好、性能更强的跨端开发体验。以下是我们重点优化的方向:
● GC在业务场景的表现
● Kotlin-Native组件化
● Kotlin-Native的开发体验优化
● UIKit渲染模式进一步对齐Skia 的渲染


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









