







为什么要做分布式
Jmeter 本身的局限性
- 一台压力机的 Jmeter 默认最大支持 1000 左右的并发用户数(线程数),再大的话,容易造成卡顿、无响应等情况,这是受限于 Jmeter 其本身的机制和硬件配置(内存、CPU等)
- 由于 Jmeter 是 Java 应用,对 CPU 和内存的消耗较大,在需要模拟大量并发用户数时,单机很容易出现 JAVA 内存溢出的错误,导致测试脚本本身就有瓶颈
JVM 堆内存的局限性
Java 应用的 jvm 堆内存 heap 受压力机硬件限制,虽然我们可以调整堆内存大小
cmd 启用 Jmeter GUI 时,也会有提示
increase Java Heap to meet your test requirements: Modify current env variable HEAP="-Xms1g -Xmx1g -XX:MaxMetaspaceSize=256m" in the jmeter batch file
翻译:增加 Java 堆内存来满足测试的要求
但是单机无法支撑数以万计大并发,此时,需要多个压力机进行分布式压力测试,这样性能瓶颈就不会是我们的压力机了
联想场景
- 测试 5000 并发的场景,但单机只能支持 1000 并发无法达到 5000
- 通过分布式(5 台机器起)可以模拟 5000 并发
分布式压测
Jmeter 支持分布式压测,将需要模拟的大量并发用户数分发到多台压力机,使 Jmeter 拥有更大的负载量,满足真实业务场景(高并发场景)
分布式的最终目的
- 确保压力机不会出现性能瓶颈
- 在后面进行性能分析时,不需要考虑压力机是否会导致性能瓶颈的主要原因之一
分布式原理
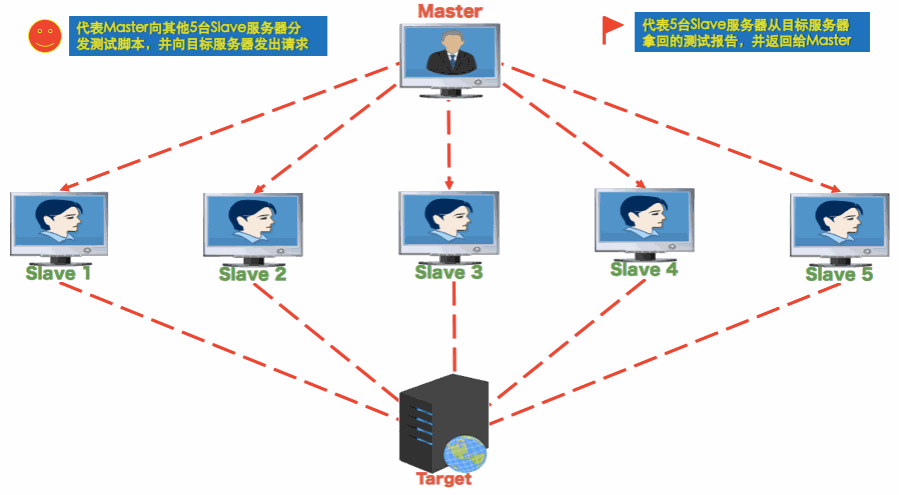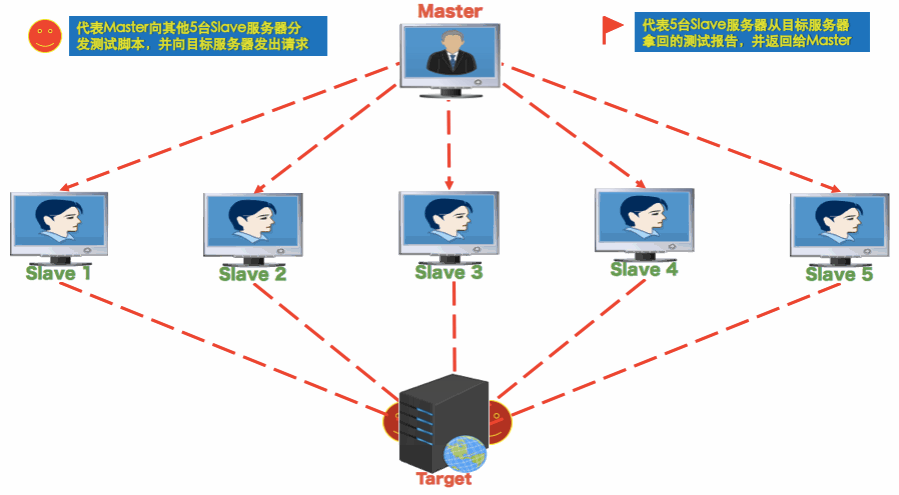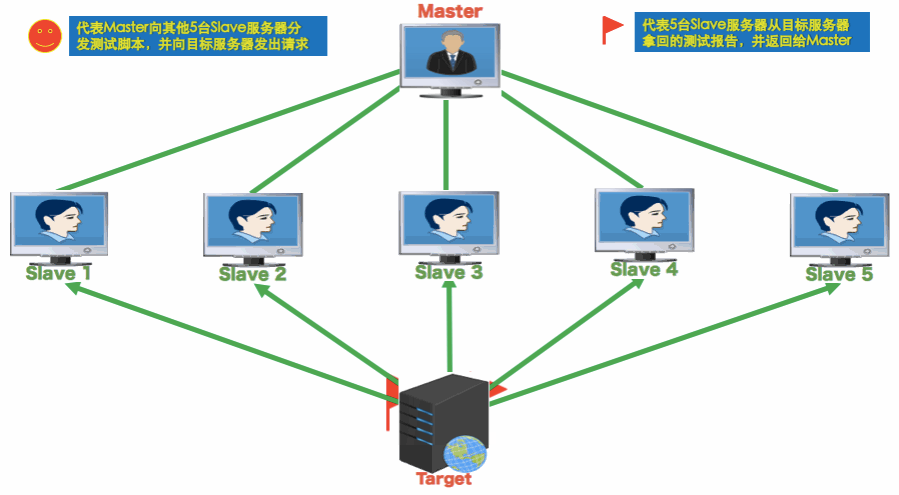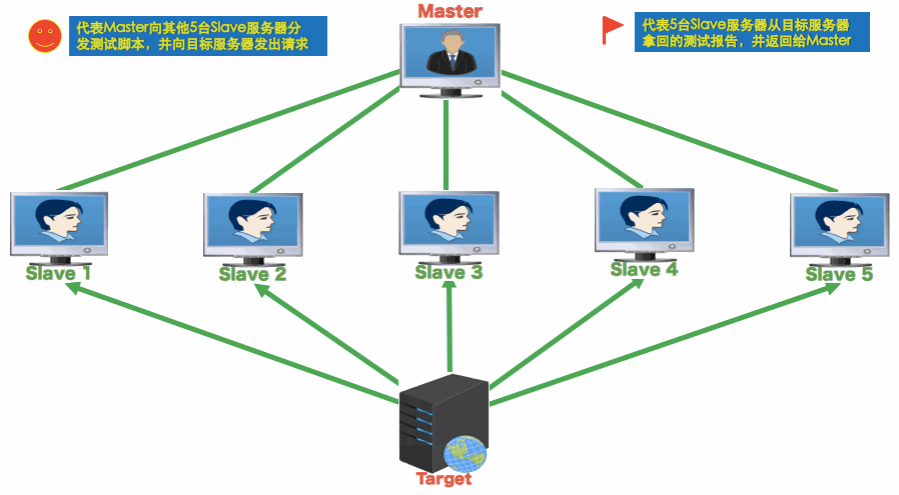
把上面的动图完整看完,就懂了,原理如下:
- Master 是控制机,Slaves 是多个压力机,Target 是被测系统
- 分布式测试中,Master 通过命令行将测试脚本分发给所有 Slave
- Slave 不需要启动 Jmeter GUI,通过 CLI 模式执行测试
- Slave 执行完后,会把结果回传给 Master
- Master 收集所有 Slave 的结果并汇总成一个结果集
注意
- 压力机也可以叫:负载机、代理机、执行机、奴隶机、肉鸡....各种各样的名字,但他们都是 Slave
- Master 也可以执行测试脚本,也可以不执行只负责管理
场景类比
- 一个测试部门有一个部门经理,五个测试小弟
- 有个巨型测试任务由部门经理划分好模块后分发给五个测试小弟去测试
- 五个小弟测试完,会各自发送测试报告给部门经理
- 部门经理把所有测试报告汇总成一份,发给公司大佬看
- 而部门经理可以参与测试,也可以不参与测试只负责管理部门
分布式专用术语认知
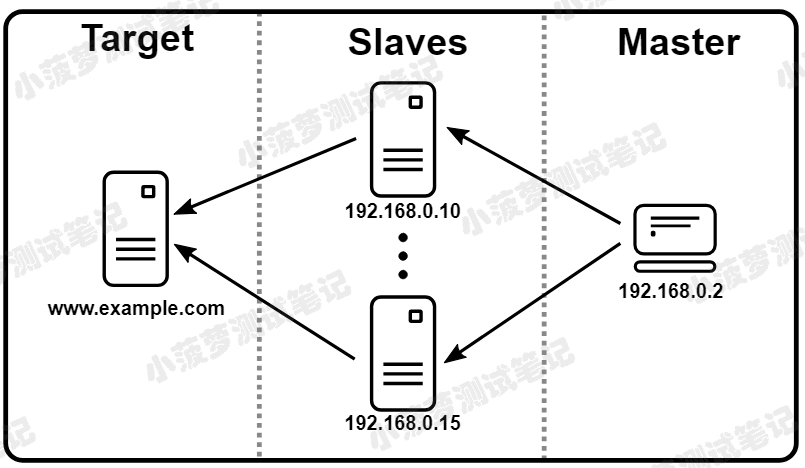
Master
- 控制机
- 运行JMeter GUI(控制测试)的机器
Slave
- 压力机
- 运行 jmeter-server 的机器
- 它从 GUI 接收命令并将请求发送到目标系统
target
需要进行压力测试的 Web 服务器
实现分布式的前提条件
控制机和压力机的 jmeter 要一致
具体体现在
- jmeter 版本要一致
- jdk 主版本要一致(1.7、1.8...)
- jmeter 脚本中,csv 文件要一致
- jmeter 的插件要一致
- 同一局域网,防火墙开放端口
jdk 版本一致
看主版本即可

csv 文件一致
主要是数据和路径要一致
如何保持一致可以参考这篇博客:https://www.cnblogs.com/poloyy/p/13189198.html
保证一致性方法
直接将控制机的 jmeter 压缩包移到每个压力机上解压使用
压力机配置
注意:压力机系统不限,可以是win、mac、linux
前置步骤
将控制机的 jmeter 压缩包发送到压力机,解压
修改 jmeter.properties(下面三步走)
进入 bin 目录
修改 server_port 端口
默认1009
可修改任意端口,但不能已被占用的哦

修改 server.rmi.port 端口
和 server_port 保持一致即可, 默认是会帮你保持一致的

设置 server.rmi.ssl.disable
默认 false,代表需要认证
设置为 true,减少不必要的麻烦

启动 jmeter-server 服务
仍然在 bin 目录下哦
如果压力机是 linux 或 mac
./jmeter-server -Djava.rmi.server.hostname=压力机ip
如果是window
jmeter-server.bat -Djava.rmi.server.hostname=压力机ip
检查防火墙
- 检查防火墙是否被关闭,防火墙会影响脚本执行和测试结构收集
- 确认 server_port 的端口没有被占用以及需要对外开放,端口占用会导致压力机报错
- 关于开放端口和关闭防火墙可以参考这篇博客:https://www.cnblogs.com/poloyy/p/12213297.html
控制机配置
修改 jmeter.properties(下面三步走)
修改 remote_hosts

- 多个压力机之间用 , 隔开
- 不同压力机端口可以不一样,不需要全部都一致
- 如果控制机也测试则加 127.0.0.1:port ,然后修改 server_port 和 server.rmi.port (和压力机一样步骤)
设置 server.rmi.ssl.disable

设置 mode
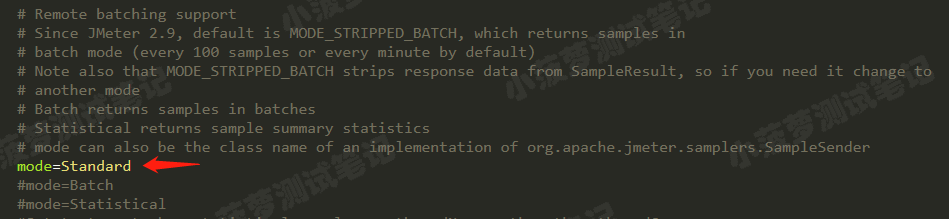
- 用于查看分布式测试过程中,每个压力机的测试结果
- 若不启用,在运行过程中,控制器是无法实时看到压力机的结果
控制机运行分布式测试
启动远程服务器
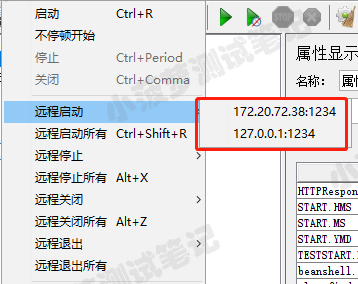
这里会显示所有 remote_hosts 添加的压力机
点击启动后,查看压力机

分布式注意事项
- 如果并发较高,建议将控制机设置为只启动测试脚本和收集汇总测试结果
- 分布式测试中,如果 1S 发送 100 个模拟请求,有 5 个压力机,那么需要将脚本的线程数设置为 20,否则模拟请求数会变成 500,和预期结果相差太大
- 只需要修改控制机的脚本,启动压力机之后,压力机执行的就是最新的脚本
具体栗子
针对注意事项二,我们来看看栗子
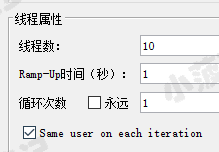
设置了 10 个线程
启动两台压力机的测试结果
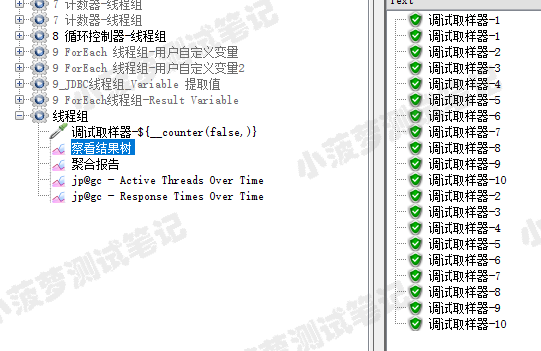
一共发出了 20 个请求(10*2)
其实这就是分布式的好处,如果需要 1000 个并发用户数,有 10 台压力机,每台压力机只需要满足 100 个并发用户数即可
分布式已知局限性
- 若没有代理,RMI 不能跨子网通信,因此 JMeter 没有代理是不行的
- 从 2.9 版本开始,JMeter发送所有剥离了响应数据的结果到控制台,这使我们降低了网络IO的影响,确保监控你的网络流量,使得网络不是争议点
- 在 2-3 GHz 的 CPU 上,单个 JMeter 客户端根据测试的类型,可以处理 1000-2000的线程
分布式测试结果图表
分布式测试的前提
共有两个压力机:本机和另一台电脑的虚拟机
线程组结构树

一共有三个请求,三个监控结果图表
线程属性
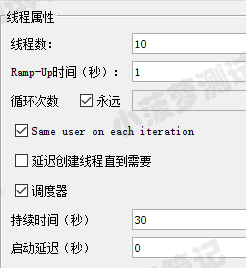
10 个线程,持续运行 30s
活跃线程图表

这里可以看到有两条线,分别代表两个压力机的活跃线程数,不是按照接口来分线哦
TPS 图表
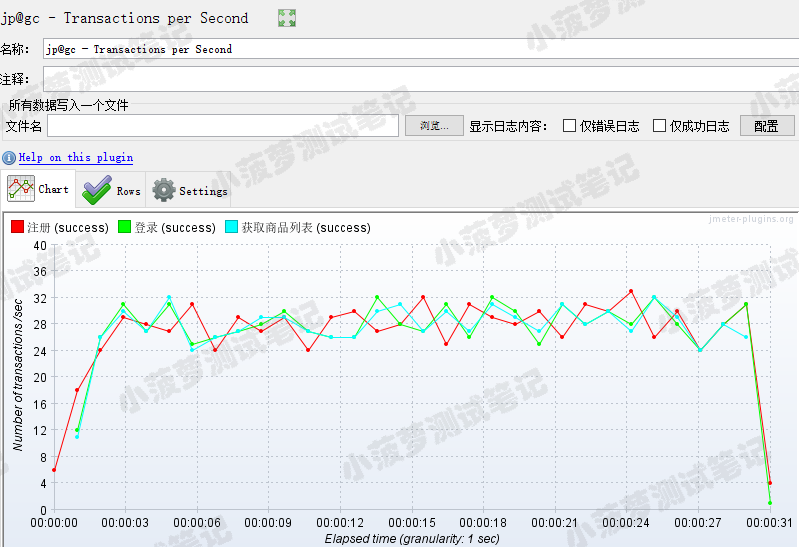
三条线代表三个接口的 TPS
是否有小伙伴有疑问,为什么这里不是按机器去分捏?
因为不同接口的 TPS 不可能相加的鸭!
响应时间图表
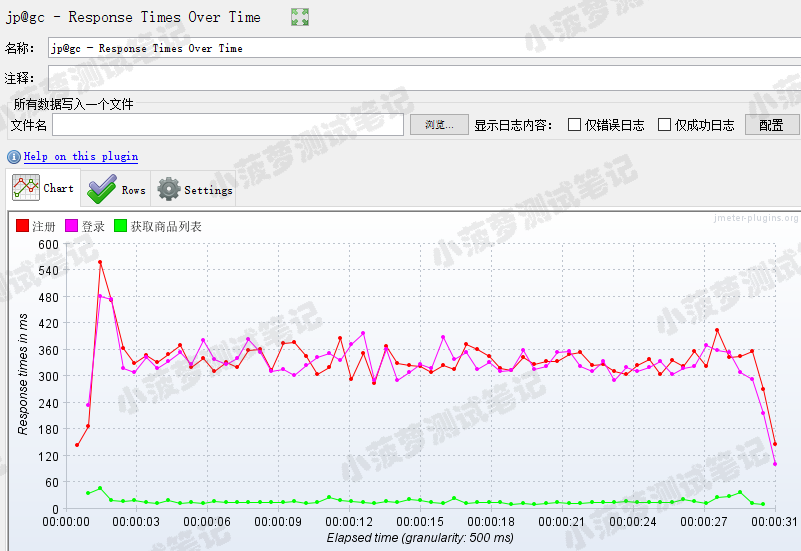
三条线的情况和 TPS 一样哦
分布式测试中可能会遇到的问题
缺少 rmi_keystore.jks
这就是上面有提到的证书问题
方式一
在 jmeter.properties 中设置 server.rmi.ssl.disable=true
方式二
在 bin 目录下,执行 create_create-rmi-keystore.sh
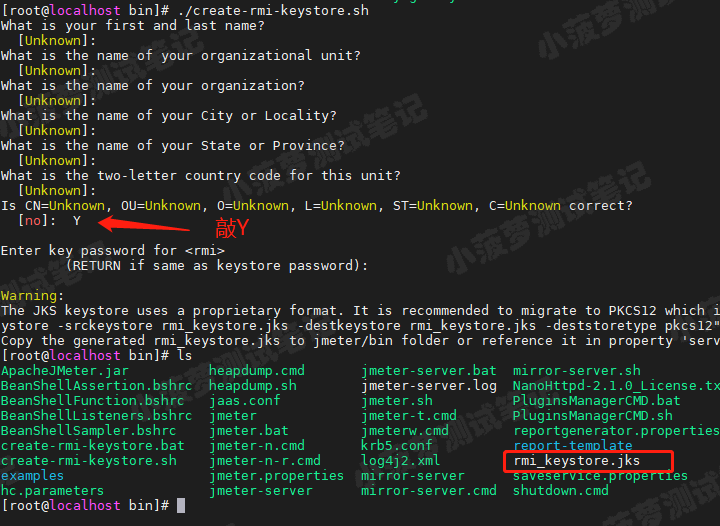
最后会在 bin 目录下生成一个证书
- 为什么要做分布式
- Jmeter 本身的局限性
- JVM 堆内存的局限性
- 联想场景
- 分布式压测
- 分布式的最终目的
- 分布式原理
- 注意
- 场景类比
- 分布式专用术语认知
- Master
- Slave
- target
- 实现分布式的前提条件
- 控制机和压力机的 jmeter 要一致
- jdk 版本一致
- csv 文件一致
- 保证一致性方法
- 压力机配置
- 前置步骤
- 修改 jmeter.properties(下面三步走)
- 修改 server_port 端口
- 修改 server.rmi.port 端口
- 设置 server.rmi.ssl.disable
- 启动 jmeter-server 服务
- 如果压力机是 linux 或 mac
- 如果是window
- 检查防火墙
- 控制机配置
- 修改 jmeter.properties(下面三步走)
- 修改 remote_hosts
- 设置 server.rmi.ssl.disable
- 设置 mode
- 控制机运行分布式测试
- 启动远程服务器
- 分布式注意事项
- 具体栗子
- 分布式已知局限性
- 分布式测试结果图表
- 分布式测试的前提
- 线程组结构树
- 线程属性
- 活跃线程图表
- TPS 图表
- 响应时间图表
- 分布式测试中可能会遇到的问题
- 缺少 rmi_keystore.jks
- 方式一
- 方式二















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









